-
-
Landing page
-
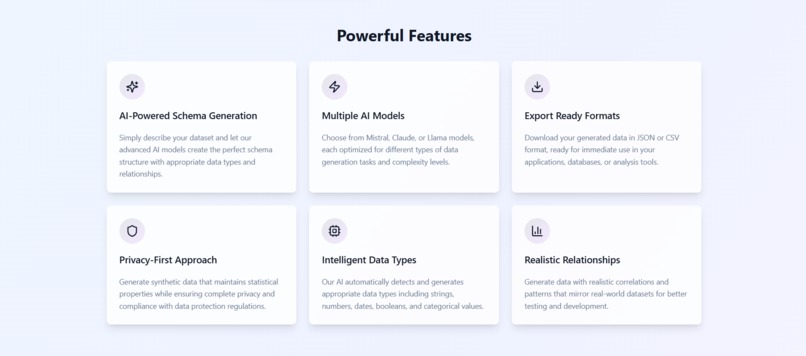
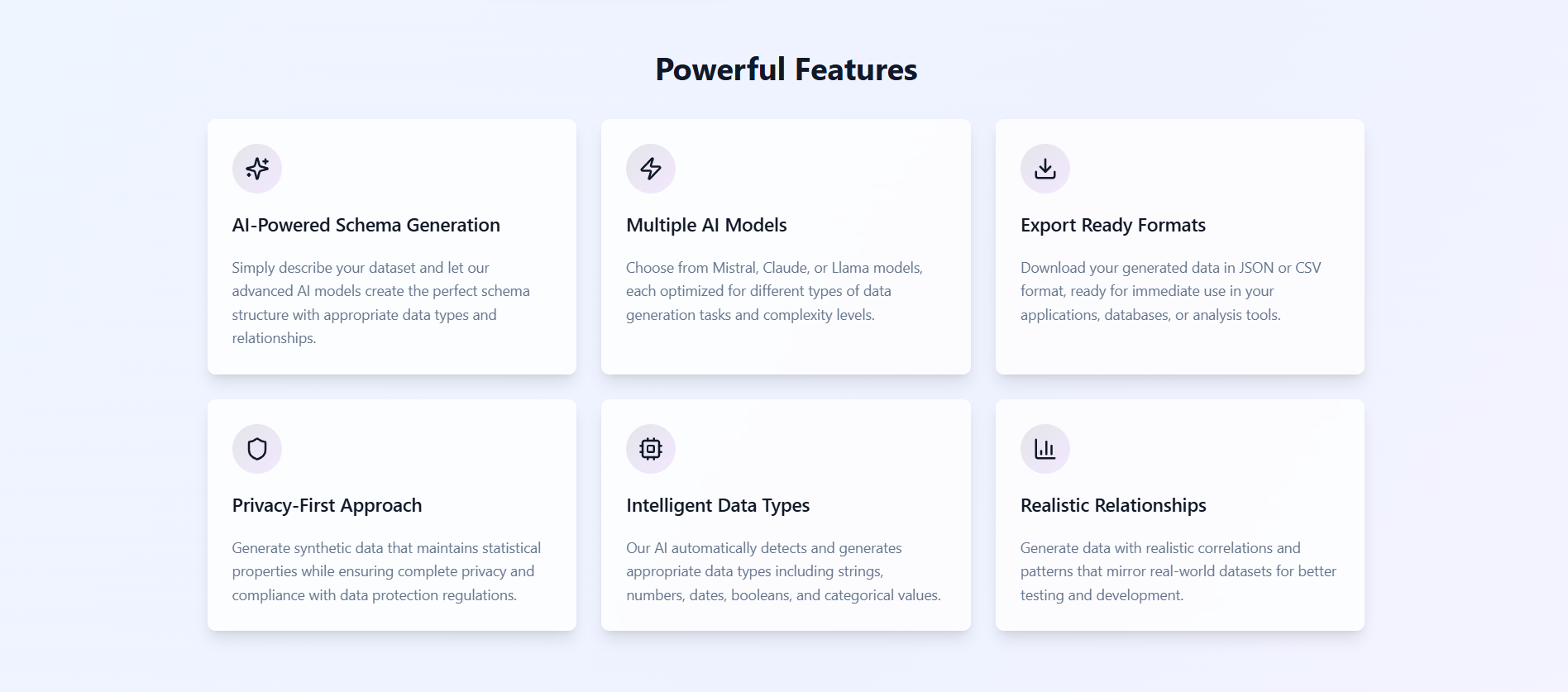
Features
-
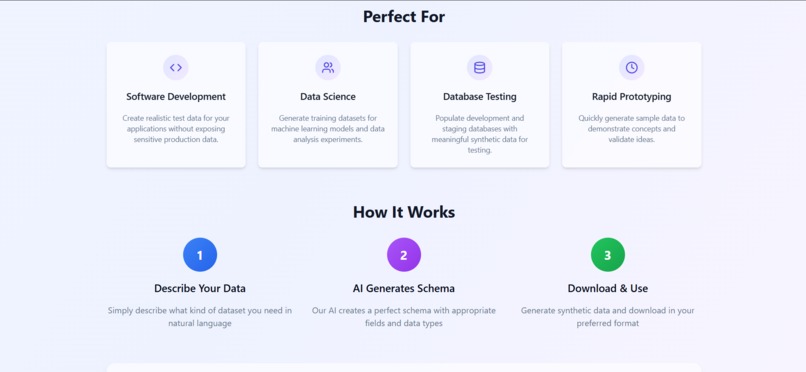
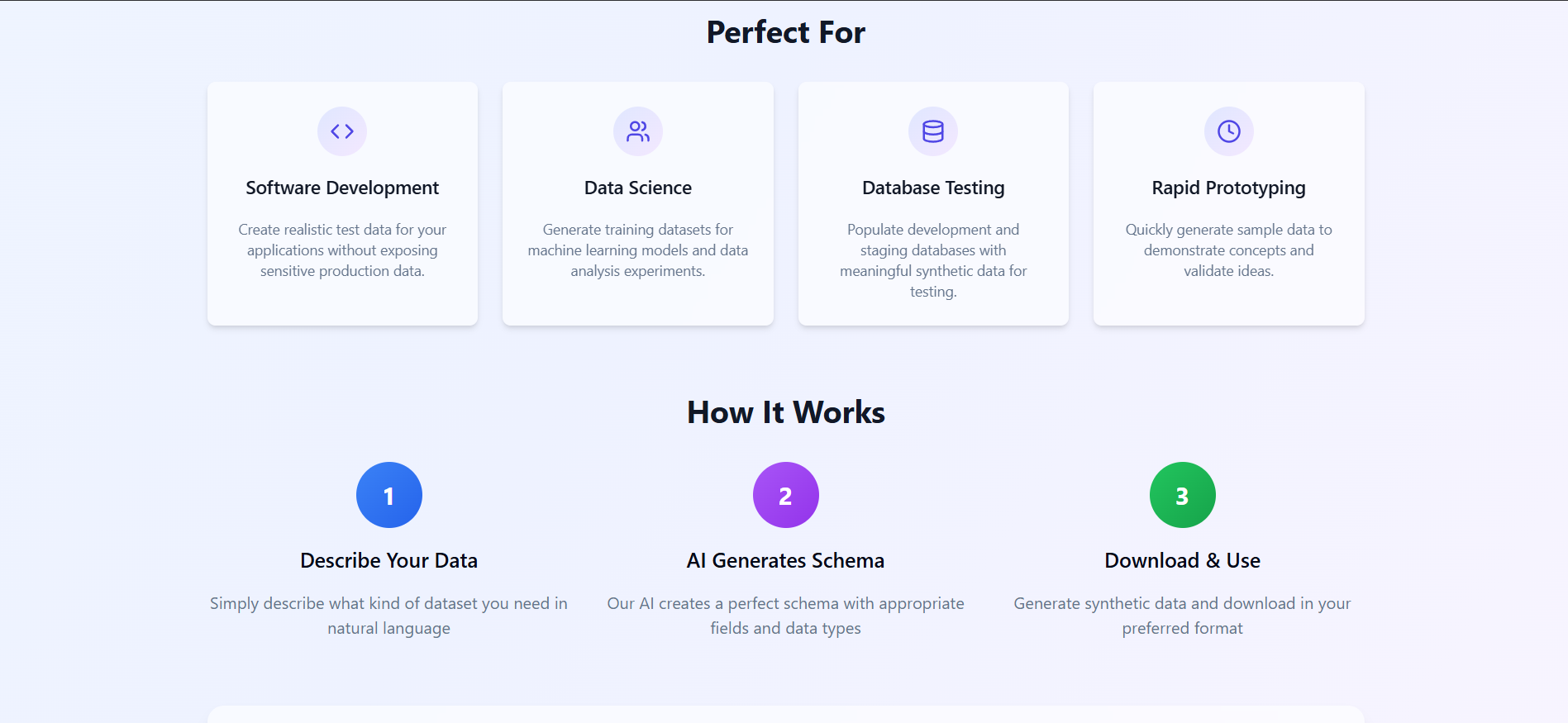
Target
-
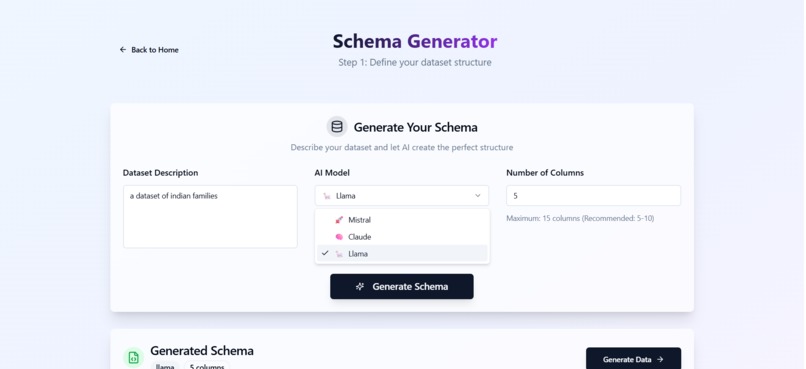
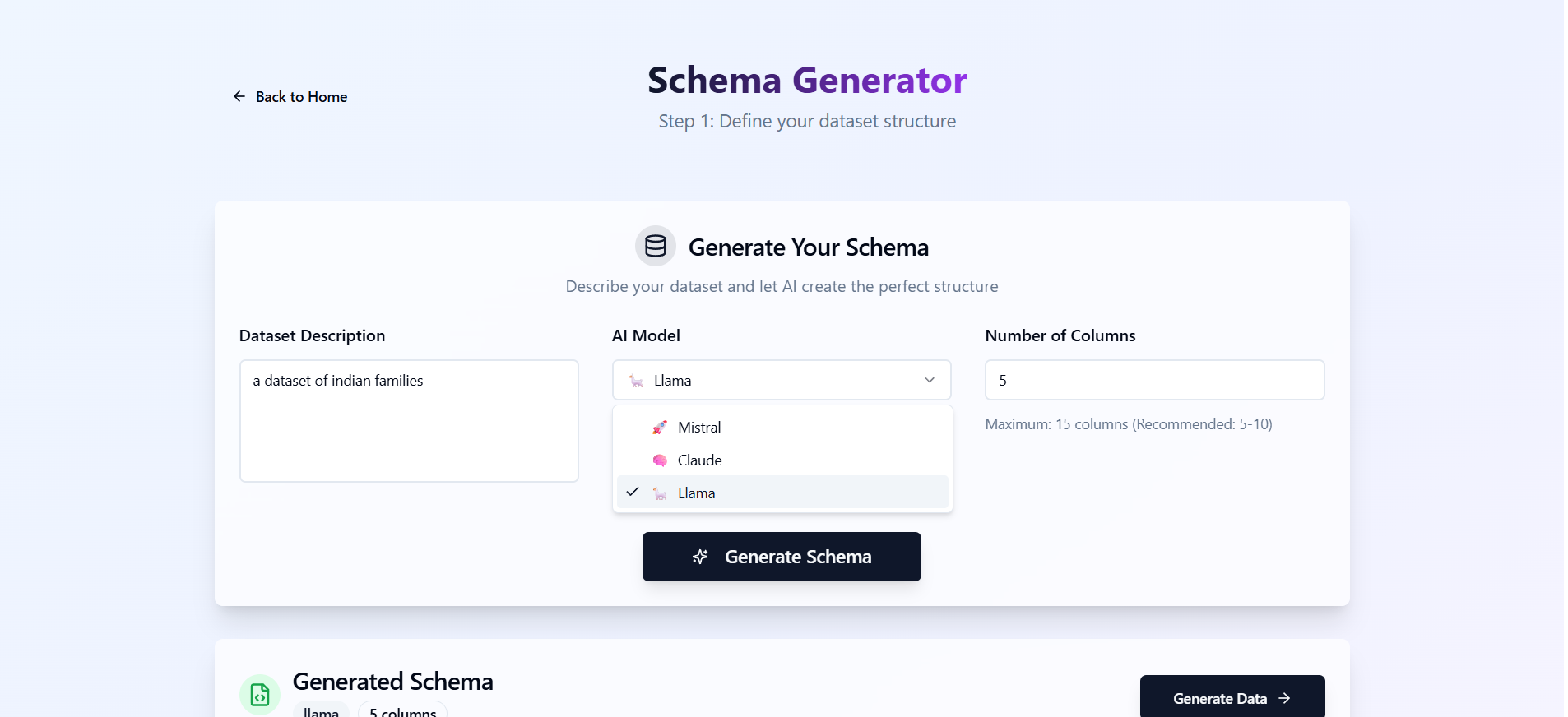
Schema Generation
-
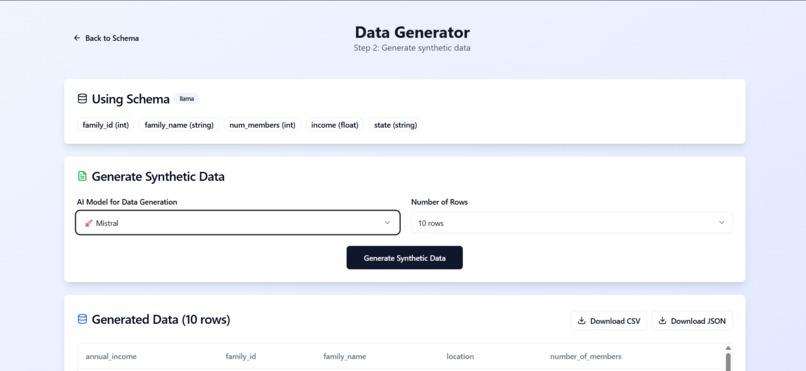
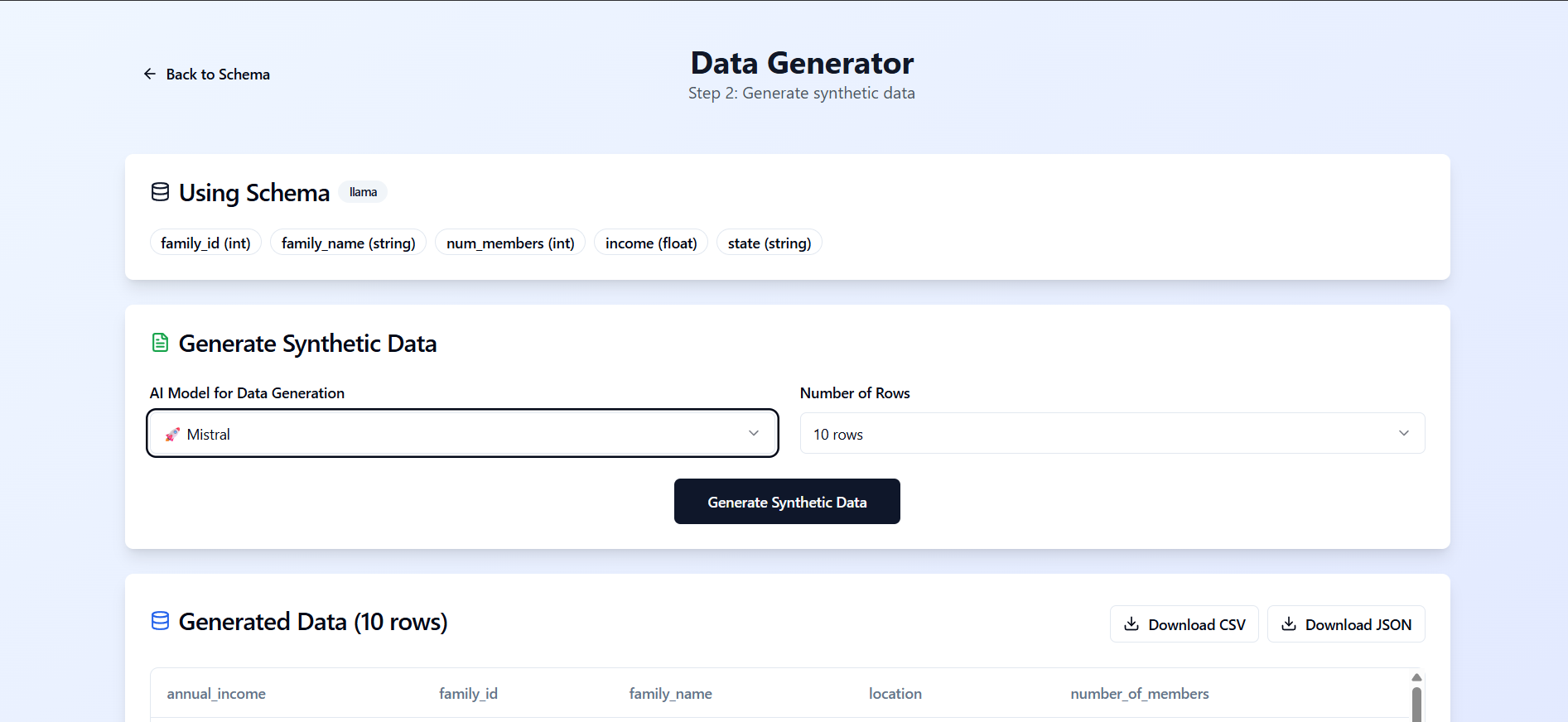
Data Generation

🌟 Inspiration
The motivation behind DataLoom stems from a common bottleneck in AI and data-driven workflows: the unavailability of high-quality, domain-specific, privacy-compliant datasets. Real-world data is often sensitive, incomplete, biased, or simply inaccessible due to legal and privacy constraints. This challenge hampers model training, testing, and rapid prototyping for developers, startups, and researchers.
We envisioned a solution that leverages the power of generative AI to create realistic synthetic datasets from natural language descriptions—instantly, safely, and without friction. That’s how DataLoom was born.
🚀 What It Does
DataLoom is an AI-powered synthetic data generation platform that:
- Accepts a natural language prompt describing a dataset (e.g., “e-commerce transactions with user ID, product, and purchase date”).
- Automatically generates a structured schema using advanced LLMs via AWS Bedrock.
- Allows the user to review or edit the schema.
- Generates realistic, domain-relevant synthetic data based on the schema.
- Lets users download the dataset in CSV or JSON format.
- Runs entirely in the browser—no signup, no barriers.
🛠️ How We Built It
The platform is built with a modern and scalable architecture:
- Frontend: Developed using React, TypeScript, Tailwind CSS, and Vite for a fast and responsive user experience.
- Backend: A Python Flask API that manages orchestration, validation, and communication with AWS Bedrock.
- AI/ML: We used Amazon Bedrock to access powerful foundational models like Claude, Mistral, and Llama for schema inference and data generation.
- Deployment: The app is fully containerized using Docker and deployed on an AWS EC2 instance using Docker Compose for backend/frontend orchestration.
- Security: No user data is stored. All data is generated on-the-fly and is privacy-safe.
🧗 Challenges We Ran Into
One of the major technical challenges we faced was generating large datasets in a single request. Since LLMs have token limits and latency issues, trying to generate thousands of rows at once led to timeouts and performance degradation.
Another challenge was ensuring that the generated schemas and data remained realistic and contextually meaningful for various domains such as healthcare, finance, and retail.
🏆 Accomplishments That We're Proud Of
We are particularly proud of how we solved the data scaling challenge by implementing batch-wise data generation. Instead of requesting thousands of rows in one go, we split the generation into smaller batches and aggregated the results. This significantly improved reliability and responsiveness.
Moreover, the fact that the entire dataset—schema and data—is generated through AI with minimal user input is a strong testament to the robustness of our prompt engineering and architectural design.
📚 What We Learned
Through this project, we gained hands-on experience with:
- AWS Bedrock and its runtime API
- Designing scalable prompt-based systems for structured data
- Efficient batching and orchestration for LLM-based workflows
- Docker-based deployment on AWS EC2
- React- and Python-based full-stack development
The project helped us better understand the constraints and capabilities of large language models in production environments.
🔮 What’s Next for DataLoom
We plan to expand DataLoom with the following key features:
S3 Dataset Storage & Public Collection
All generated datasets will be stored in an S3 bucket and made browsable via the frontend UI. This will allow new users to explore and reuse datasets that have already been generated—eliminating the need to regenerate similar data.Concurrent Batch Generation
To significantly reduce generation time (by 60–80%), we aim to implement asynchronous concurrent batch generation, allowing multiple segments of data to be generated in parallel and merged on the fly.Role-Based Access Control (RBAC)
Optional authentication to allow enterprise users to save, version, and manage datasets securely.
We believe DataLoom can become a foundational tool for synthetic data generation and testing in the AI development pipeline.



Log in or sign up for Devpost to join the conversation.