-
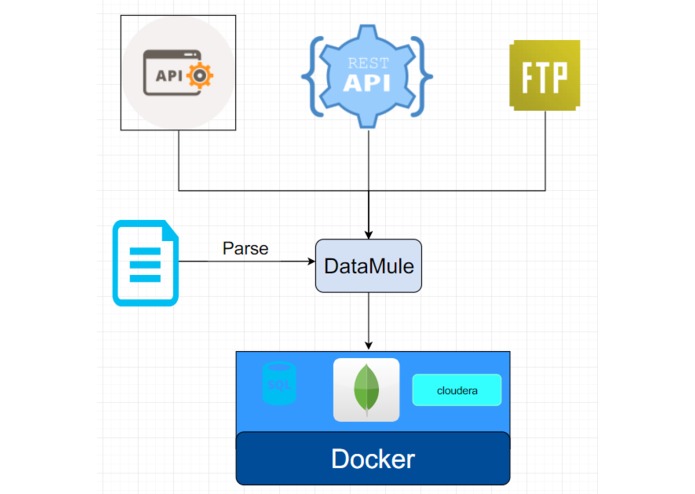
Application Diagram
Inspiration
As a data engineer for my day job in industry. I wanted to solve a problem that I see everyday. As the importance of data for analysis increases, easily attaining that data becomes more important. We see users run into the same issues they want some data, so they have to go read the documentation about how to obtain it. If they don't know the protocol or the industry standard. They have to learn before they can get to the data probaly write a script to get the data. Then if they want to load it into some datastore they need to write a script to load that data into the datastore. If you are in the industry there are some etl tools avaliable but they are pretty heavy and mostly do datastore to datastore.
We wanted to make it easier for users to get and put it into a datastore. If the datastore they want doesn't exist just make it for them. So we created datamule a data container.
The end user just has to tell us the dataset they want and the datastore they to put it in. They don't need know anything about where it came from or what it was before. Was it a rest api? Was it just a http request? Does it just live in some sftp? WHAT EVEN IS SOAP! WHO CARES.
What format was the data in json? csv? xml? Doesn't matter just put it into postgres for me.
datamule run nyu_catalog postgres
What it does
It grabs dataset from connectors specified in a input yaml file
How we built it
We built it with docker and pandas.
Challenges we ran into
Integrating with all technologies, merging codes from different teammates.
Accomplishments that we're proud of
It's useful and it can grow based on the community.
What we learned
Greg can't architect.
What's next for DataMule
Expand it and make it opensource so people can contribute.

Log in or sign up for Devpost to join the conversation.