-
-
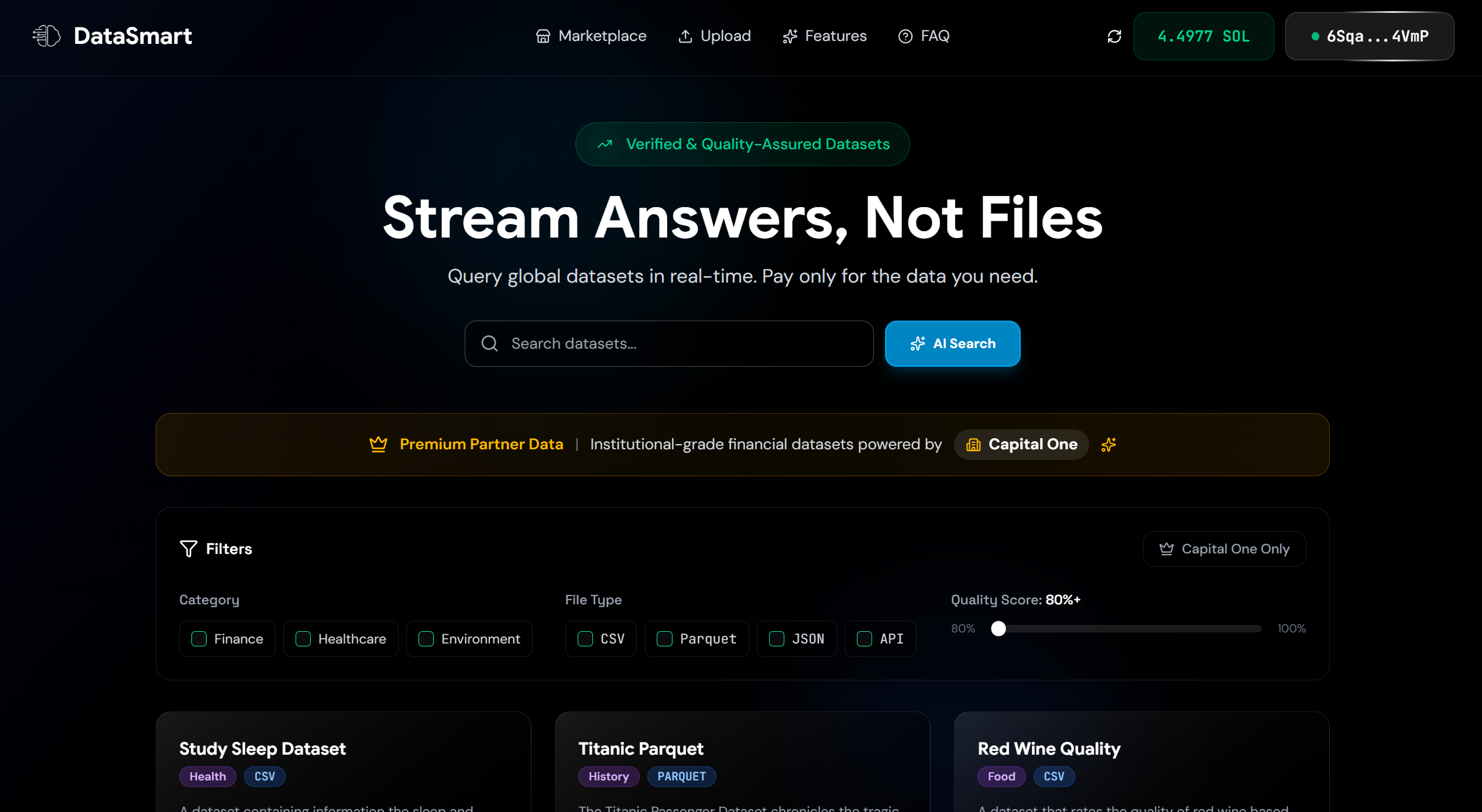
DataSmart Landing Page
-
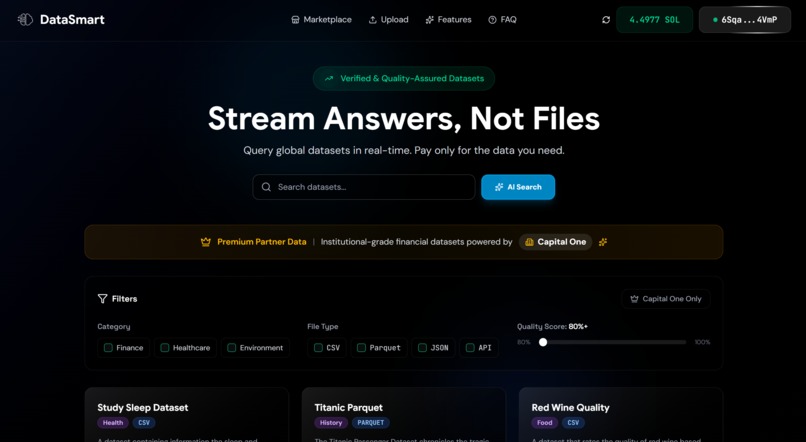
Snowflake-Powered RAG Searching
-
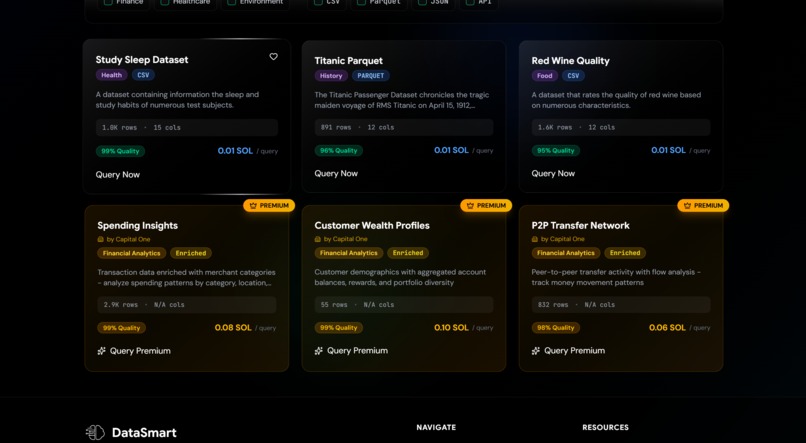
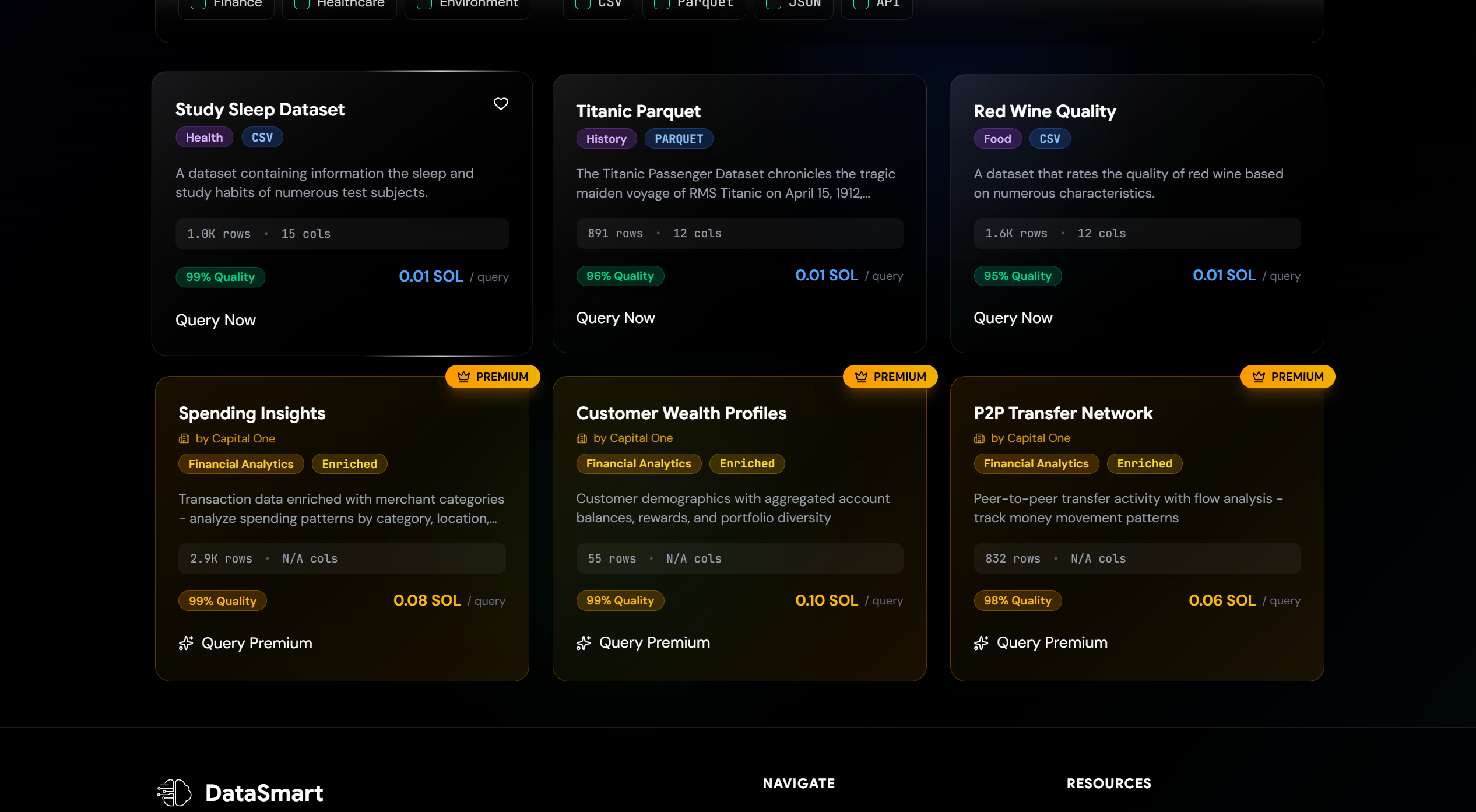
Dataset Postings including Premium Capital One
-
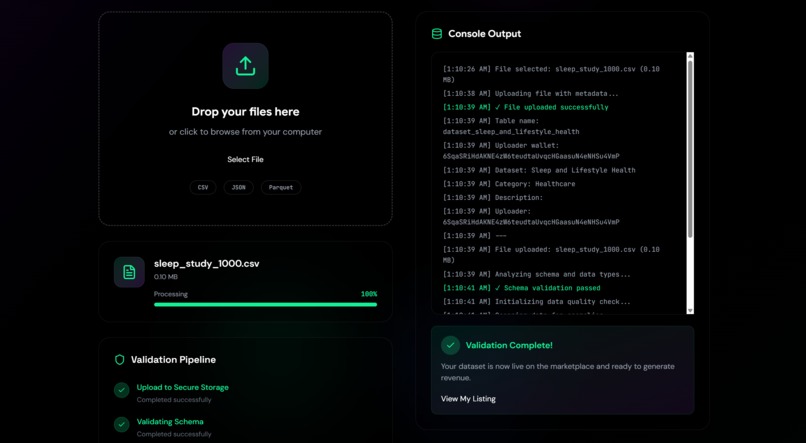
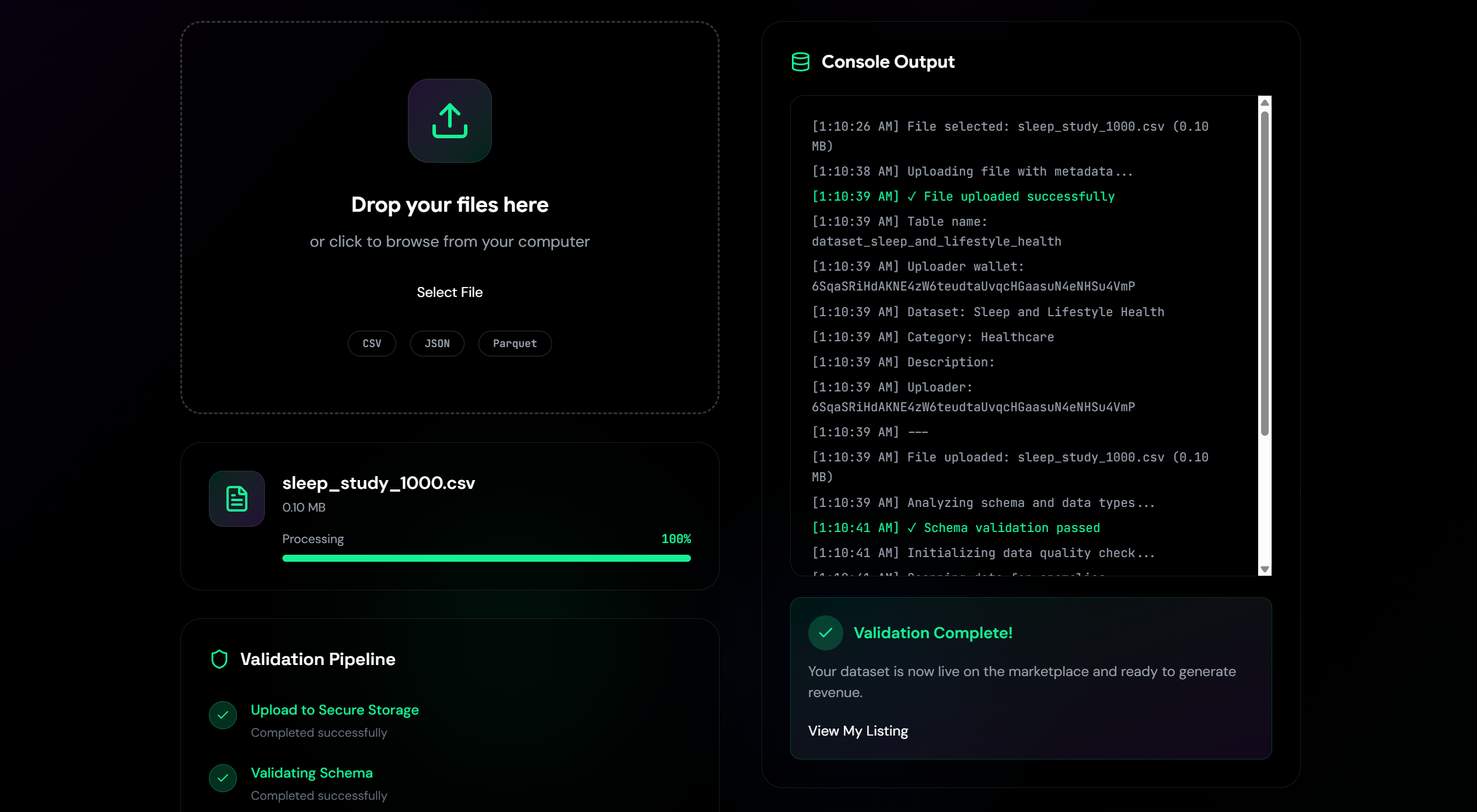
Dataset Validation Pipeline
-
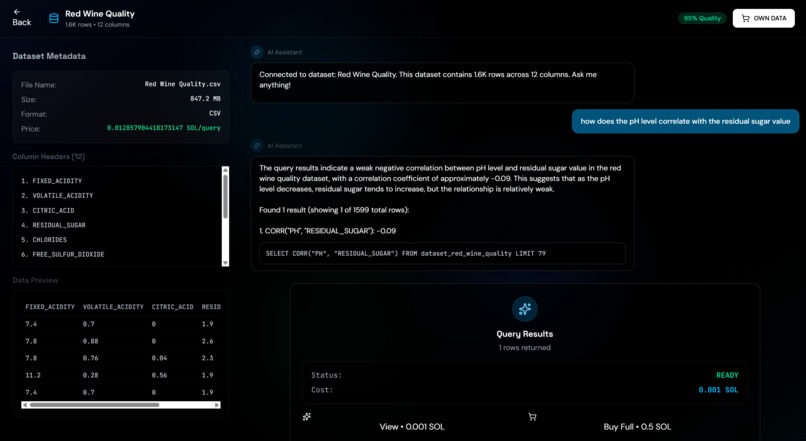
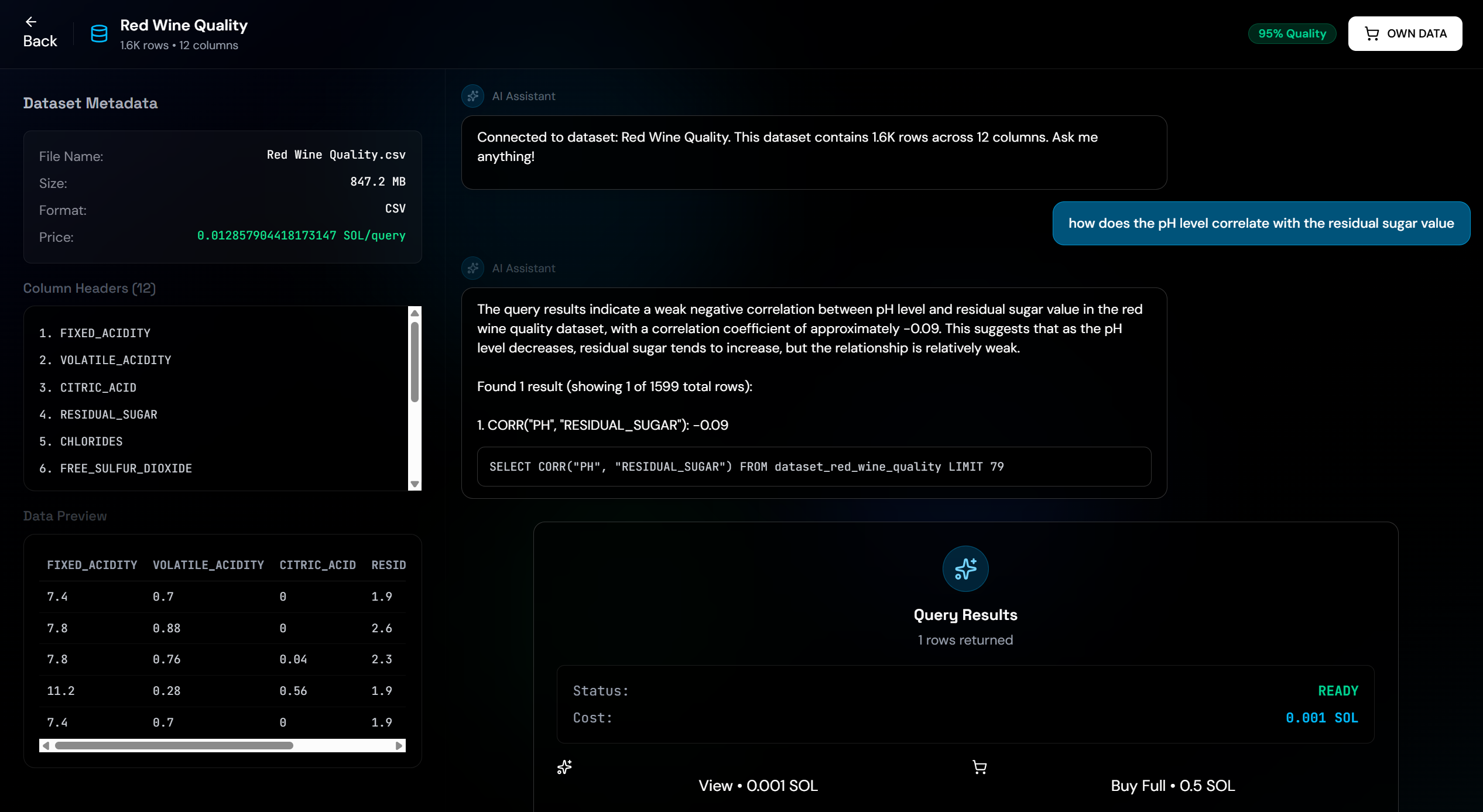
Google Gemini Powered Data Querying Chat
-
DataSmart FAQ Section
-
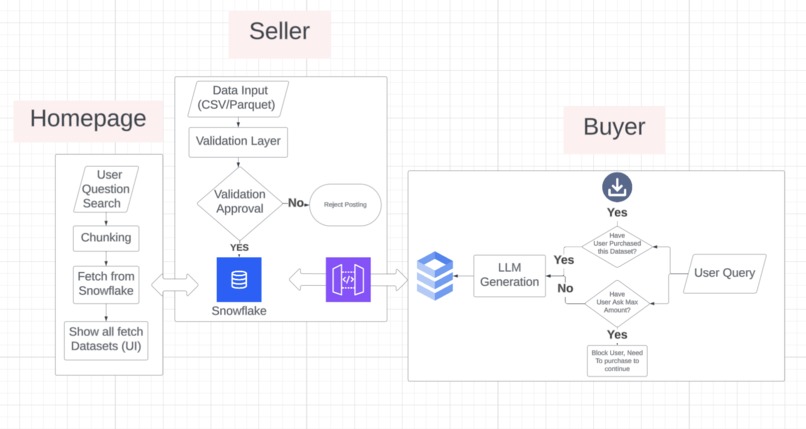
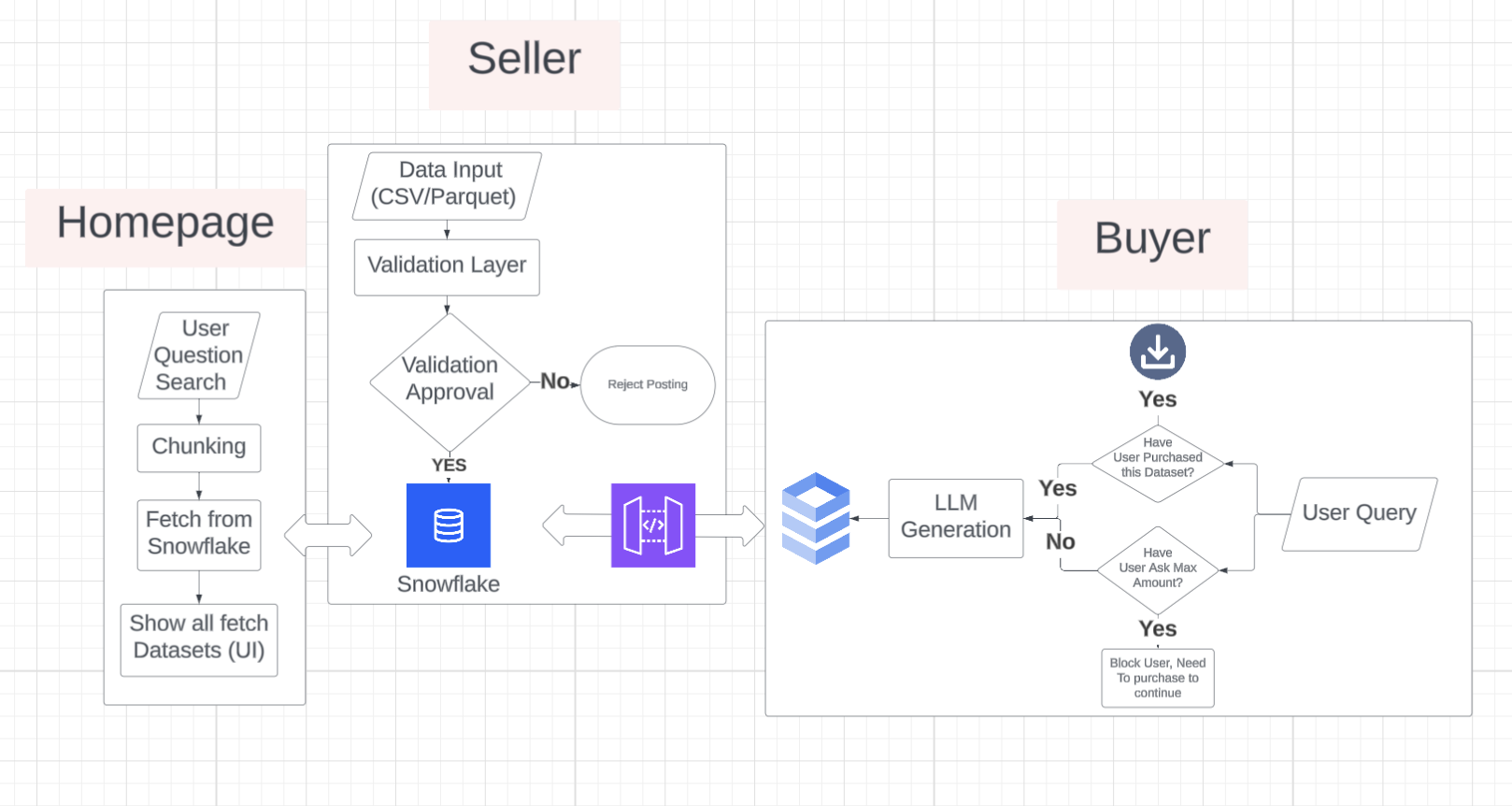
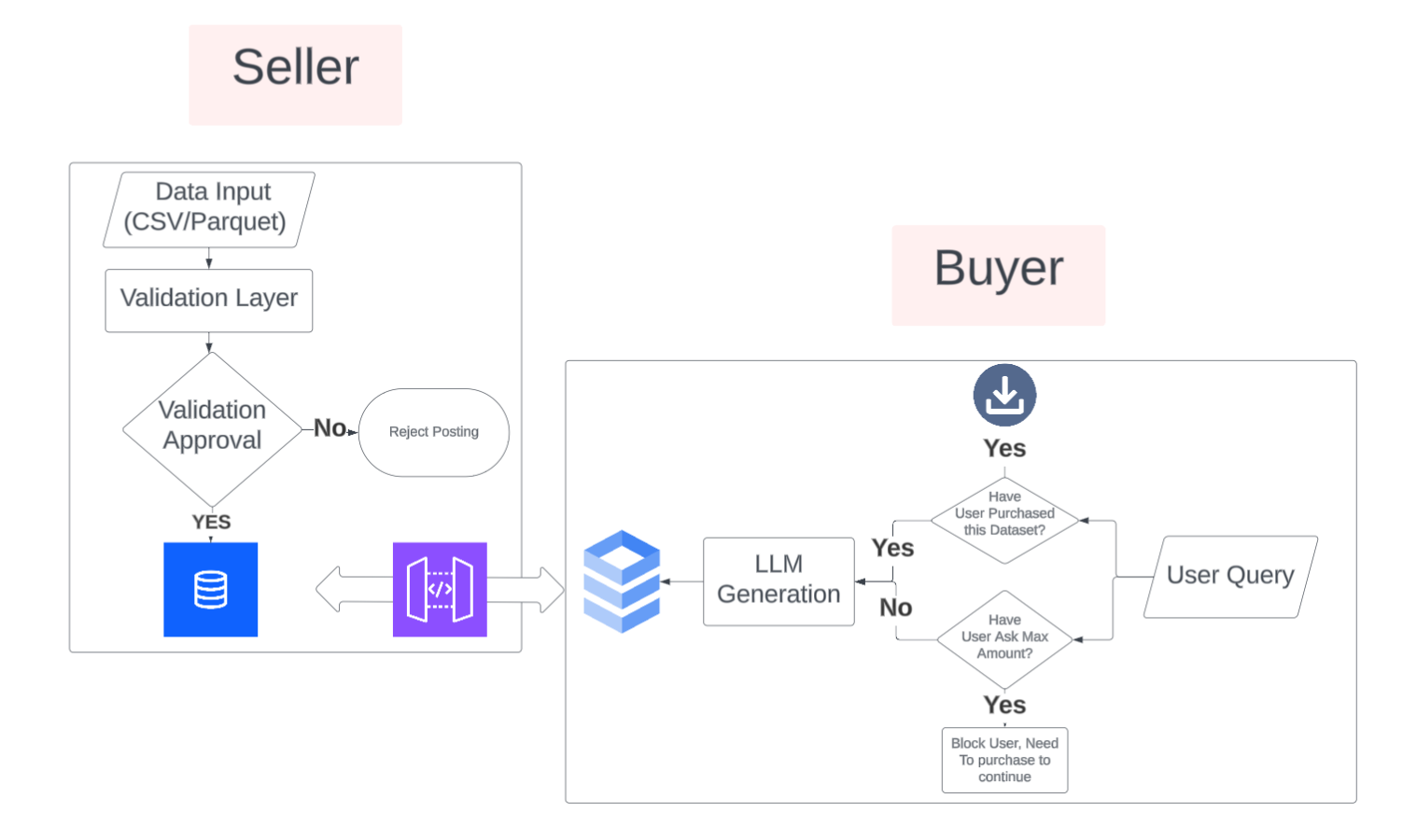
System Design
Inspiration
Public datasets often lack depth or relevance, while private datasets usually require a full purchase before you can assess their value. This creates friction and risk for buyers. We wanted to bridge this gap by letting users explore a limited portion of a dataset before committing to a purchase.
Solana was a natural fit for this model. Its ability to handle fast, low-cost transactions makes it ideal for charging per query. Users can pay fractions of a cent per query instead of committing to expensive subscriptions upfront.
What It Does
DataSmart is a marketplace where data producers can publish datasets and data consumers can test them before buying.
Producers list their datasets on the platform with metadata (category, description, quality scores). Consumers can run low-cost queries on a segmented portion of the data (5% sample) to evaluate its usefulness. If the data meets their needs, they can proceed with purchasing the full dataset with confidence.
The platform features:
- AI-Powered Dataset Discovery: RAG (Retrieval Augmented Generation) semantic search lets users find datasets using natural language descriptions
- Natural Language Querying: Powered by Gemini to convert plain English questions into SQL queries with conversational follow-up support
- Automatic Data Validation: Using Polars to score datasets 0-100 based on completeness, duplicates, data types, and statistical quality
- Free Tier: 2 queries per dataset per wallet address
- Pay-Per-Query Micropayments: Via Solana (typically 0.01-0.10 SOL per query)
- Premium Datasets: Capital One datasets via the Nessie API, enriched and cached locally
- Enterprise Cloud Storage: Snowflake for scalable, reliable dataset storage and querying
How We Built It
Frontend: React 19 + TypeScript + Vite with Tailwind CSS. Integrated Solana wallet adapter for crypto payments. Built a responsive marketplace UI with dataset browsing, filtering, AI-powered semantic search, and a conversational natural language query interface.
Backend: FastAPI to handle API requests. Snowflake as the primary cloud data warehouse for scalable dataset storage. DuckDB as a fallback for local analytics. Polars for data validation and processing. Groq API (Llama 3.1) converts natural language questions into SQL queries with conversation history support. Integrated the Nessie API for Capital One premium financial datasets.
Data Pipeline: Uploaded datasets are validated using a weighted scoring system (missing values 25%, completeness 20%, duplicates 15%, data types 15%, statistical quality 10%, schema consistency 10%, data range 5%). Only datasets scoring ≥80/100 are stored in Snowflake with proper column sanitization and metadata tagging. Premium datasets are fetched from Nessie API, cached locally in DuckDB, and enriched via SQL joins for faster access.
AI-Powered Search: Implemented RAG (Retrieval Augmented Generation) using sentence-transformers to create embeddings of dataset metadata. Users can search for datasets using natural language (e.g., "I need customer transaction data"), and the system returns the most relevant dataset based on semantic similarity, combining both user-uploaded Snowflake datasets and premium Capital One datasets.
Payments: Direct SOL transfers using @solana/web3.js. Transactions are signed via the wallet adapter and confirmed on Solana Devnet. Each query generates a transaction receipt for auditability.
Query Processing: Natural language queries are converted to SQL using Gemini with conversation history for follow-up questions. The system handles aggregations, correlations, and complex queries, automatically fixing common SQL errors (like mixing aggregate functions with non-aggregated columns). Results are automatically limited to 5% of total rows (max 100 rows) to prevent data leakage while still providing meaningful insights. For premium datasets, queries are converted to Polars code for execution.
Challenges We Ran Into
One of our biggest challenges was migrating from local DuckDB storage to Snowflake cloud storage while maintaining backward compatibility. We had to handle Snowflake's case-sensitive identifiers, reserved keywords (like "SEX"), and proper data type conversions. We implemented robust column name sanitization and automatic quoting of identifiers to ensure queries work correctly.
Another major challenge was building the RAG-powered semantic search system. We needed to create embeddings for dataset metadata, handle both Snowflake and premium datasets in a unified search, and ensure the search results are relevant and useful. We also had to balance search accuracy with performance, ultimately choosing to return only the top result for a cleaner user experience.
Implementing conversational AI querying with Gemini required careful prompt engineering to generate valid SQL queries. We encountered issues with SQL that mixed aggregate functions (like CORR) with non-aggregated columns, which Snowflake rejects. We built automatic SQL repair logic to detect and fix these issues, extracting only aggregate expressions when appropriate.
Balancing data access with data protection remained a challenge. We implemented a 5% result limit on queries and a two-query free tier per wallet to prevent abuse while still allowing meaningful exploration. Getting the AI to generate clean, executable SQL queries also required significant iteration on system prompts and error handling.
Accomplishments We’re Proud Of
We successfully integrated Snowflake cloud storage as our primary data warehouse, enabling scalable dataset management. This was a significant upgrade from local-only storage and required careful handling of Snowflake's SQL syntax and data types.
We built a RAG-powered semantic search system that allows users to discover datasets using natural language. The system intelligently searches across both user-uploaded datasets and premium Capital One datasets, returning the most relevant results based on semantic similarity.
We implemented a conversational AI query interface using Groq (Llama 3.1) that maintains conversation history, allowing users to ask follow-up questions and refine their queries naturally. The system automatically handles SQL generation, execution, and result description.
We created an intelligent SQL repair system that detects and fixes common SQL errors, such as mixing aggregate functions with non-aggregated columns. This ensures queries work correctly even when the AI generates imperfect SQL.
We successfully integrated Solana-based crypto payments into a real application and gained hands-on experience building a pay-per-query system from the ground up. For our team, this was our first time working directly with Solana and blockchain payments.
We built a comprehensive data validation pipeline that automatically scores datasets and only stores high-quality data at or above 80 out of 100. We also created an intelligent caching system for premium datasets that fetches raw data once, then builds enriched datasets through fast local SQL joins, reducing API calls from minutes to milliseconds.
What We Learned
We learned how to work with Snowflake cloud data warehouses, including proper SQL syntax, identifier quoting, data type handling, and query optimization. This experience taught us the importance of robust error handling and SQL validation.
Building the RAG search system taught us about semantic embeddings, vector similarity, and how to combine multiple data sources (Snowflake and premium APIs) into a unified search experience. We learned to balance search accuracy with user experience.
Working with Groq and conversational AI taught us about prompt engineering, conversation context management, and how to handle AI-generated code safely. We learned to validate and repair AI-generated SQL to ensure it executes correctly.
We learned how to design and structure payment systems, especially in the context of fair pricing for data access. We also gained insight into balancing accessibility for consumers with proper incentives and protections for data producers.
Working with Solana taught us about transaction confirmation, blockhash management, and handling wallet connections. We learned the importance of local caching for external APIs. Our Nessie integration would have been prohibitively slow without intelligent caching.
The data validation pipeline taught us about the complexity of assessing data quality programmatically. Different datasets have different quality concerns, and our weighted scoring system had to balance multiple factors to be fair across different data types.
What’s Next for DataSmart
As we scale to larger datasets, we plan to enhance our Snowflake integration with better query optimization, automatic scaling, and advanced analytics capabilities. We'll also implement more sophisticated metadata extraction and tagging to improve RAG search accuracy.
We plan to add job scheduling to securely segment and deliver data. Using Redis queues and Celery, we can process encrypted data in chunks for improved security and better handling of large result sets. We also plan to expand our cloud storage capabilities, potentially integrating additional cloud data warehouses and implementing data replication for improved reliability and performance. This will enable us to handle datasets that exceed local storage capacity.
Additional improvements:
- Enhanced query validation and SQL repair for more complex queries
- More sophisticated pricing models based on query complexity and data size
- Support for additional data formats (JSON, Parquet already supported)
- Analytics dashboard for data producers to track query volume and revenue
- Multi-chain support beyond Solana for broader payment options
- Improved RAG search with better ranking algorithms and multi-result support
- Advanced conversation features with query suggestions and auto-completion
Built With
- duckdb
- fastapi
- google-gemini-api
- nessie-api
- polars
- pydantic
- python
- react
- snowflake
- solana
- sql
- tailwind
- typescript






Log in or sign up for Devpost to join the conversation.