-
-
-

Login/Home Page
-
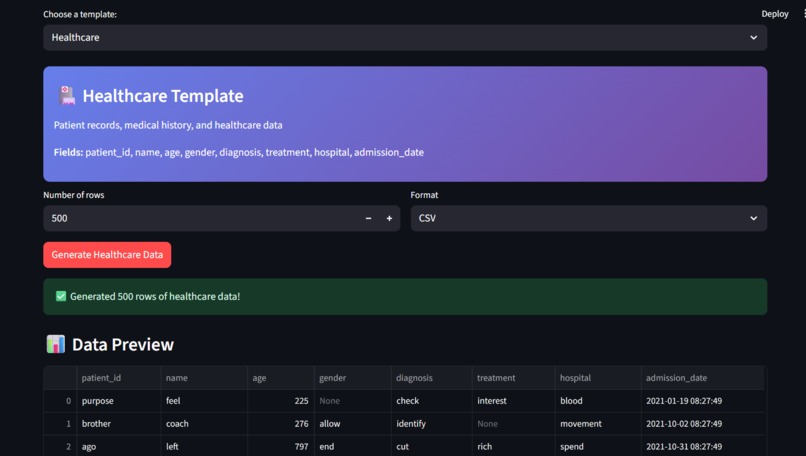
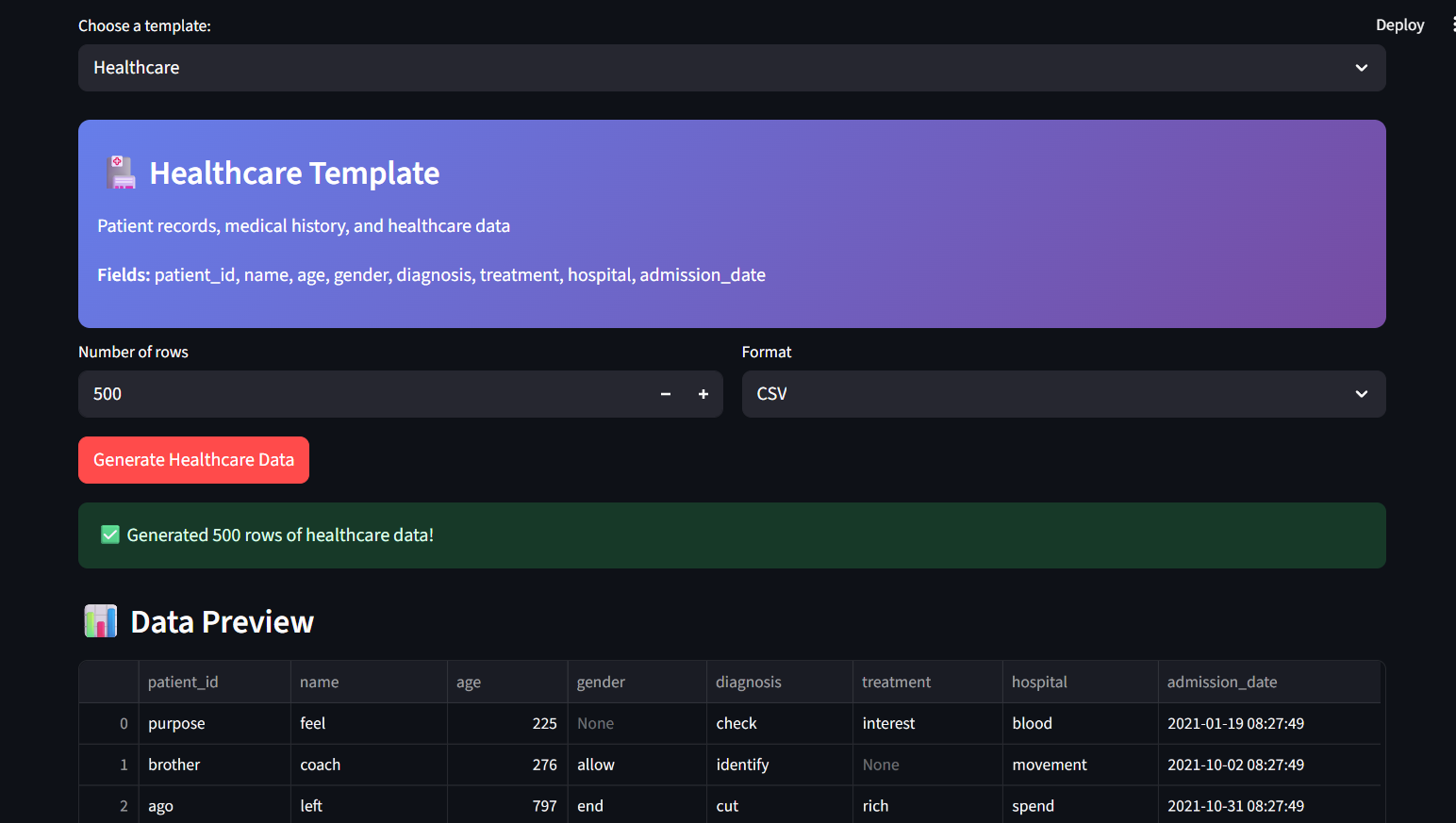
Generate Synthetic Data


Inspiration
The rapid growth of AI and machine learning has created a huge demand for high-quality, privacy-safe datasets. Real-world data is often sensitive, hard to access, or heavily regulated. DataForge AI was inspired by the need for a tool that empowers developers, data scientists, and organizations to quickly generate realistic, customizable tabular data for demos, model training, and software testing—without risking private information or compliance issues. The project draws on the best practices and lessons from hackathons where synthetic data accelerates prototyping and innovation while protecting privacy
What it does
Natural Language to Data: Users enter plain-English prompts (e.g., “Generate 500 rows of patient records for a hospital in India with balanced gender and 10% noise”).
Schema Inference: The app parses the prompt, infers the schema, constraints, and data types.
Synthetic Data Generation: Using libraries like Faker and SDV, it generates realistic tabular data matching the prompt.
Instant Preview & Export: Data is displayed in an interactive table with metrics. Users can export datasets as CSV, JSON, or Excel.
Streamlit Front-End: Built a multi-page UI in app.py for a smooth, interactive user experience.
Prompt Parsing: Developed prompt_handler.py using regex and keyword extraction (LLM-ready) to interpret user instructions and extract schema details.
Data Engine: Created data_utils.py leveraging Faker and SDV for flexible, high-fidelity data generation, including noise injection and constraint enforcement.
Templates & Export: Added pre-built schemas and robust export functions for CSV, JSON, and Excel.
Documentation & Architecture: Provided a comprehensive README.md and a clear architecture diagram.
Cloud Deployment: Ensured compatibility with Streamlit Cloud and AWS EC2 for easy deployment and scaling.
Challenges We Ran Into
Prompt Complexity: Accurately parsing diverse natural language prompts to infer correct schemas and constraints was a major technical hurdle.
Balancing Realism & Privacy: Generating data that is realistic enough for ML training but never risks leaking or mimicking real records required careful design and testing.
Noise Injection: Implementing noise and null value injection without breaking data integrity or usability.
Cloud Compatibility: Ensuring all dependencies worked seamlessly on both Streamlit Cloud and AWS EC2 environments.
Performance: Generating large datasets quickly and efficiently, especially for edge-case prompts with high row counts or complex constraints.
Accomplishments That We're Proud Of End-to-End Automation: Built a tool that transforms a single prompt into a full-featured, exportable dataset in seconds.
Domain Flexibility: Supported multiple industries and use cases with pre-built templates and customizable prompts.
LLM-Ready Architecture: Designed prompt parsing to be easily upgraded from regex to LLM-based extraction for future-proofing.
User Experience: Delivered an intuitive, multi-page UI with instant feedback, previews, and export options.
Cloud Deployment: Achieved smooth, one-click deployment on Streamlit Cloud and AWS EC2, making the tool accessible to a wide audience.
What We Learned
Prompt Engineering Matters: Even with advanced models, the quality and clarity of prompts directly impact output quality. Iterative testing and prompt refinement are key.
Tooling Flexibility: Providing both code-based and UI-based schema customization meets the needs of both technical and non-technical users.
Validation is Crucial: Automated schema validation and data quality checks catch issues early, ensuring reliability.
Community Feedback: Early user testing surfaced edge cases and usability improvements that shaped the final product.
Cloud-Native Design: Building for cloud deployment from day one avoids last-minute surprises and expands reach.
What's Next for DataForge AI
LLM-Powered Parsing: Integrate Amazon Bedrock, OpenAI, or Gemini for even more robust schema extraction from complex prompts.
Domain-Specific Templates: Expand template library to include IoT, Education, Logistics, and more.
Advanced Analytics: Add data profiling, visualization, and synthetic data quality scoring.
Security & Compliance: Enhance with AWS KMS encryption, IAM roles, and content moderation for enterprise deployments.
API Access: Offer a REST API for programmatic dataset generation and integration with other ML pipelines.
Community Contributions: Open-source the project and invite contributions for new templates, features, and integrations.
DataForge AI is ready to accelerate your next GenAI hackathon, demo, or ML project with fast, safe, and customizable synthetic data generation.

Log in or sign up for Devpost to join the conversation.