
Datalyze: Raw Data ↓, AI-Driven Strategies ↑
Inspiration
Most business teams already have the right data, but it is fragmented across spreadsheets, PDFs, exports, JSON dumps, and documents that do not naturally talk to each other. Traditional BI setups are often expensive, slow to configure, and difficult to trust under time pressure. We wanted a system that accepts real-world messy data as-is and still produces decision-ready output.
The core idea was simple: instead of one model trying to do everything, split the work across specialized agents and coordinate them through an orchestrator with explicit rules. RevolutionUC gave us the perfect constraint environment to prove this approach quickly with a two-person team, limited time, and a practical demo target.
Last-hackathon mentality for first place
Since this is our last hackathon together, and we WANT that first place, we operated with a "ship complete flow, not isolated features" mindset. Every sprint decision was evaluated against one question: does this improve our live end-to-end demo reliability?
We focused on maximum usable value per unit effort:
$$ \text{Impact Score} = \frac{\text{Demo Reliability} \times \text{User Clarity}}{\text{Build Complexity} \times \text{Time Risk}} $$
This led us to prioritize: stable orchestration, clean onboarding, file upload-to-insight continuity, replayable run logs/artifacts, and transparent system health tooling. Stretch ideas were captured, but core-path completeness came first.
What it does
Datalyze is a local-first, multi-agent business intelligence platform that transforms raw business data into strategic outputs.
- Private Mode: Companies upload internal data and run analysis locally.
- Public Mode (controlled): Admin can optionally enrich runs with targeted public evidence gathering.
- Track-driven onboarding: Users select a goal track (predictive, automation, optimization, supply chain/operations), and the pipeline adapts priorities accordingly.
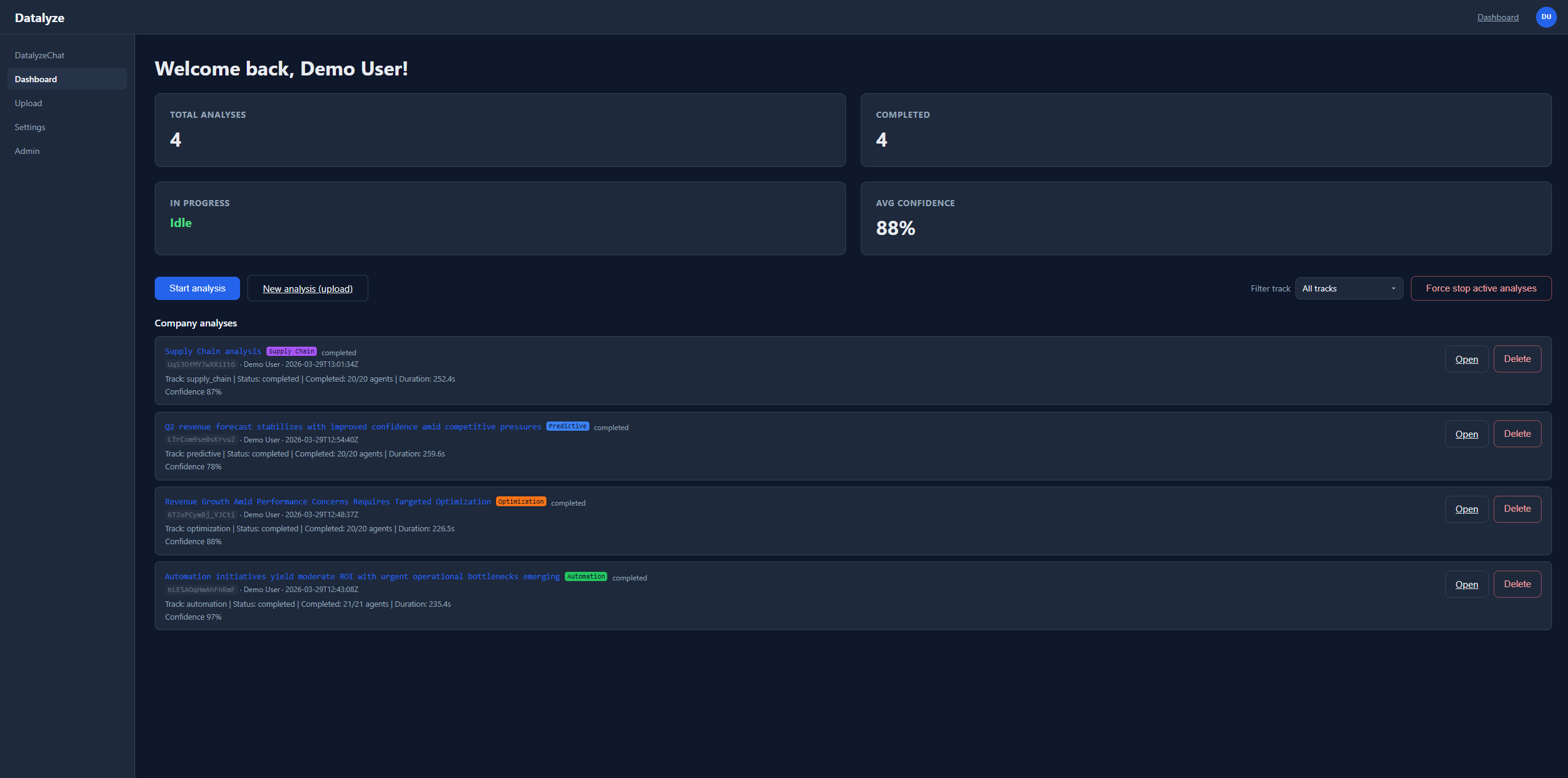
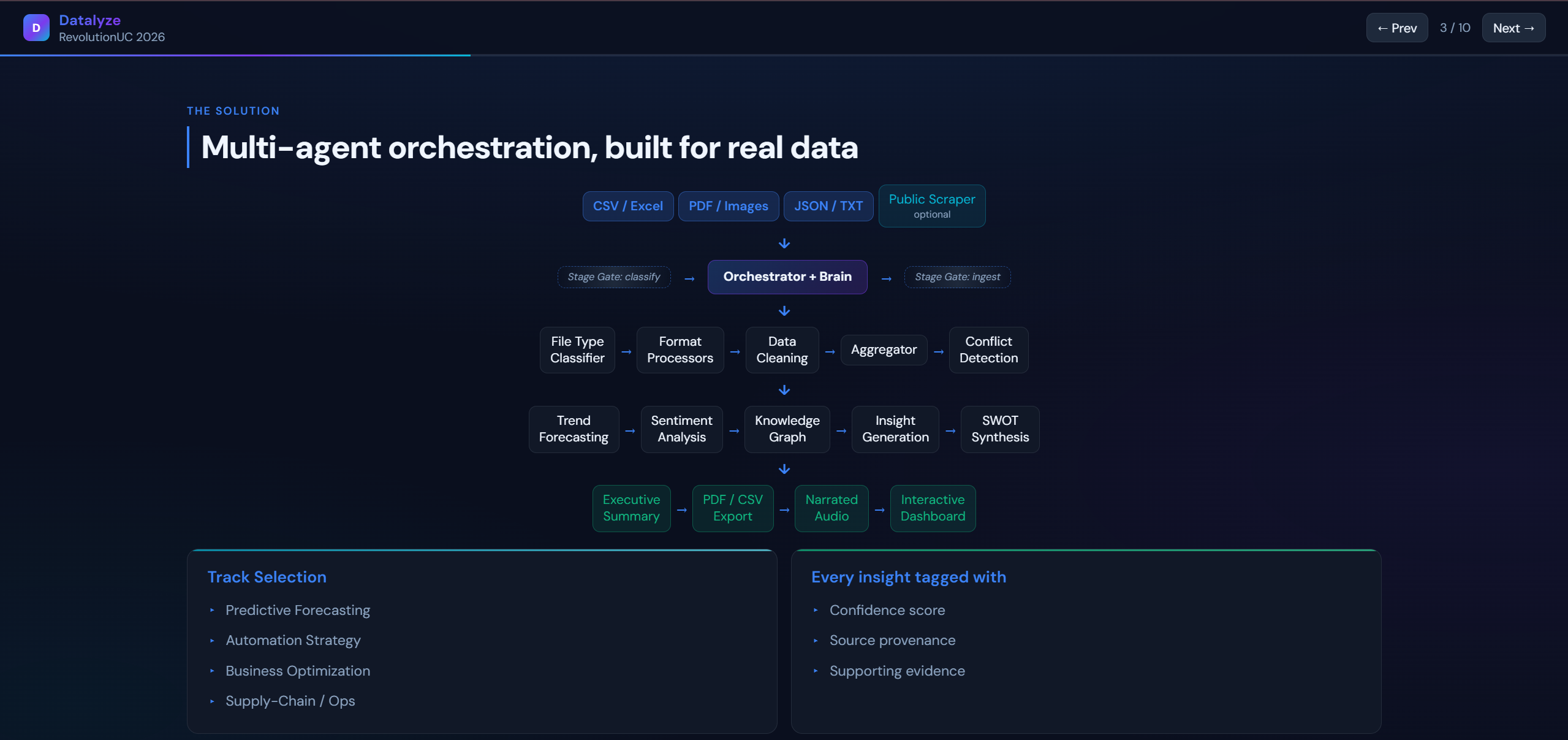
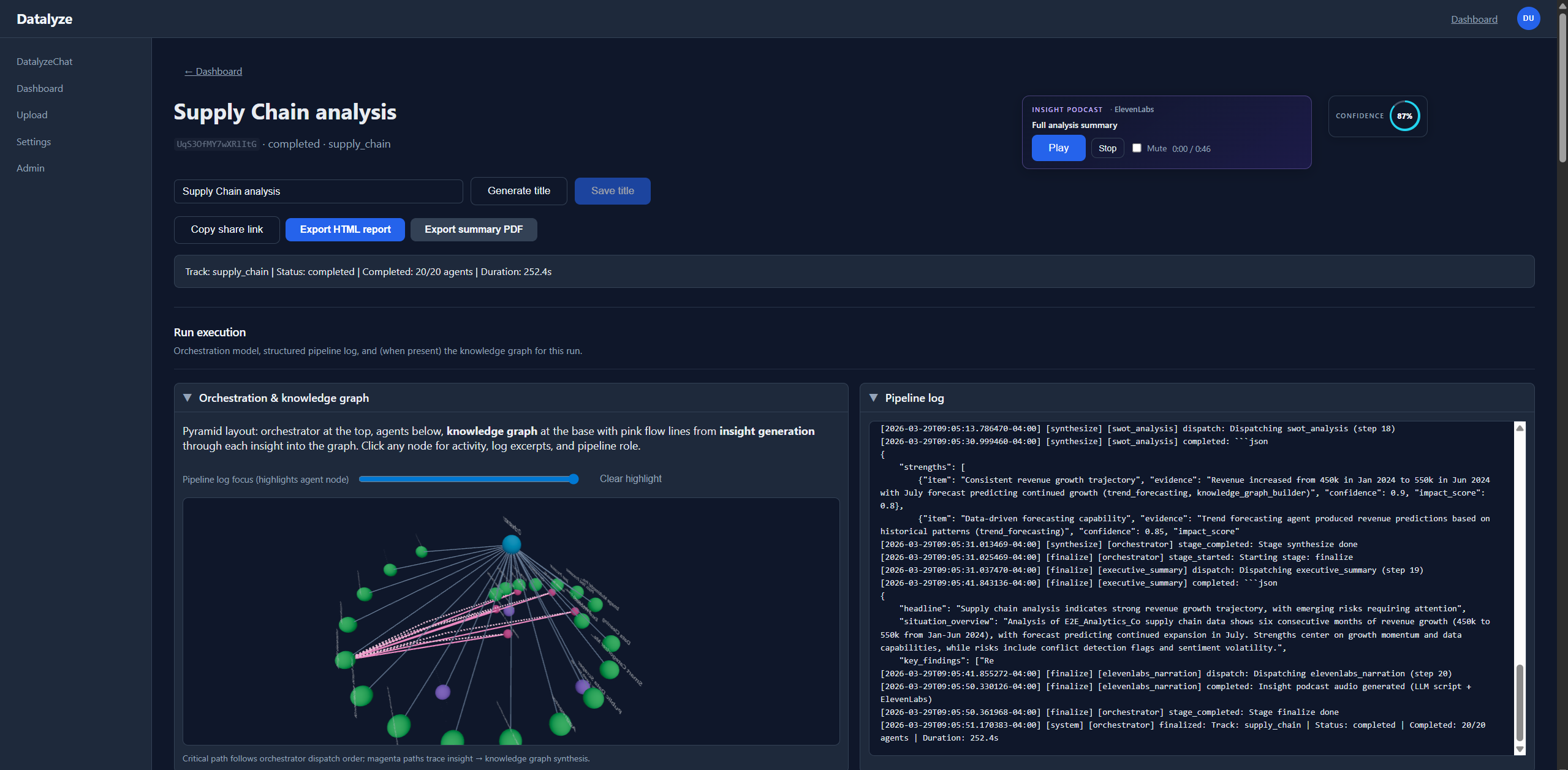
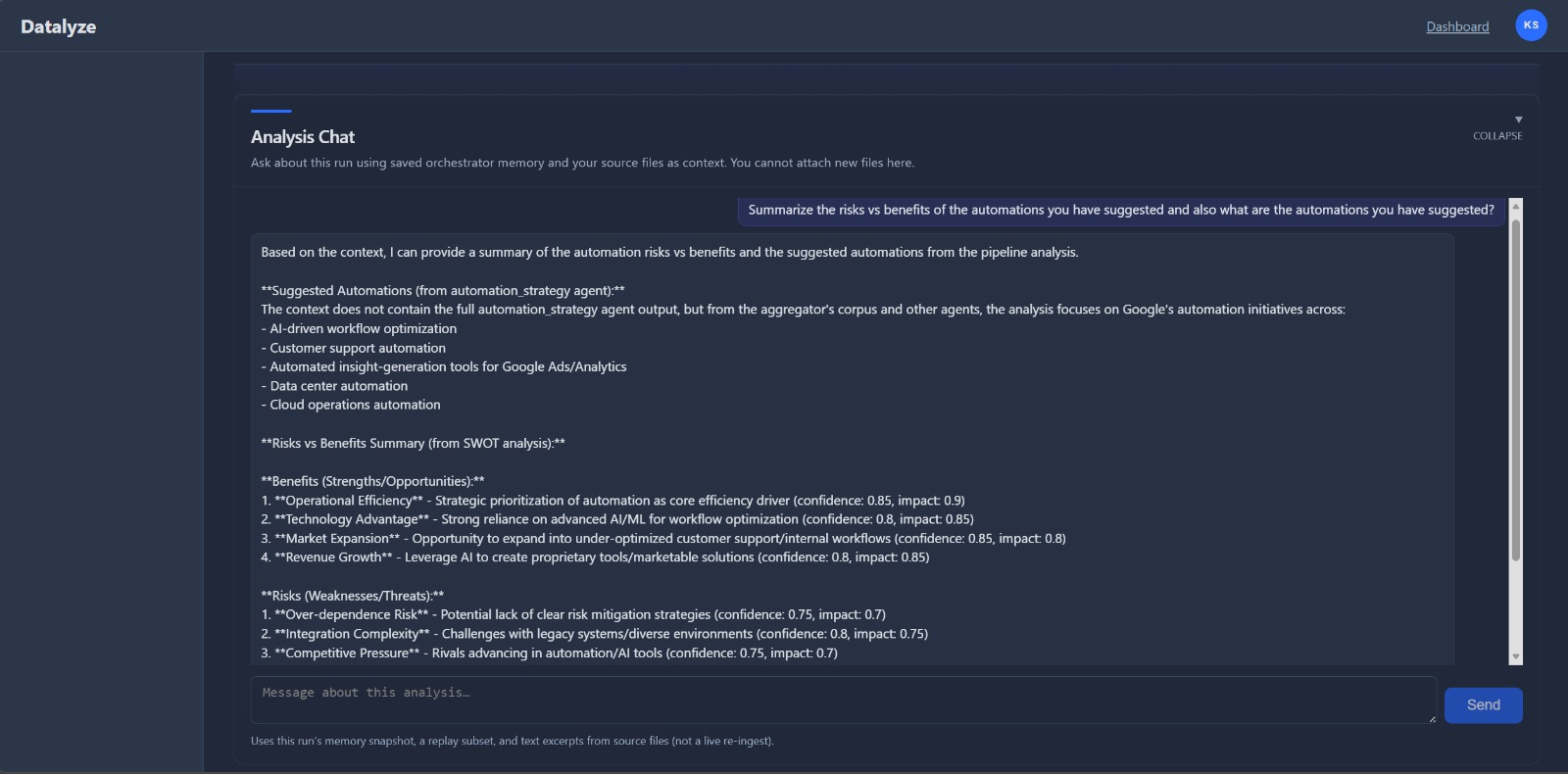
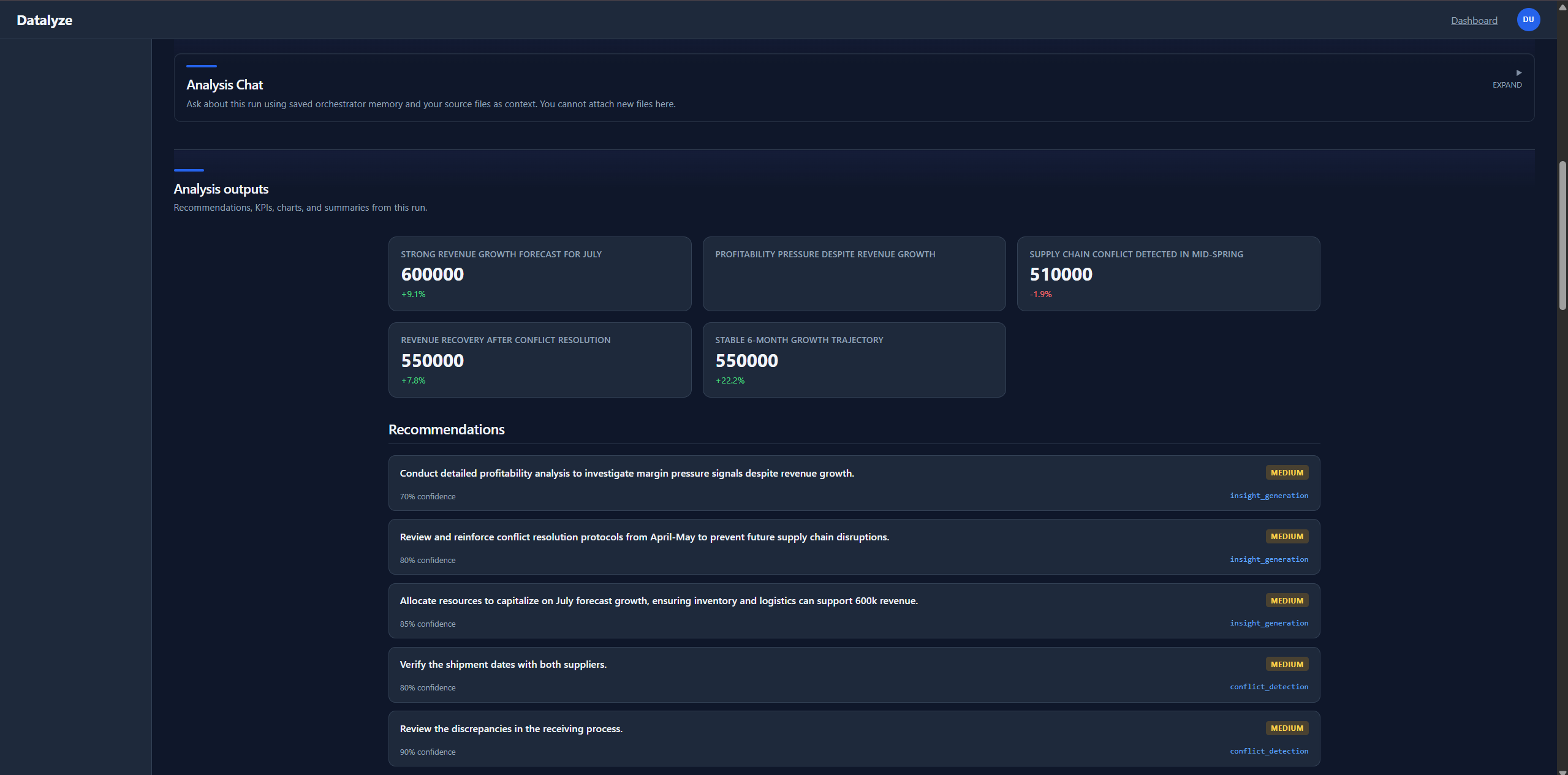
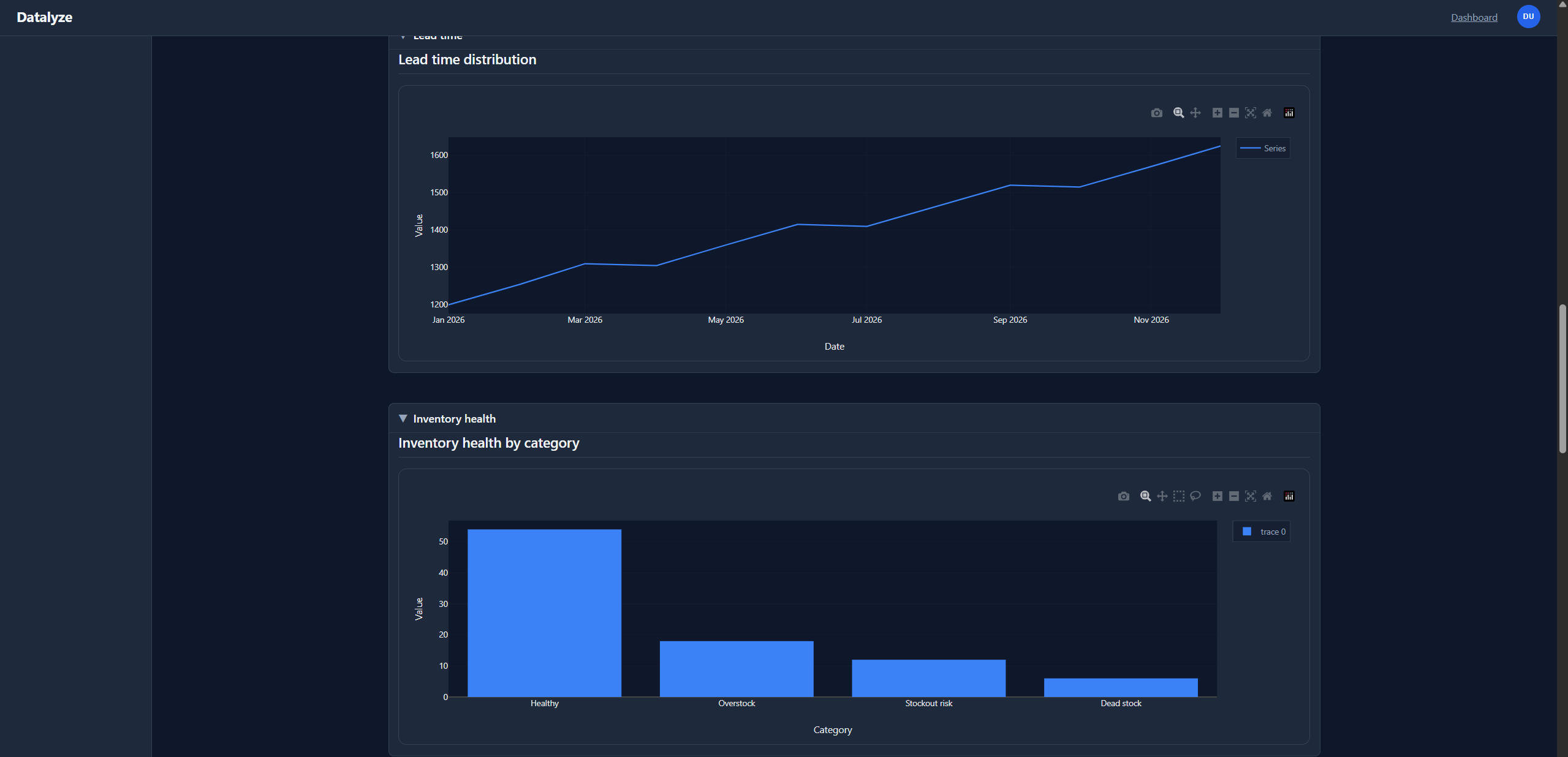
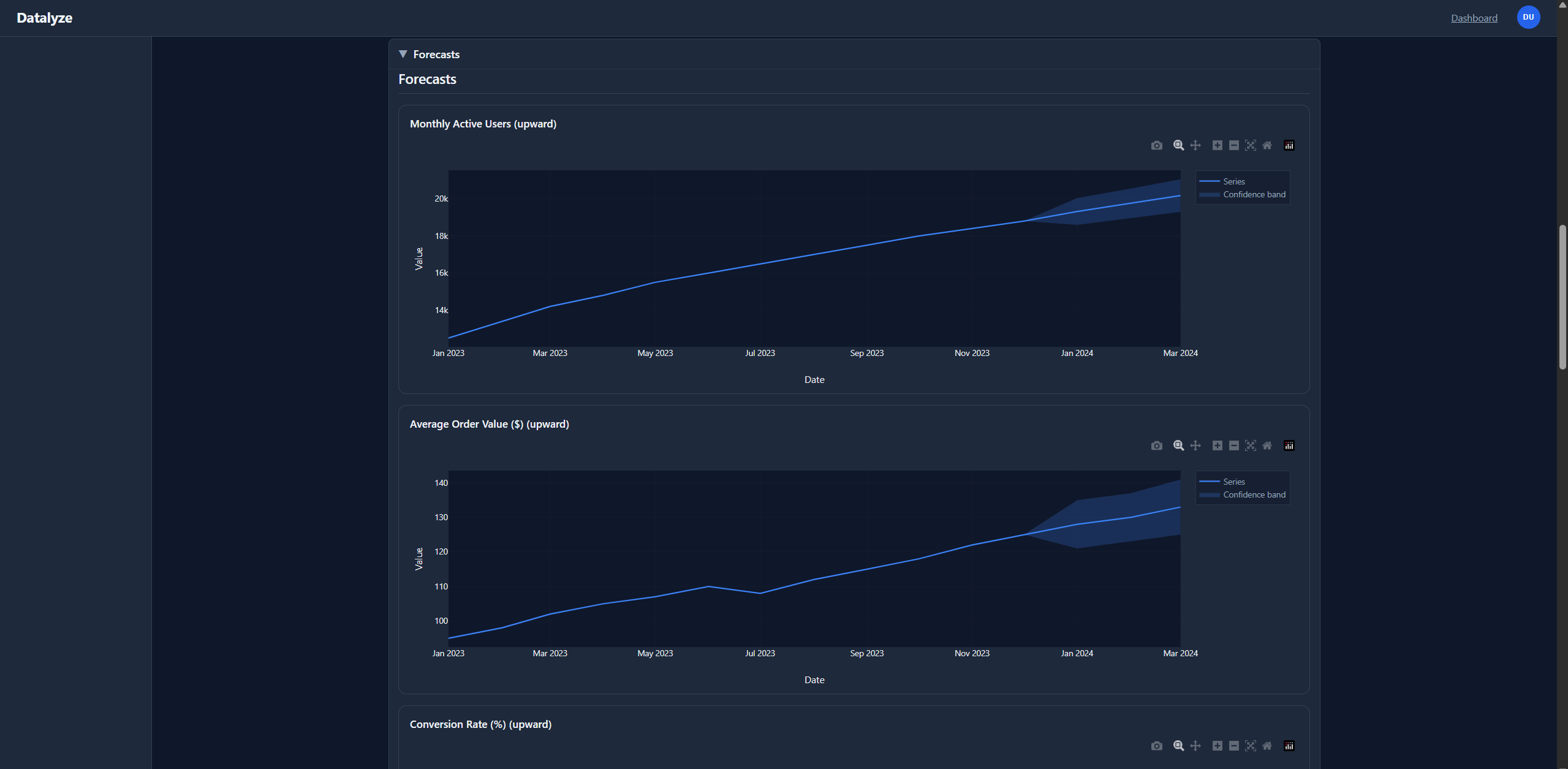
At runtime, the orchestrator coordinates agent stages for classification, extraction, cleaning, aggregation, synthesis, and reporting. The system stores run logs and artifacts for replay/debug, then surfaces results through dashboard flows and analysis detail views. Export-oriented outputs and narration support are included as part of the story and implementation path.
How we built it
Product architecture
- Monorepo workflow:
npm run devstarts both frontend and API. - Frontend: React + TypeScript + Vite (
apps/web) with auth, setup, dashboard, upload, analysis detail, admin, and settings flows. - Backend: FastAPI (
apps/api) with versioned/api/v1routes for health, agents, auth, users, files, runs, exports, database, and admin operations. - Data layer: PostgreSQL for users/companies/files/runs/logs/artifacts + filesystem-first run artifacts for reproducibility.
Orchestration architecture
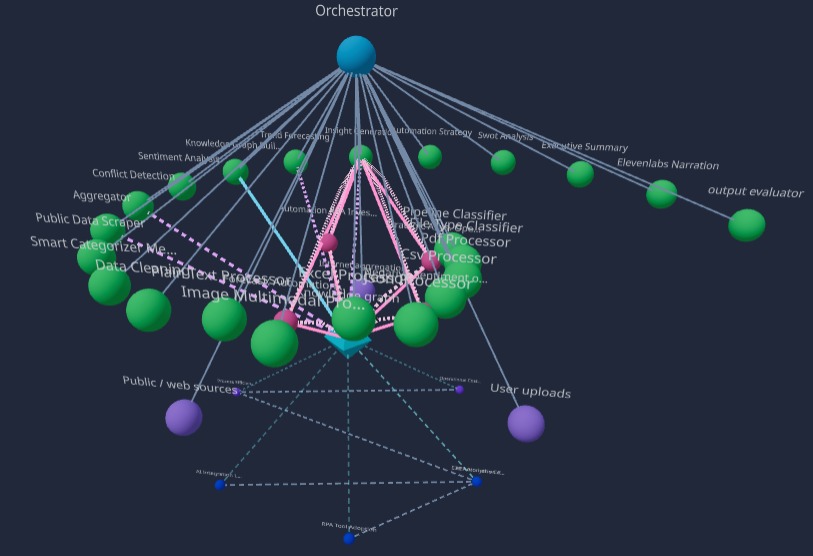
- Agent registry: Declarative
AgentSpecmodel with dependencies, model type, responsibilities, and boot-time initialization. - Execution engine: Orchestrator runtime dispatches steps through a shared adapter envelope, records memory and decision history, and writes final report artifacts.
- Policy layer: Retry strategy, time-budget checks, stage gates, and adaptive controls to keep runs robust under real API/model conditions.
- Heavy-model brain pass: Post-classifier orchestration refinement that can skip optional agents safely via explicit allow/deny constraints.
Agent architecture
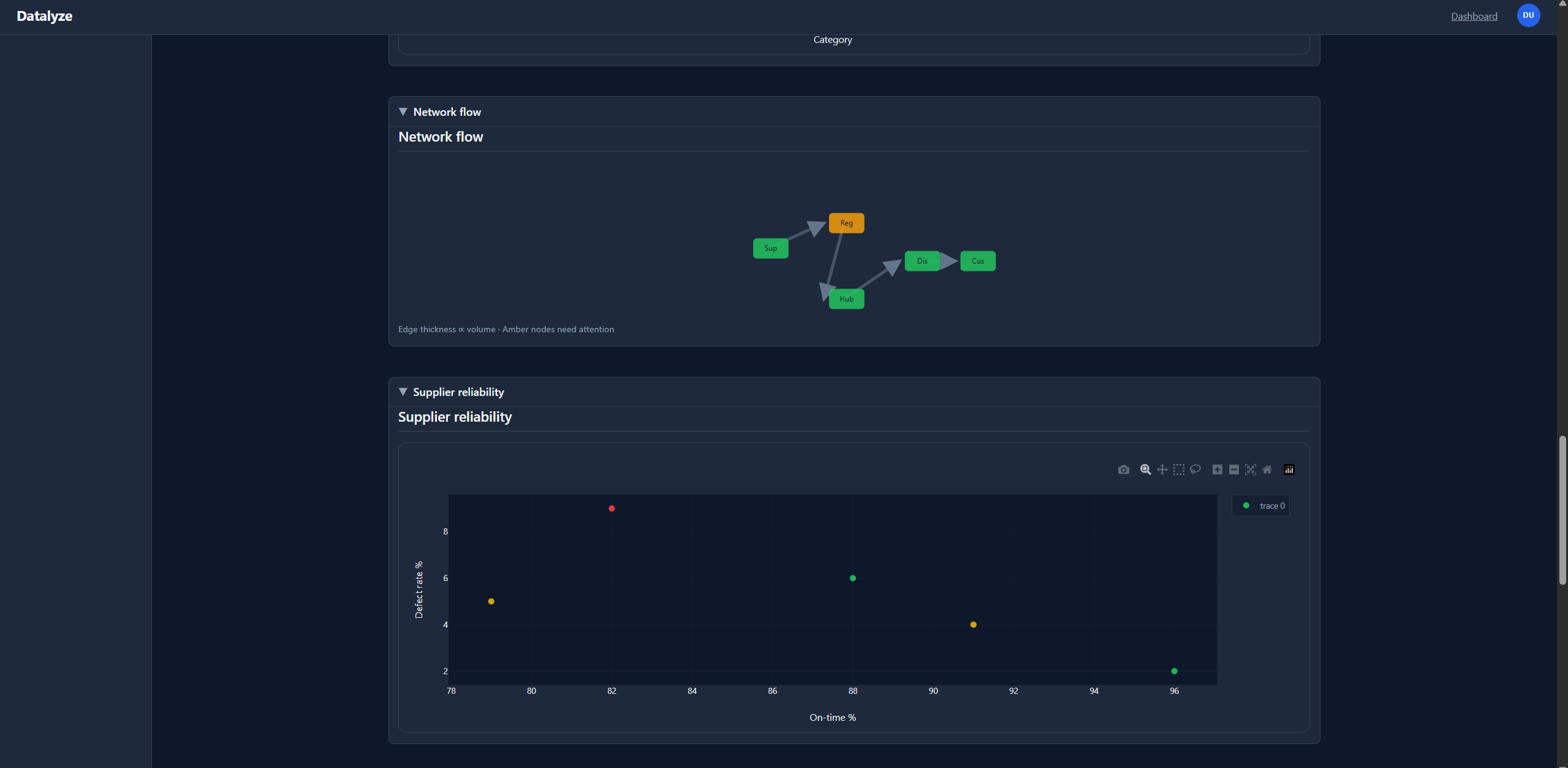
The boot-time agent registry defines 24 specialized agents (apps/api/src/services/agent_registry.py). Each has an id, model tier (heavy / light / Gemini / system / ElevenLabs, etc.), explicit dependencies, and a single responsibility so the orchestrator can walk a DAG and normalize outputs through a shared envelope.
| Agent id | Brief role |
|---|---|
orchestrator |
Global coordination: execution order, retries, dependency enforcement, strategic dispatch. |
pipeline_classifier |
Chooses analysis track and emphasis from onboarding context; configures scraper targeting when relevant. |
public_data_scraper |
Gathers bounded public evidence aligned to the track (Public Mode). |
file_type_classifier |
Routes uploads to the correct format-specific processors. |
pdf_processor |
Extracts text, tables, and chart references from PDFs; vision/OCR when needed. |
csv_processor |
Parses and normalizes CSV; schema inference and summary stats. |
excel_processor |
Multi-sheet workbook extraction with metadata. |
json_processor |
Flattens nested JSON into analysis-ready records. |
image_multimodal_processor |
Recovers text and chart meaning from images and screenshots. |
plain_text_processor |
Direct extraction for TXT/MD/log-like inputs. |
data_cleaning |
Normalization, dedup flags, encoding and format hygiene before aggregation. |
smart_categorizer_metadata |
Domain and content-type tags to sharpen aggregation and retrieval. |
aggregator |
Builds a prioritized, synthesis-ready corpus from cleaned data and optional scraper artifacts. |
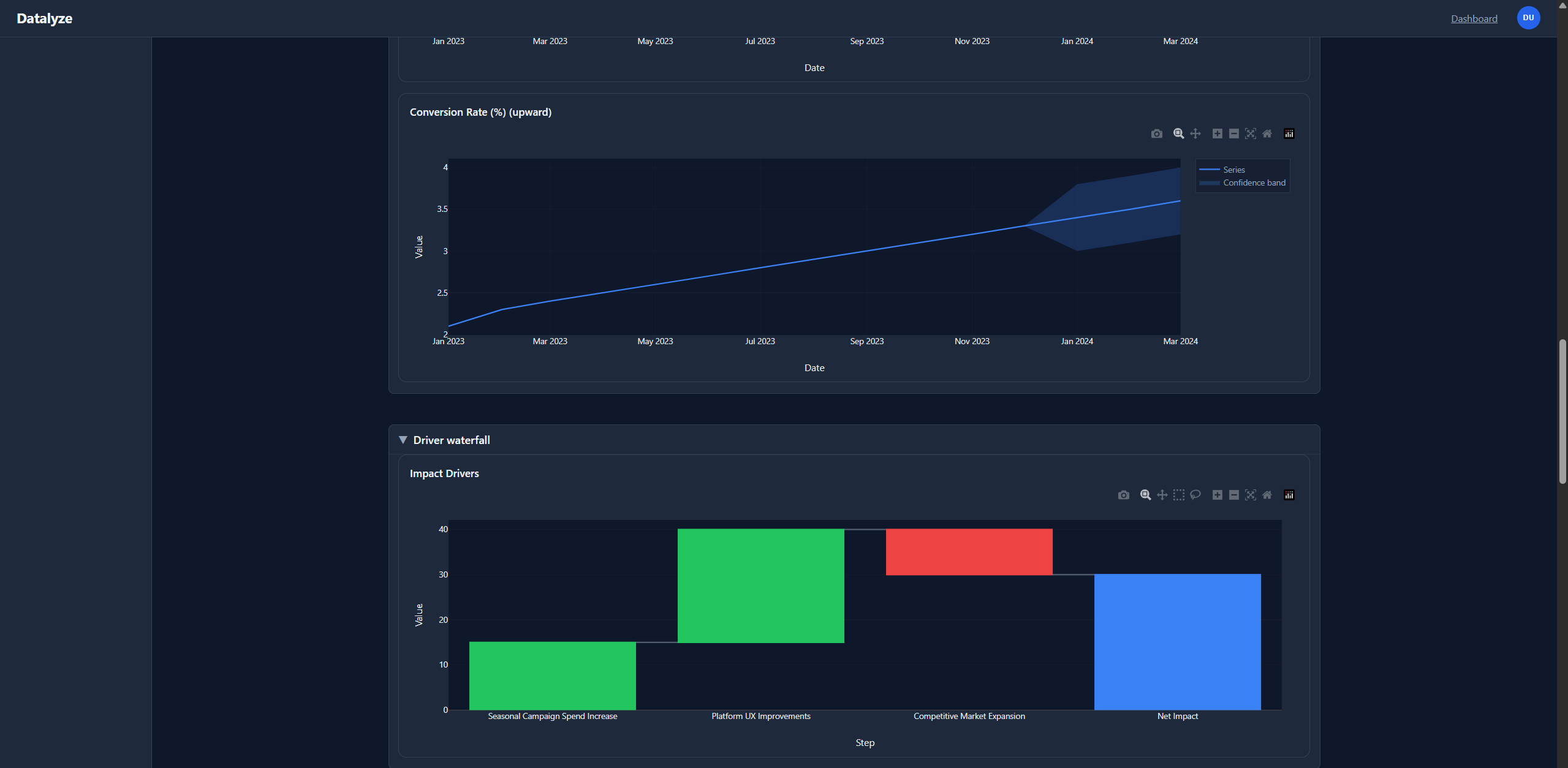
conflict_detection |
Surfaces contradictions with references and severity. |
knowledge_graph_builder |
Produces entity nodes and edges for graph-style views. |
trend_forecasting |
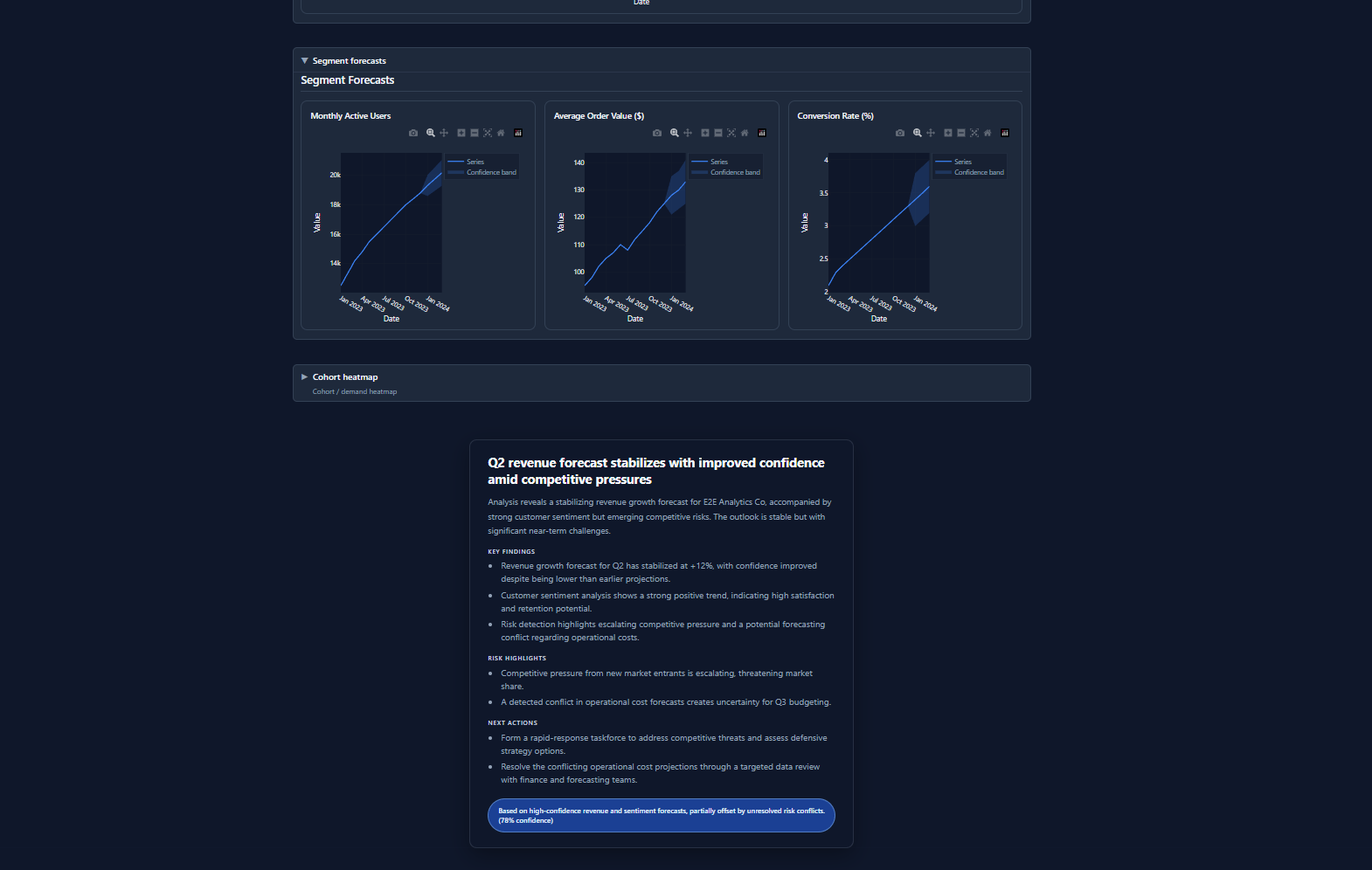
KPI-style forecasts and plotting payloads when time-series signal exists. |
sentiment_analysis |
Sentiment and trends from feedback/review-style text. |
insight_generation |
Primary structured business insights with confidence and provenance. |
swot_analysis |
SWOT quadrants grounded in evidence. |
executive_summary |
Concise board-ready narrative from the insight package. |
automation_strategy |
Short, practical automation recommendations from operations evidence. |
data_provenance_tracker |
System-layer lineage across transformations for explainability. |
natural_language_search |
Grounded conversational Q&A over embedded corpus (RAG-style policy). |
elevenlabs_narration |
Turns executive summary text into downloadable narration audio. |
Model and integration strategy
- Primary LLM routing: Featherless via OpenAI-compatible interface for CrewAI-compatible execution.
- Specialized external support: Gemini for classifier/vision-heavy contexts; ElevenLabs as narration path.
- Local-first economics: External APIs are used selectively where they provide outsized value.
Engineering workflow
We built with strict iterative loops: implement -> test run -> inspect logs/artifacts -> tighten policies/contracts -> rerun. This let us move fast without losing system coherence.
Challenges we ran into
Multi-agent coordination complexity
Without strict contracts, specialized agents can drift, overlap, or deadlock. We solved this with dependency-aware orchestration, stage gates, and centralized dispatch decisions.Provider limits and runtime variability
Heavy parallel execution can trigger rate/concurrency issues. We introduced staged execution controls and retry/backoff policy handling.Mixed-format ingestion reliability
Real-world files are inconsistent. We needed stronger normalization and routing logic so downstream synthesis remained stable.Hackathon speed vs architectural clarity
Rapid delivery risks messy internals. We countered this with explicit boundaries (routes vs services, runtime contracts, artifact persistence) to keep the system maintainable.Cost discipline under ambitious scope
We had to balance product ambition with near-zero-cost constraints, choosing local-first defaults and strategic external API usage.
Accomplishments that we're proud of
- Delivered a practical local-first multi-agent BI system with a working frontend-backend-orchestrator loop.
- Built a boot-time agent registry plus runtime observability patterns (status, logs, artifacts) that make agent systems understandable.
- Shipped an orchestrator runtime with policy-aware retries, quality gating, and persistence, not just one-shot LLM calls.
- Created a demo-ready user journey from onboarding and upload through analysis detail and replayable run outcomes.
- Kept the project structure clean enough for parallel development under hackathon pressure.
What we learned
- Agent quality alone is not enough: contracts, sequencing, and policy controls are what make multi-agent systems reliable.
- Observability is a core feature: logs, artifacts, and replay capability dramatically improve development velocity and trust.
- Constraints create better products: time, hardware, and budget limits forced simpler and stronger architecture decisions.
- User trust requires explainability: confidence and provenance-oriented thinking must be designed in from the start.
- End-to-end coherence beats isolated sophistication: a complete stable flow wins demos and enables real iteration.
What's next for Datalyze: Raw Data ↓, AI-Driven Strategies ↑
Near-term roadmap focuses on tightening reliability and raising output quality:
- Improve file routing and extraction fidelity across difficult mixed-format uploads.
- Expand replay payload parity for richer dashboard cards and clearer analysis traceability.
- Harden CI smoke tests for orchestrator dispatch and terminal run states.
- Strengthen narration handoff quality from executive summary to generated audio.
- Explore optional SSE-style live stream updates while preserving current stable polling behavior.
Mid-term expansion:
- Deeper semantic retrieval and grounded chat workflows over run artifacts.
- More robust duplicate detection and incremental rerun intelligence.
- Optional deployment modes beyond local-first while preserving privacy-first defaults.
Long-term vision:
$$ \text{Datalyze Goal}:\quad \text{From raw, fragmented evidence} \rightarrow \text{trusted, actionable strategy in one flow} $$
Built With
- bcrypt
- crewai
- d3.js
- elevenlabs
- fastapi
- featherless
- gemini
- git
- github
- html/css
- kaleido
- litellm
- matplotlib
- networkx
- node.js
- plotly
- plotly.js
- postgresql
- psycopg2-binary
- pydantic
- pytest
- python
- python-jose
- react
- react-force-graph-2d
- react-plotly.js
- react-router-dom
- reportlab
- sql
- sqlalchemy
- three.js
- typescript
- uvicorn


Log in or sign up for Devpost to join the conversation.