-
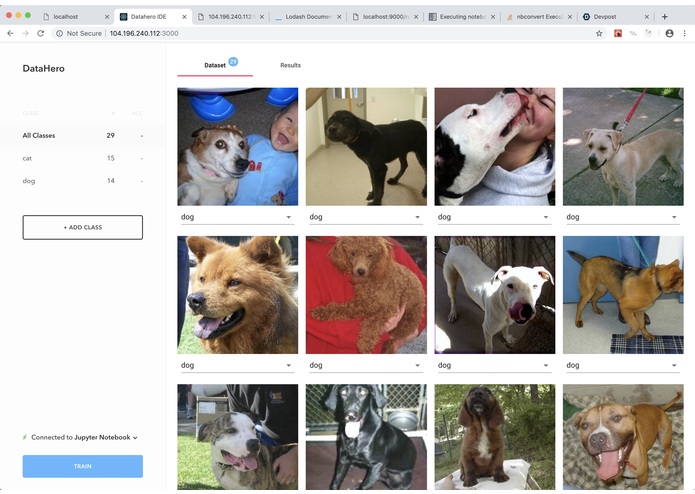
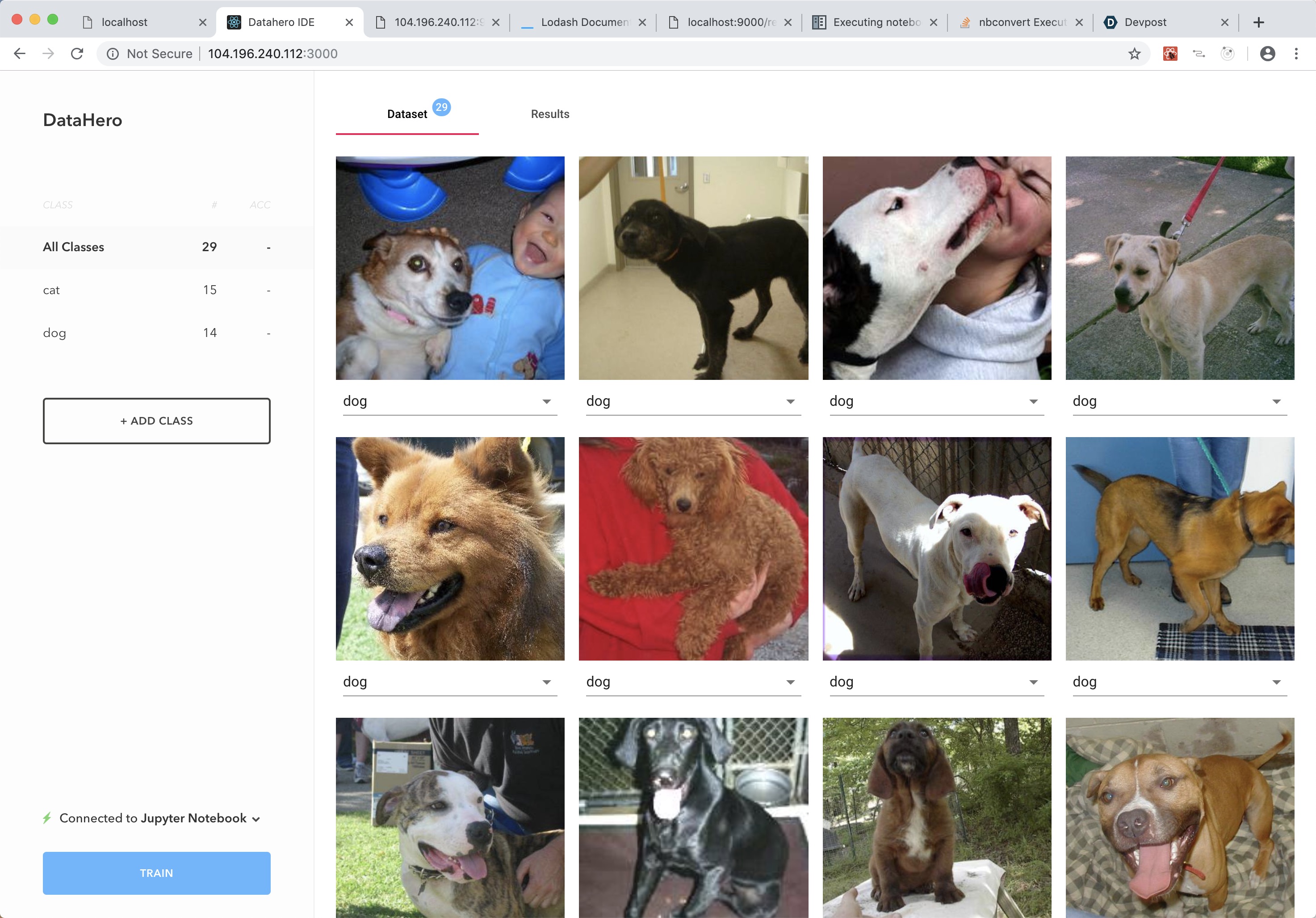
dataset
YC Hackathon 3.0
Problem
There’s no good tooling for creating and growing image datasets for machine learning.
You’re forced to use notebooks, scripts, or do it all via the command line. “Sharing data” means sending a 100gb zip file. There’s no version control to speak of.
Getting to a good model involves a lot of iteration - here’s what a typical cycle looks like:
1. Get some images
2. Label the images with a class
3. Split the images into training and validation sets
4. Train the model
5. Figure out which images/classes the model was worst at predicting
6. Go find more images to handle these cases
7. Start again from (2)
There are no good public tools for this (but probably some nice internal tools at Tesla, Google, etc).
Existing workflows
1. Create imagenet-style folders, where folder names are labels, and images are inside. Do the train-valid split via top-level “train” and “valid” folders.
* Really easy to work with
2. Create train.csv and valid.csv files, where each line corresponds to a file in an `images` folder.
* Can easily extend to multilabel classification
If you’re doing the training on your local machine, you’re good to go. If you are training in the cloud, then you’ve got an extra step of uploading/syncing this dataset to the your machine before you can train. You also have to do this for all your changes!
Solution - hackathon MVP
A simple react app that helps you create and iterate on an image dataset. Specifically, you can: * Upload images * Label images (for single-label image classification problems) * Do your training (fast, pytorch, keras, wherever you like) * See which images your model is performing worst on * Add more examples to cover those cases * Retrain and continue
With this tool, you should be able to create a dataset in minutes, send it wherever you need to train in seconds, and keep iterating on it extremely quickly.



Log in or sign up for Devpost to join the conversation.