-
-
Datamate
Inspiration
I have working with data for a long time and every time I have to do the same stuff with data writing repeatable code so I thought can I work with my data only by natural language free of writing repeated code , datamate is born out of that thought.
What it does
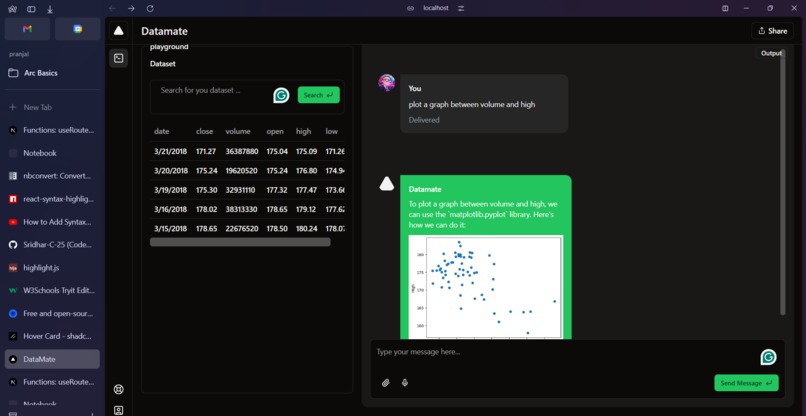
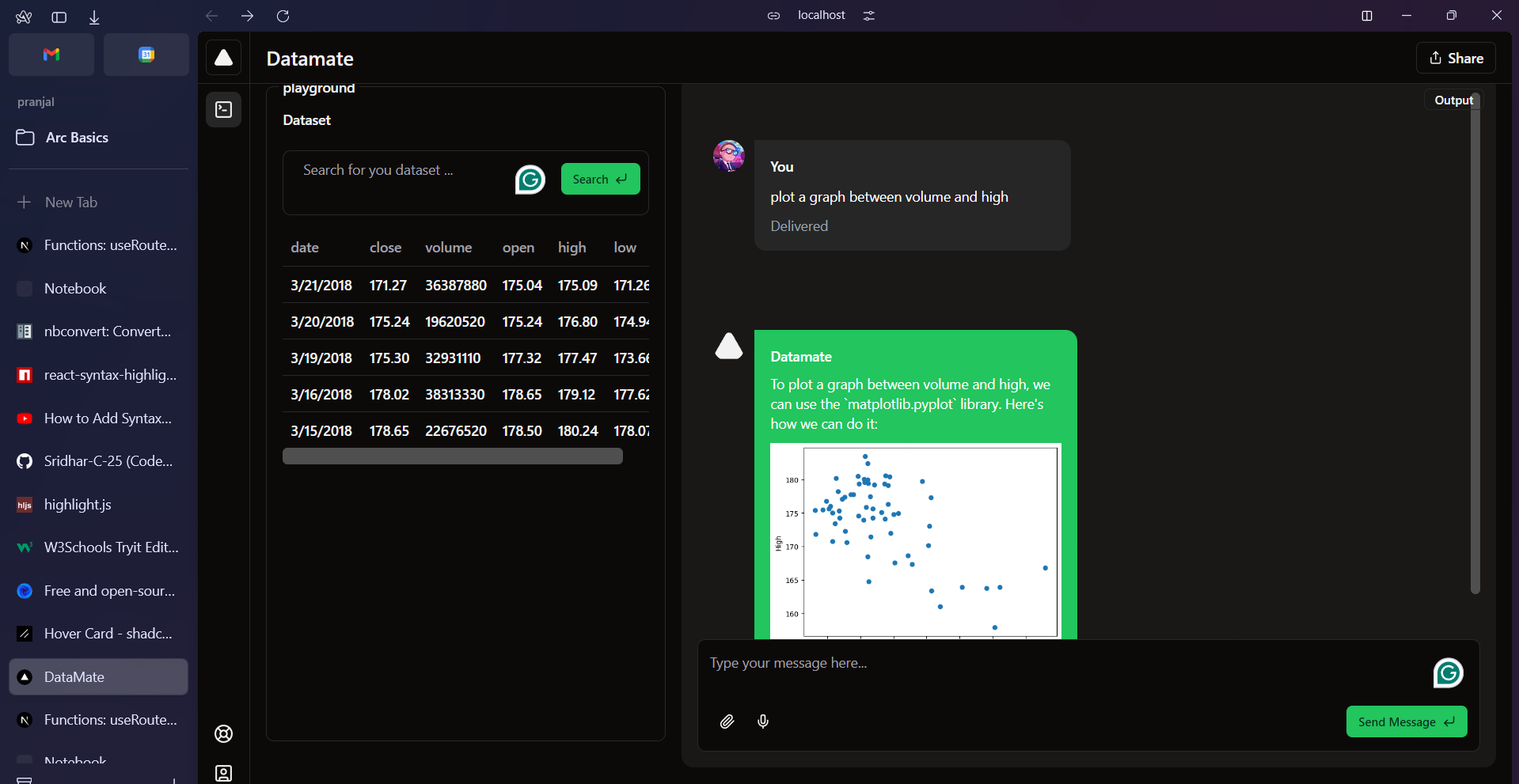
DataDM is a chatbot interface that lets a user talk to an AI assistant that writes code which is executed to answer data questions. Users can ask questions about doing data processing, feature engineering, data cleaning, question answering, visualizations, and even some data science modeling.
How we built it
We combined a bunch of technologies: Jupyter kernels (for background execution), Nextjs (for UI), Gemini-pro (for code generation and interpretation), and Gemini-pro-vision (for visualizing the data). For execution and analytics we rely on the great open source python data science stack (numpy, pandas, scikit-learn, matplotlib etc.)
First we got conversations working, then we added parsing for the code, and sending the code to the jupyter kernel in the background, then we parsed the info back and found ways to both send the results to the UI for rendering (Such as plots) but also representing it for the chatbot to "see" that the conversation has continued. We also added self-retries, where if the code raises an error, the AI will try to fix the error and code some more. Then lastly we added search for datasets from github, since in using it, the first thing we found ourselves doing every time was finding CSVs online.
Challenges we ran into
Getting the clear code output and text output and image output and handling it sending to the client Implementing the interpreter code Working with jupyter kernels how we can programmatically run the cells with different code
Accomplishments that we're proud of
the jupyter repl is nicely abstracted in the system, and gives a persistent session state for working with the data objects The concept of agents allows for creating new strategies for different models, as well as new "styles" of agents (eg. in the future could create an agent that is pyspark focused rather than pandas focused) and easily via some prompt engineering introduce it as a new py file that uses the baseclass. Search + CSV download features really enhance the experience, giving it a much more "workspace" feel rather than just "demo" The end-to-end experience of this feels remarkable. Imagine if we could connect this to all the data in data.gov, kaggle, etc. Imagine being able to search all data on the internet and analyze it with language models. This is exciting.
What we learned
Working with gemini was a cool experience and how we can intergrate multimodels to get amazing outputs Github search API is not the same as the web-search ui as of now (June 2023), and it's not clear when that will be updated
What's next for Datamate
We have a bunch of features in the backlog, and we're hoping to get it into the hands of as many users as possible. Find out what works, what doesn't work, how it's solving issues and not. The three features we're the most excited about adding: HTML export of a conversation -- since we are using a jupyter kernel in the backend, it should be possible for us to save the jupyter notebook and convert it to an html page, which would allow for people to share their conversations and analysis with others, including the code that was used! Building our own search function (beyond github's api) to allow people to search across many online data stores, making this a tool for journalists, researchers, etc. to find and analyze public data.
Built With
- fastapi
- gemini
- github
- google-cloud
- jupyter
- next-js


Log in or sign up for Devpost to join the conversation.