-
-
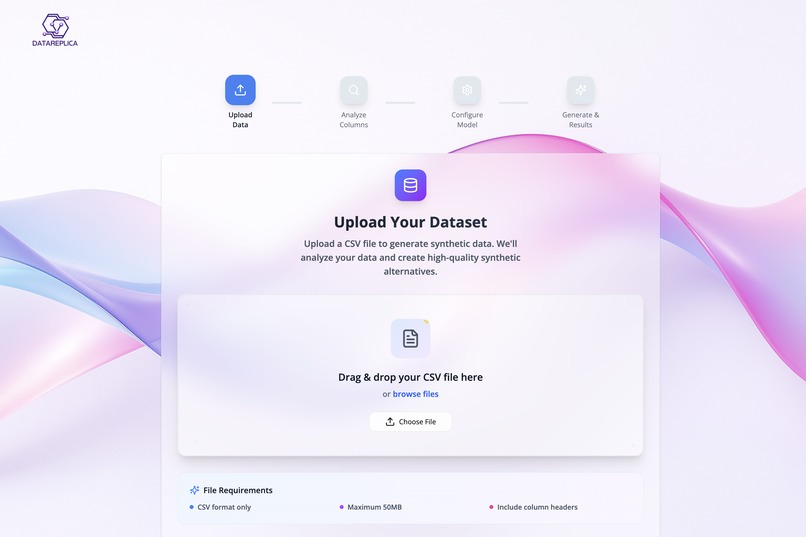
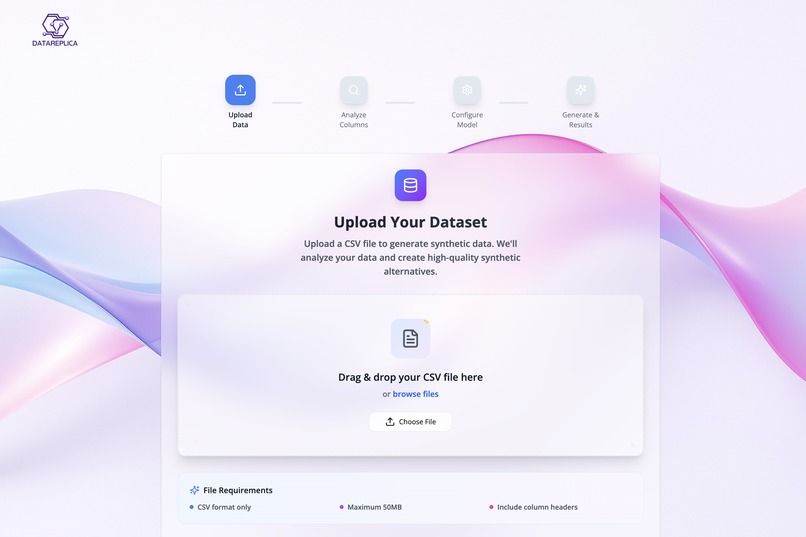
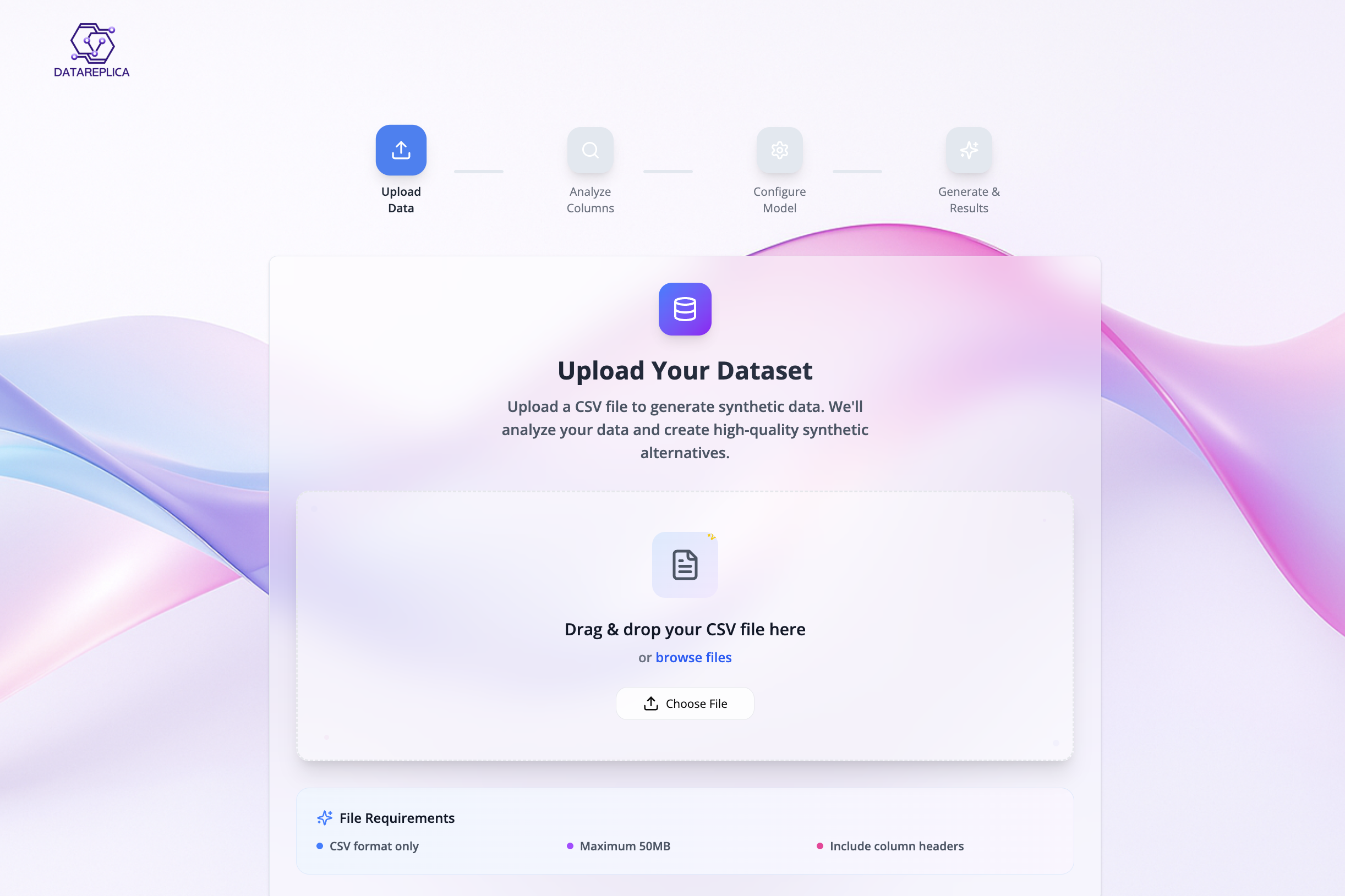
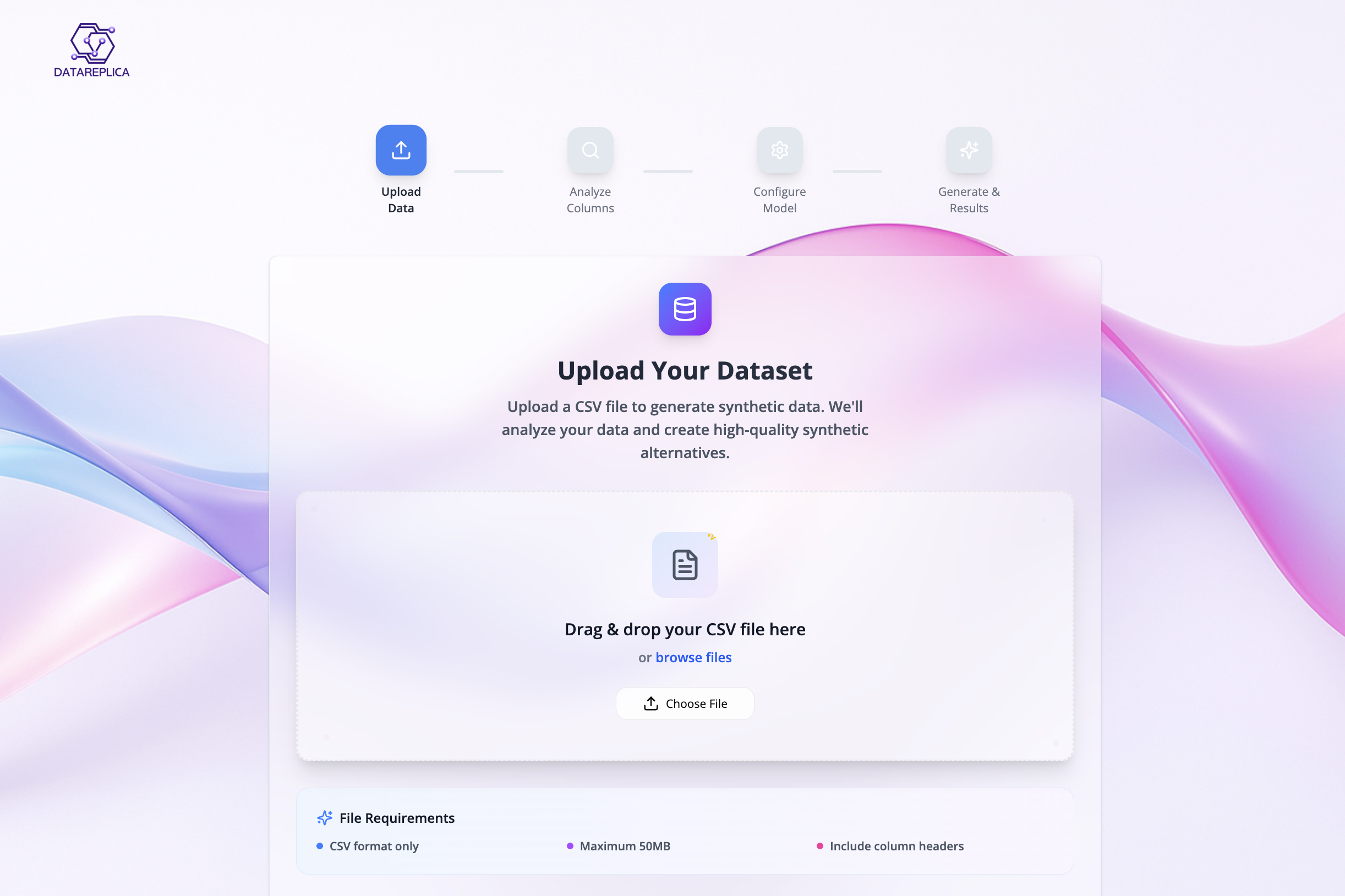
Drop Your Data. We’ll handle the rest!
-
Analysing, Learning, Creating... Generation in Progress.
Inspiration
Ever found the perfect ML idea but got stuck hunting for a clean dataset? We did — many times. That’s what sparked DataReplica: a tool that turns small data samples into large, high-quality synthetic datasets in minutes.
What it does
DataReplica lets users upload a small dataset and instantly generate a large, realistic synthetic version, along with optional data quality reports.
How we built it
-Frontend: React + Tailwind (Dockerized) -Backend: FastAPI with SDV models (CTGAN, TVAE, GaussianCopula, DistilGPT2) -Deployment: Docker Compose on AWS EC2 with Nginx reverse proxy
Challenges we ran into
-Real-world EC2 deployment and Nginx config for production -Time consuming text generation
Accomplishments that we're proud of
-Fully containerised and deployed ML app -Clean, multi-step user interface with instant feedback -Reliable synthetic data generation from minimal input -Automatic suitable model detection according to dataset
What we learned
-Support for multi-table and time-series datasets -Advanced quality metrics and drift detection
What's next for DataReplica
-Support for multi-table and time-series datasets -Advanced quality metrics and drift detection -Making it faster
Built With
- amazon-web-services
- docker
- fastapi
- huggingface
- python
- react
- sdv

Log in or sign up for Devpost to join the conversation.