-
-
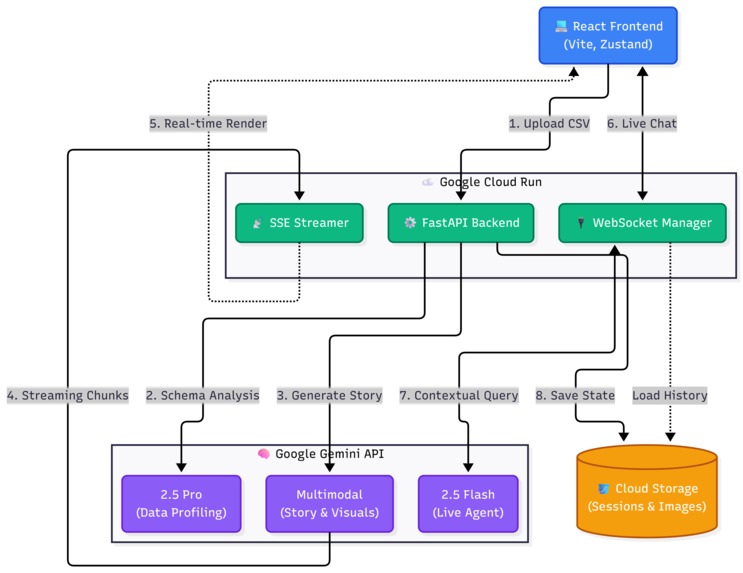
Datalens Architeture
Inspiration
Raw data, whether in CSV or Excel, often obscures the hidden signals within the noise. Traditional BI tools require advanced SQL or DAX knowledge to extract basic insights. We were inspired to build a system that bridges the gap between structured tabular data and human cognition by leveraging Large Language Models (LLMs). We wanted to create an autonomous agent where data exploration is as intuitive as natural language discourse.
What it does
DataLens is an autonomous, multimodal AI agent that transforms structured datasets into interactive visual narratives. Upon data ingestion, the system performs automated EDA (Exploratory Data Analysis), calculating a comprehensive statistical profile: $$ P = { \mu, \sigma, Q_1, \tilde{x}, Q_3, \text{cardinality}, \text{missing_ratio} } $$ This profile $P$ is then vectorized and fed into the Gemini multimodal engine. The agent synthesizes this profile into a coherent "Story"—highlighting anomalous trends and key distributions—while providing a persistent, contextual Chat UI for ad-hoc querying and deep-dive analytics.
How we built it
The application architecture is a decoupled, modern full-stack deployment:
- Frontend Client: Built with React and TypeScript, utilizing TailwindCSS and
shadcn/uicomponents to render a highly responsive, stateful chat and dashboard interface. - Backend Services: A high-performance FastAPI (Python 3.11+) service handles the RESTful API and WebSocket connections for streaming agent responses.
- AI Engine: The core reasoning engine utilizes the Google Gemini Pro API. We engineered custom prompt pipelines to force the LLM to ground its narratives in the pre-computed statistical bounds of the data profile.
- Cloud Infrastructure: The entire stack is containerized and deployed on Google Cloud Platform (GCP). We utilize Cloud Run for scalable, serverless execution, Cloud Storage (GCS) for persistent artifact and chat history retention, and Firestore for real-time session state management.
Challenges we ran into
Handling high-cardinality datasets over HTTP requests initially led to 503 Service Unavailable errors. We had to refactor the ingestion pipeline:
@app.post("/upload")
async def process_dataset(background_tasks: BackgroundTasks, file: UploadFile):
# Offload EDA and profiling to background queue
background_tasks.add_task(generate_profile, file.filename)
return {"status": "Processing initiated"}
Additionally, maintaining continuous, multi-turn conversational context while syncing asynchronous read/writes to Firestore and Google Cloud Storage proved complex. We resolved this by implementing custom state reconciliation logic on the React client.
Accomplishments that we're proud of
We are exceptionally proud of the robust rag_pipeline and the seamless context grounding achieved within the interactive Chat UI. Successfully deploying the containerized microservices architecture to GCP and ensuring reliable, low-latency communication between the unified frontend and the Gemini agent was a significant technical milestone.
What We Learned
We gained deep insights into prompt engineering for structured data, specifically how to mitigate LLM hallucinations by rigidly constraining the generation space using standard deviation and variance metrics from our preprocessing pipeline. We also solidified our understanding of deploying robust, scalable, and stateless microservices on Google Cloud Run.
What's next for DataLens
We plan to implement a dynamic retrieval-augmented generation (RAG) system capable of querying live SQL databases via custom LangChain tools. We are also exploring the addition of automated anomaly detection using Isolation Forests before feeding the data profile to the LLM agent.


Log in or sign up for Devpost to join the conversation.