

Inspiration
ML models are built on top of data. However, the process of collecting, aggregating and labelling this data is done by large private companies. However, this data directly impacts the decisions by ML models. Thus, I wanted to try to make the process of data labelling and eventually the entire process of data aggregation and preprocessing more accessible and democratic to encourage transparency and reduce bias.
What it does
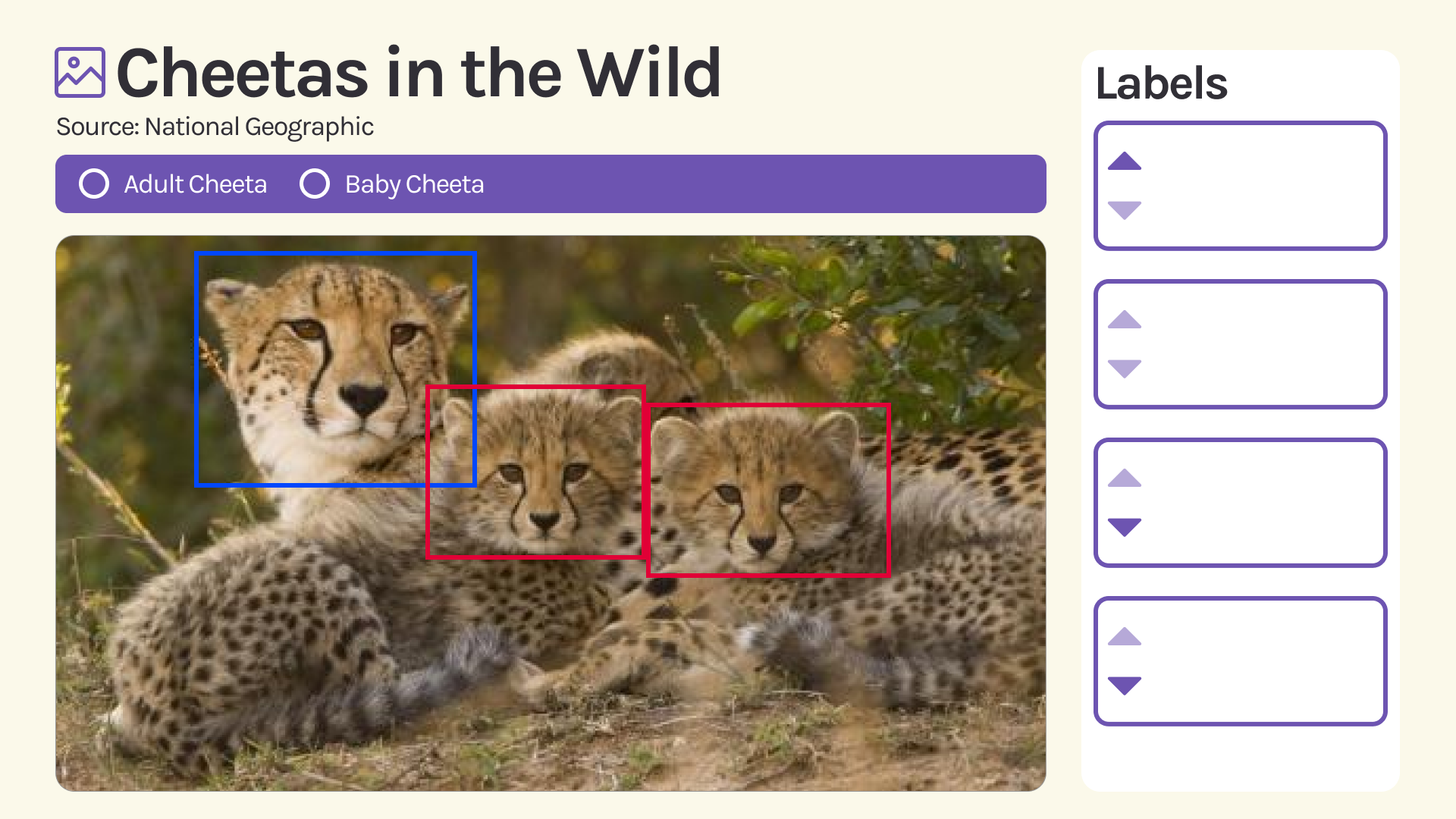
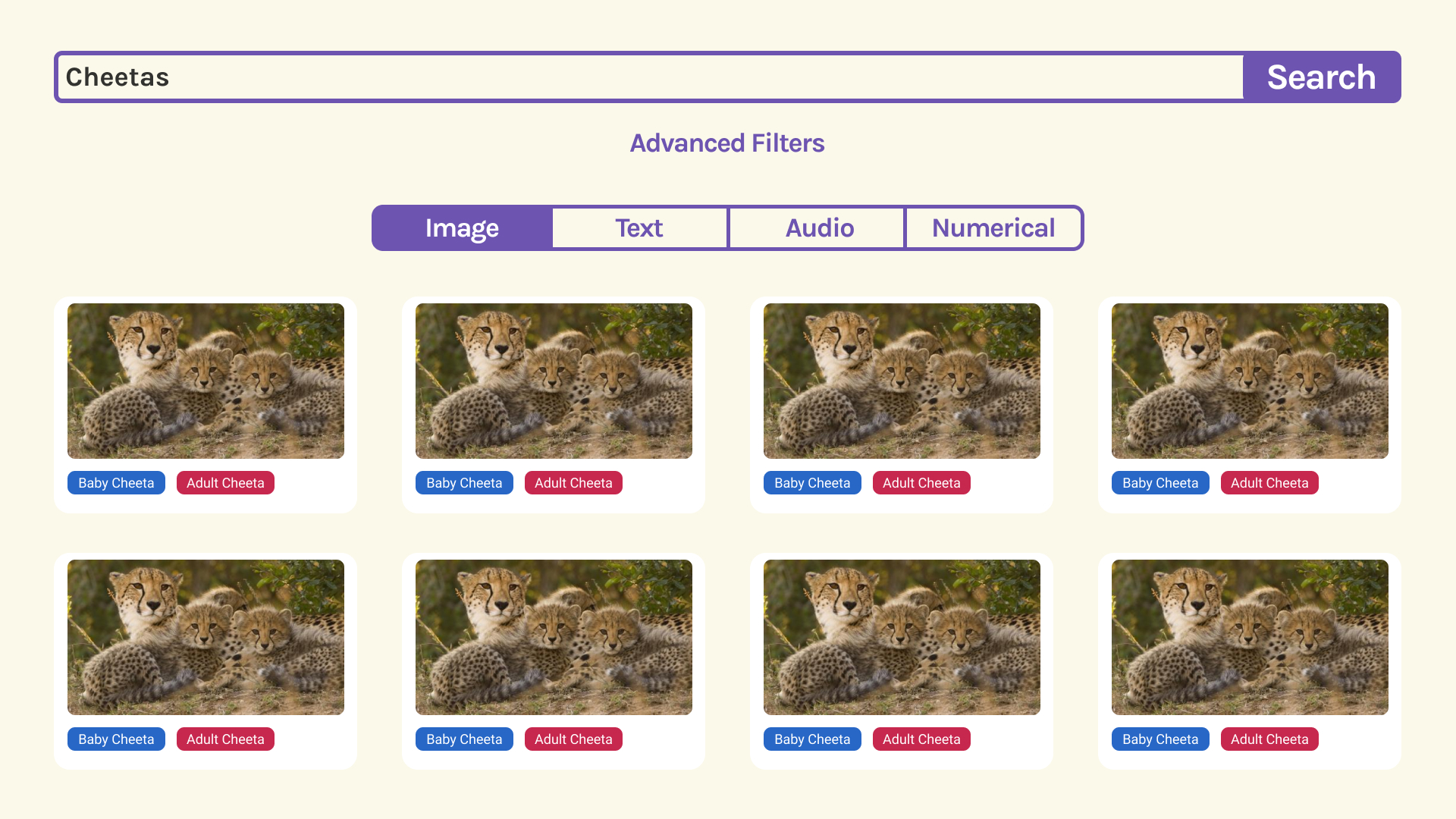
Allows users to put in the URL of an image and from there label it into distinct classes by creating a bounding box. Users can pull open-source data like images and label it. The same data can be labelled in many different ways to encourage diversity.
How I built it
Only the Frontend is functional right now. Frontend: React, Canvas API
Challenges I ran into
A lot of learning regarding the canvas API and a lot about how data processed.
What I learned
React Hooks (first time trying them out), Canvas API.
What's next for Dataforest
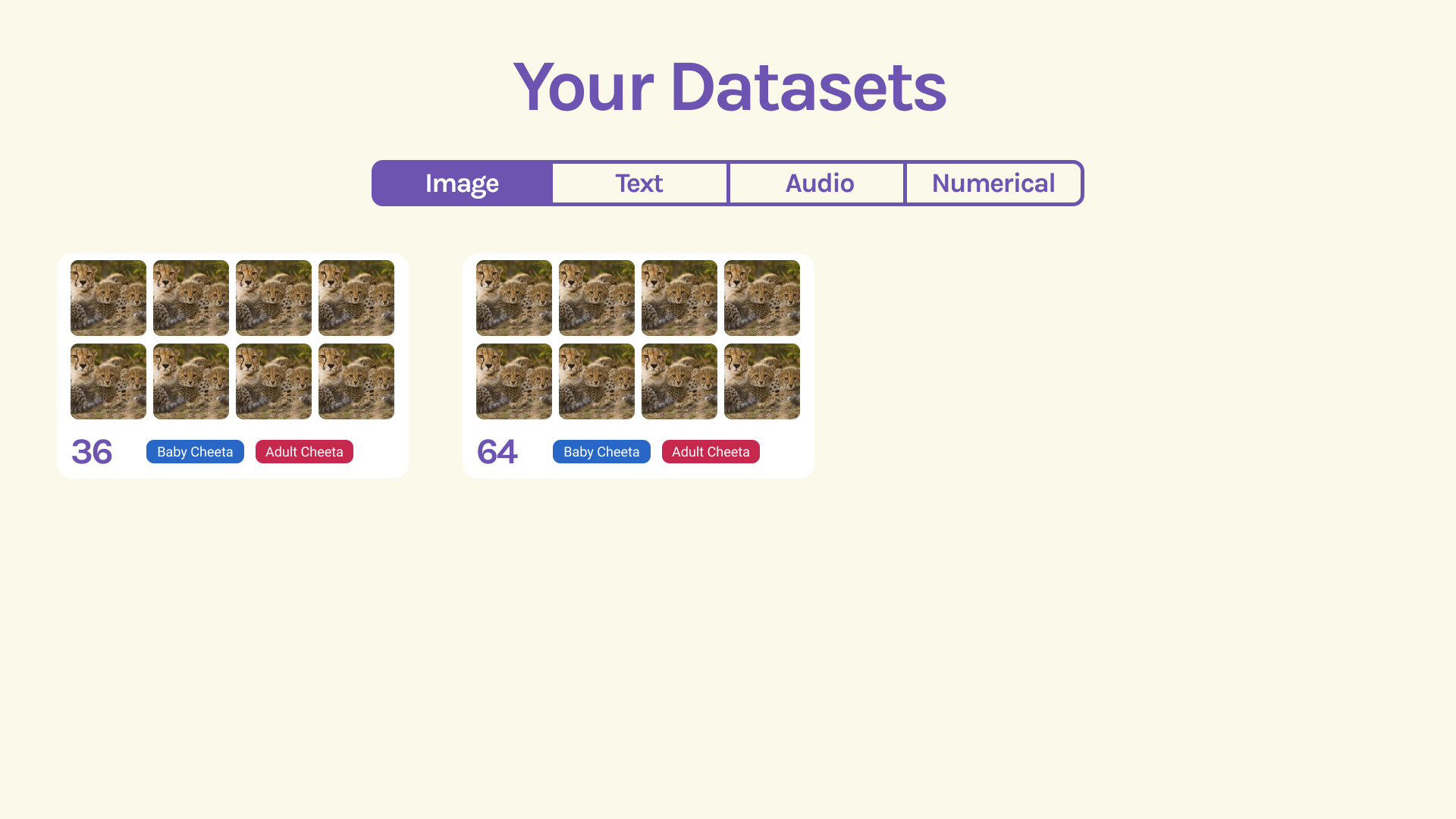
Start its open-source development, build out the backend, implement community features like up and down votes for labels, allowing users to build their own datasets and supporting different types of data part from just images (text, numerical, audio, etc) and different labelling methods (segmentation, etc)

Log in or sign up for Devpost to join the conversation.