-
-
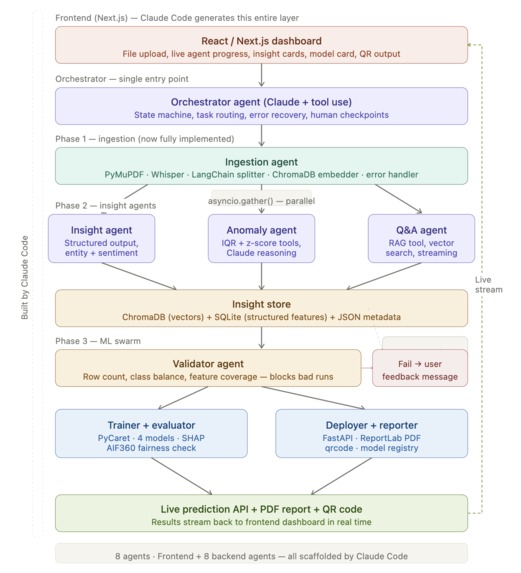
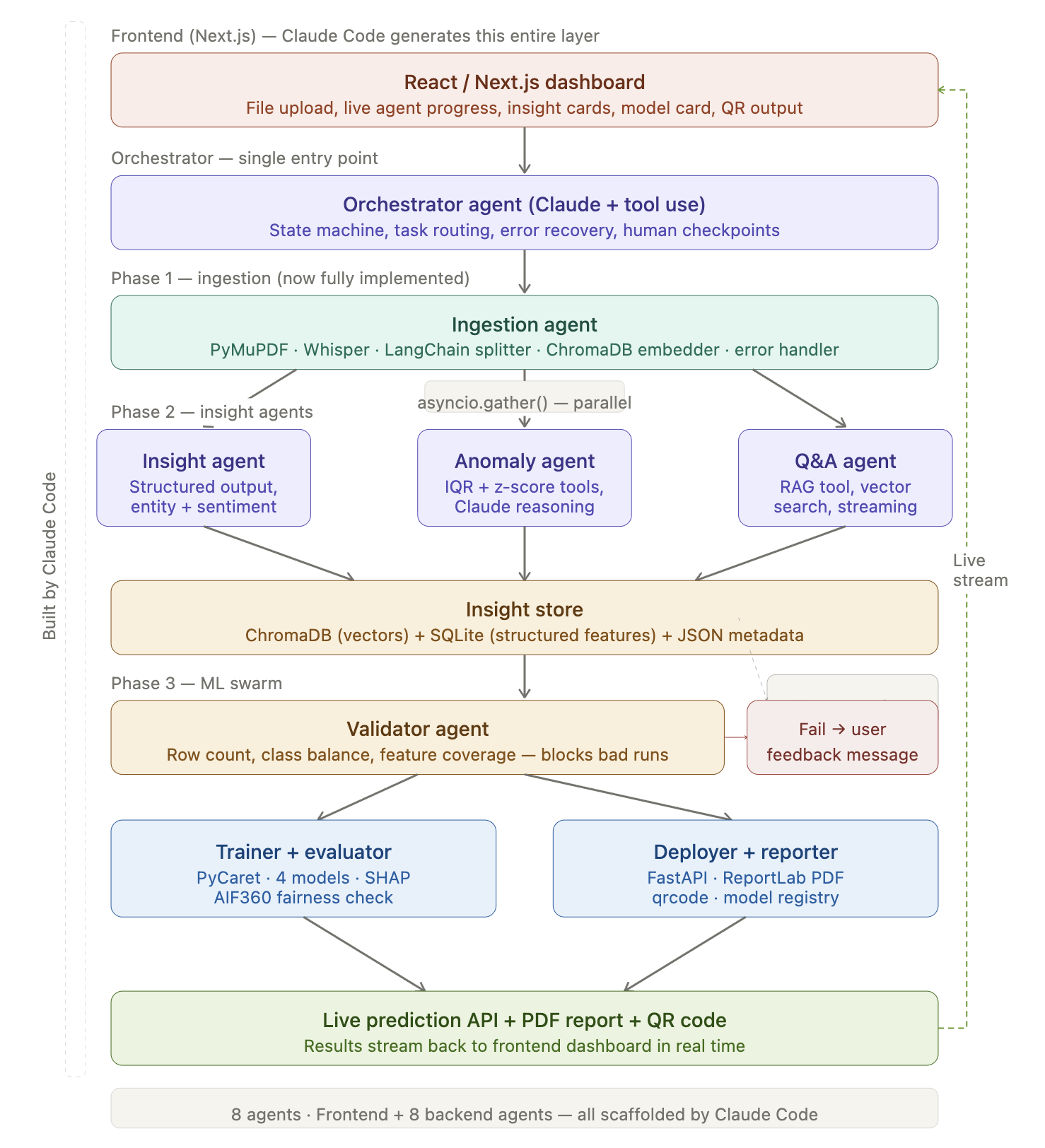
architecture build by claude
-
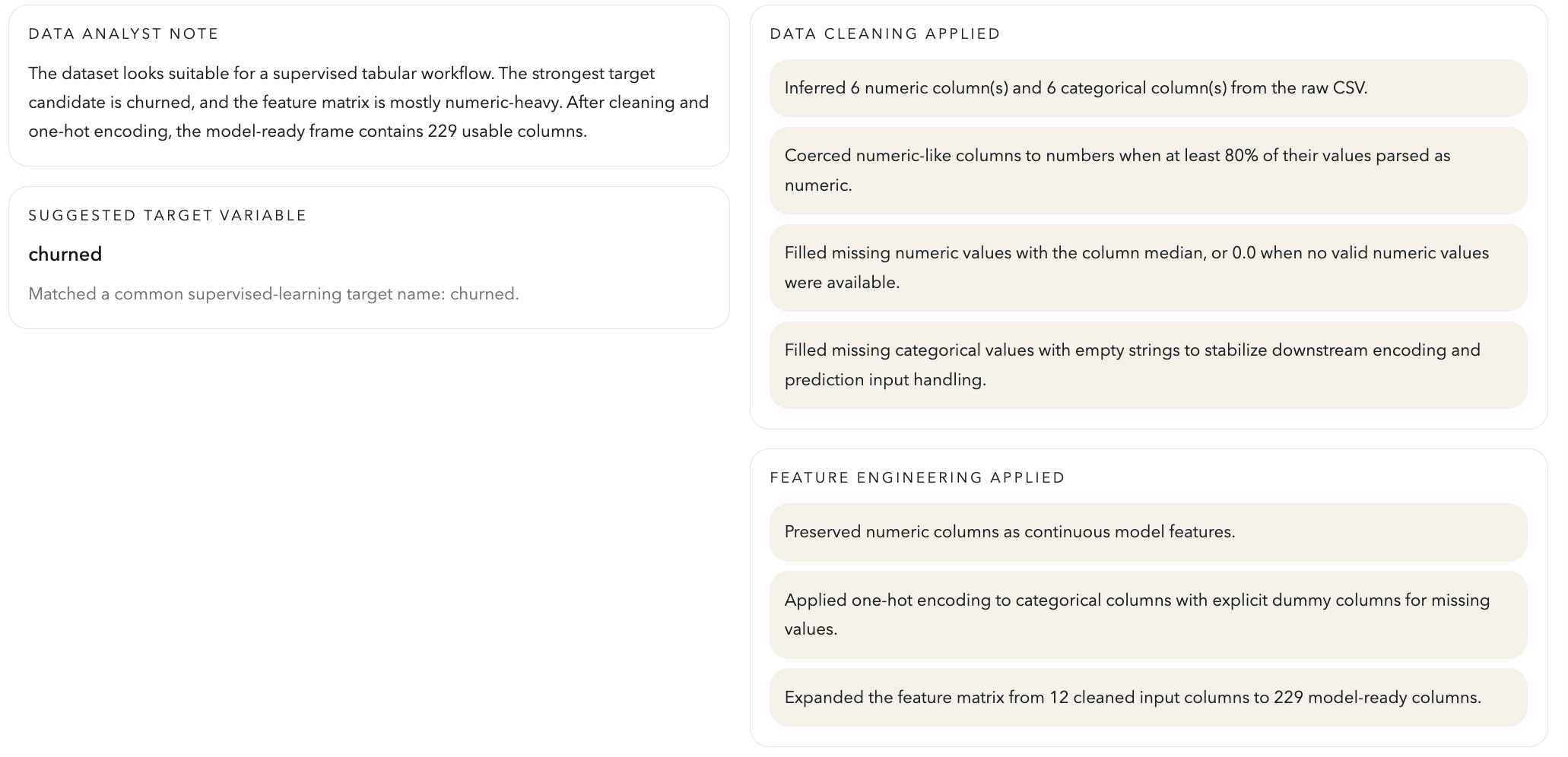
Test dataset
-
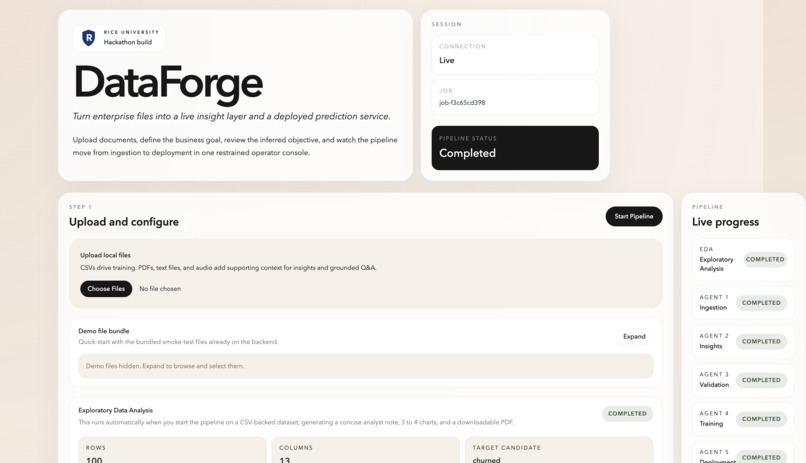
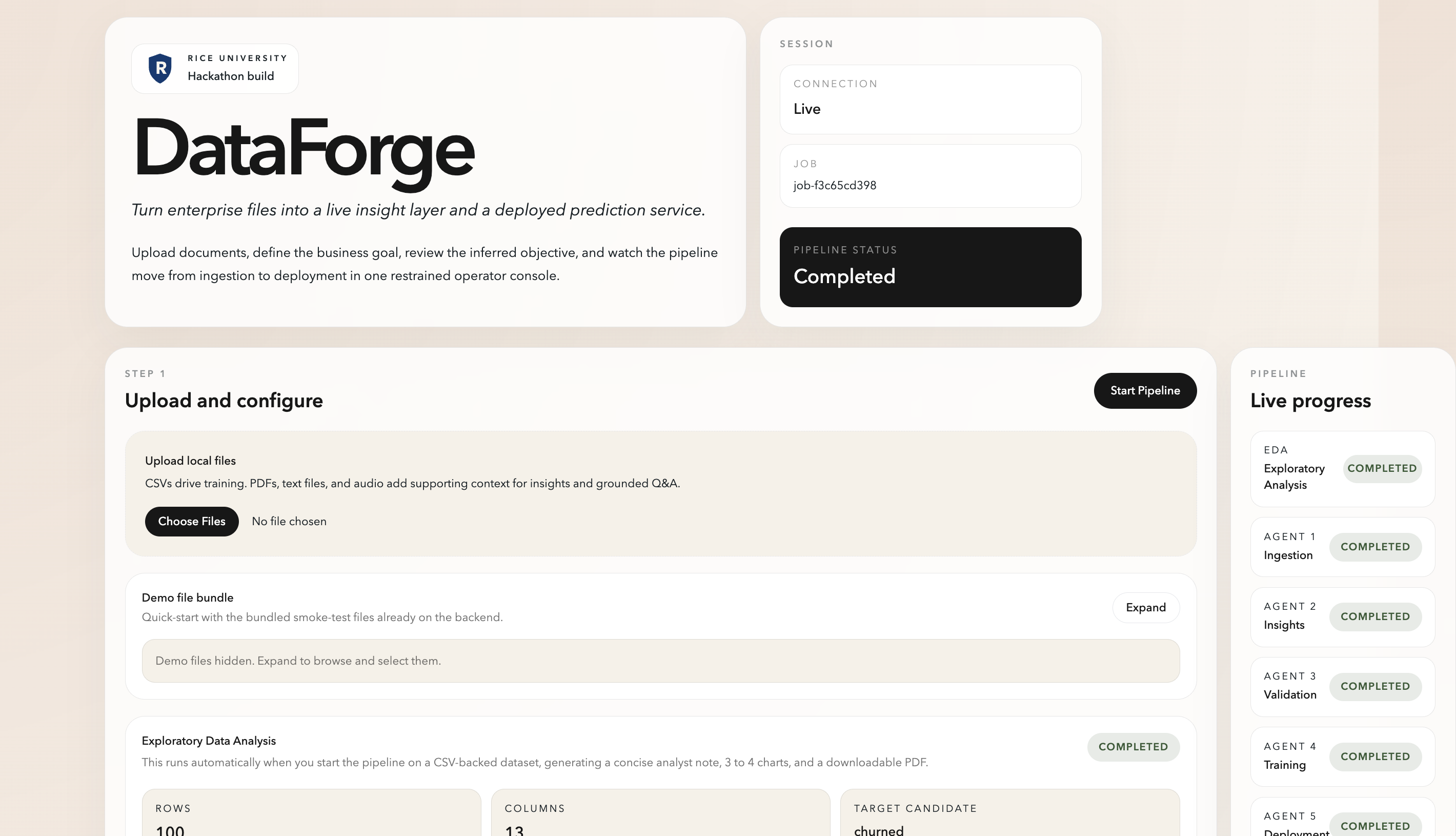
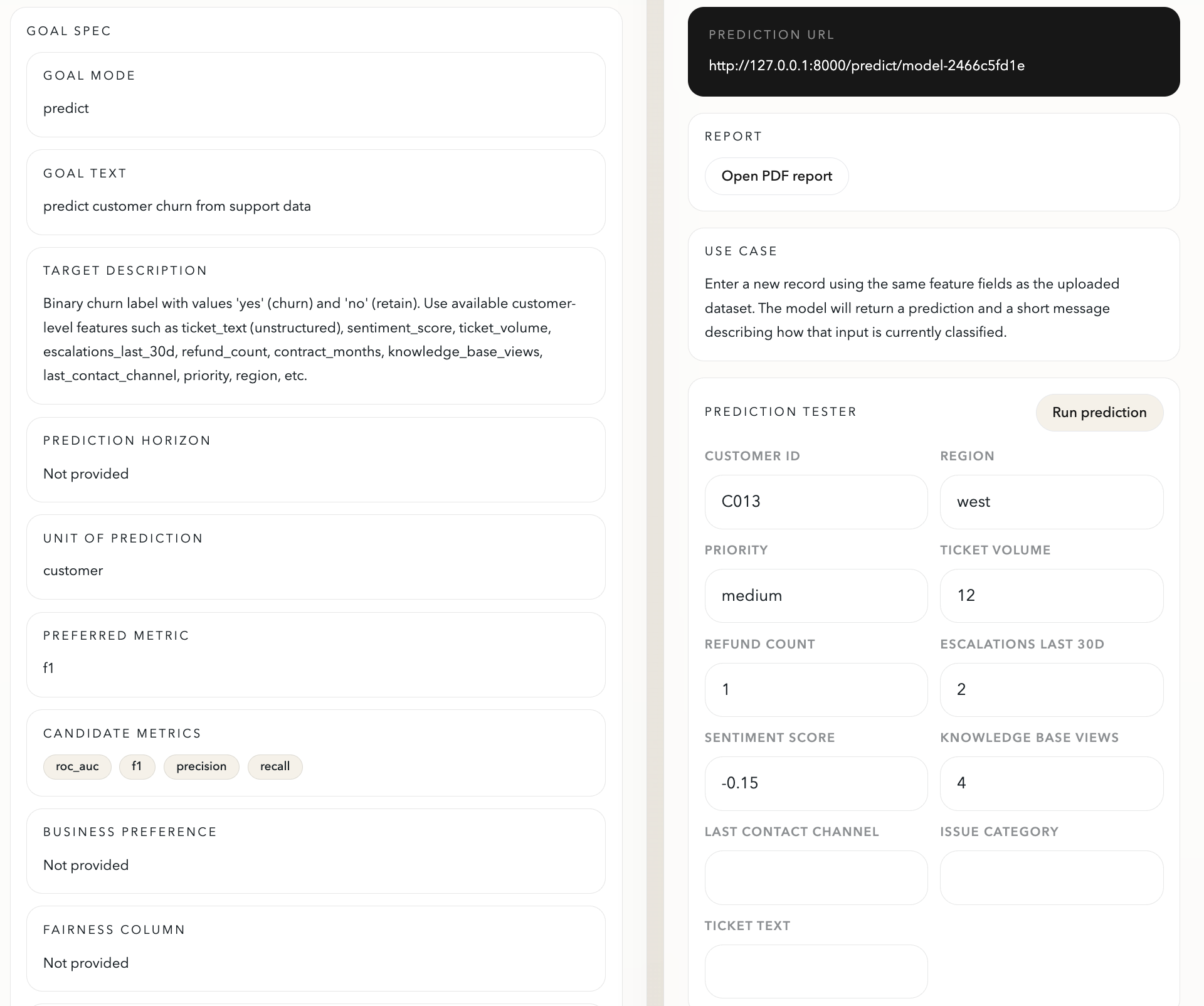
the dashboard
-
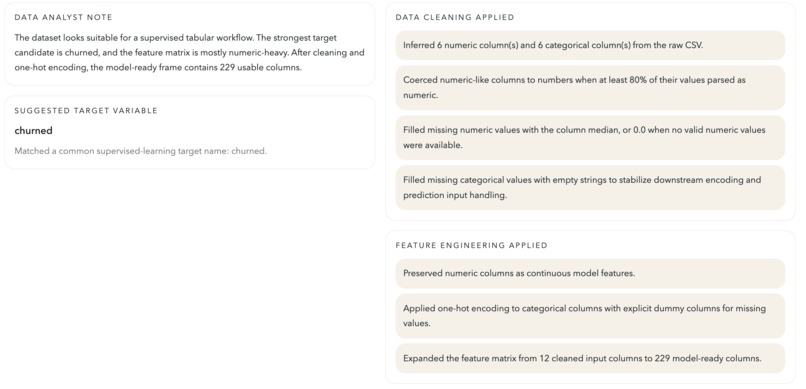
-
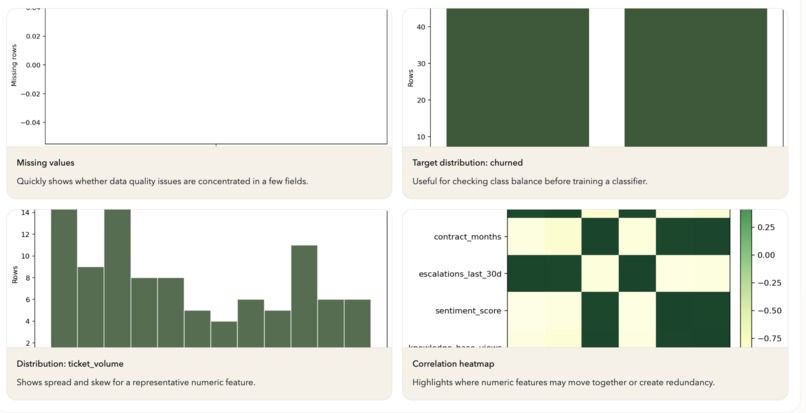
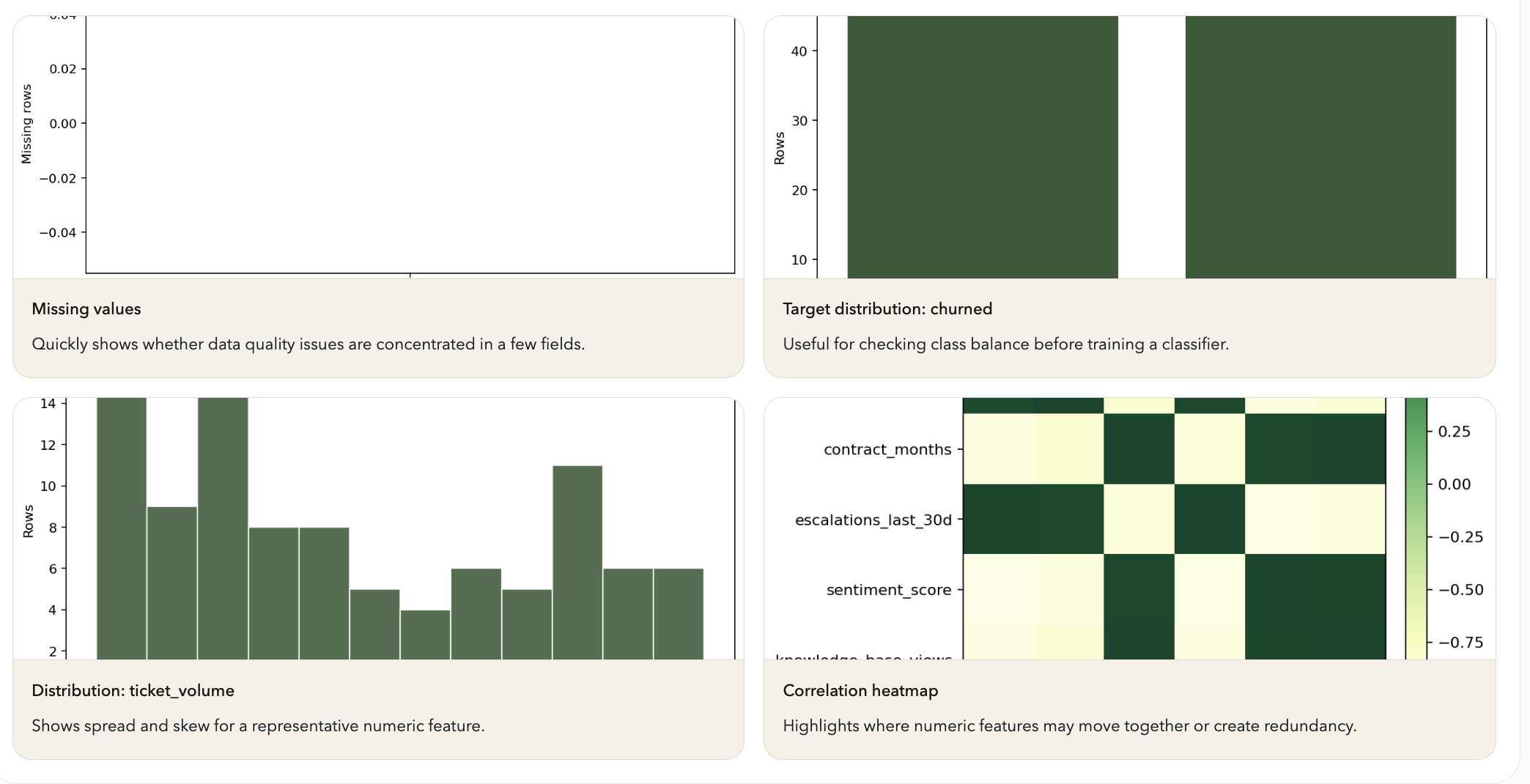
Visualization generated
-
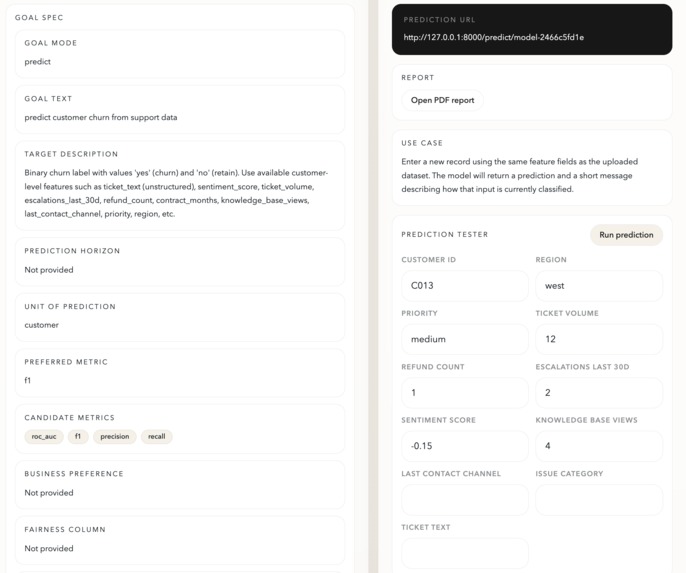
Trained model and applied use case
-

solution recommended for business

The Ideas
Companies are sitting on piles of data — chat logs, PDFs, screenshots, and recordings — but can't do much with it. Existing tools are typically built for a single data format, or they require too much manual work. This makes it hard to find patterns, generate content, or even answer basic questions.
So I asked myself: why not leverage Claude's AI capabilities to process unstructured or mixed-format data and turn it into insights and predictive tools? That might mean surfacing similar documents from a large text archive, generating summaries on the fly, stitching together insights from messy mixed-format data, or building a prediction model. Whatever data we have, the idea is to solve business problems using tools that feel like a natural extension of SQL and Claude Code — not a separate system.
The problems
According to Gartner, 80–90% of all new enterprise data is unstructured — and it's growing three times faster than structured data. We're talking about emails, call recordings, PDFs, contracts, support tickets, sensor logs — data that companies generate every day but can't easily analyze.
95% of businesses recognize unstructured data management as a significant problem, with 71% struggling with protection and governance. And it's getting worse: most enterprises (74%) are now storing more than 5 petabytes of unstructured data — a 57% increase over 2024 alone.
The financial cost is real too. More than 30% of IT budgets in many organizations go purely to data storage and management, and the IBM Cost of a Data Breach 2023 report put the average cost of a security breach at $4.45 million — largely driven by uncontrolled unstructured data.
The cruel irony? Only 10% of generated data will even be stored, let alone analyzed — the rest becomes "dark data": generated but unused.
What it does
The core idea can be stated in one sentence:
Turn any pile of unstructured enterprise data into a live, queryable insight layer and a deployed predictive ML model — without a single line of code or a single data scientist.
It works in three phases that flow into each other naturally. Phase 1 ingests everything — text, audio, images, PDFs, logs — and normalizes it. Phase 2 deploys a swarm of AI insight agents that extract meaning: sentiment, topics, entities, anomalies, and summaries. Phase 3 lets any non-technical employee simply ask "train a model to predict X from this data" — and within 90 seconds receives a live prediction API, a SHAP explainability report, a fairness check, and a QR code to share it.
The insight store that sits between Phase 2 and Phase 3 is the secret weapon: by the time the ML swarm receives the data, it's already enriched with sentiment scores, topic tags, and classifications — making the resulting models far more powerful than anything trained on raw CSVs alone.
How we built it
I built everything in this project using Claude Code — Claude Sonnet 4.6 for generating ideas and architecture, and Opus 4.6 for coding and debugging.
First, we gave Claude the problem and our intention, and asked it to generate an architecture for us.
Next, we asked Claude Code to generate a build_plan.md for us:
Here is a quick example of build_plan.md:
## Build Steps
### Step 1 — Project Scaffolding
Set up both apps and install all dependencies.
- **Backend:** FastAPI, uvicorn, aiosqlite, pydantic-settings[dotenv]
- **Frontend:** Next.js 14, Tailwind CSS
- **Config:** `.env` with `ANTHROPIC_API_KEY`, paths, `WHISPER_MODEL=base`
---
### Step 2 — Storage Layer
Create the insight store that sits between Phase 2 and Phase 3.
- **Vector store:** ChromaDB — one collection per job (`docs_{job_id}`)
- **Structured store:** SQLite via aiosqlite — tables: `jobs`, `documents`, `features` (with `target_label` column for ML), `insights`, `models`, `sse_events`
- **Note:** `features.target_label` is the ML target value; only rows from labeled CSVs have it populated
---
### Step 3 — Phase 1: Ingestion Agent
Parse, chunk, and embed all uploaded files into the insight store.
- **PDF parsing:** PyMuPDF
- **Audio transcription:** openai-whisper (run in `ThreadPoolExecutor` — blocking)
- **Text chunking:** LangChain `RecursiveCharacterTextSplitter`
- **Embedding + storage:** ChromaDB (sentence-transformers for embedding)
- **Metadata + labels:** aiosqlite — for CSVs, detect and store the target column as `target_label`
- **Agent:** Anthropic SDK (Claude + tool_use), asyncio
For most of the coding, we use Claude Code Opus 4.6 for generate code and debug
For example: Here's the fixed sentence: I asked Claude Code to use Claude's Data Analyst mode to generate an EDA, and received the following instructions:
• I’m moving recommendations out of the frontend heuristic path and into the backend so they can be generated with
Claude Sonnet from the actual training outputs. I’ll reuse the existing Anthropic routing pattern rather than bolting
on a separate client.
• I’ve got the existing model signals. Next I’m adding a backend recommendation task routed to Anthropic, then I’ll wire
the UI to prefer those Claude-generated recommendations and fall back to the current local heuristics only if Claude
is unavailable.
• Explored
└ Read PipelineStudio.tsx
Search buildBusinessRecommendations|topModelDrivers|recommendationForFeature|Business recommendations in
PipelineStudio.tsx"
Challenges we ran into
Working with different types of unstructured data (PDFs, audio, text, logs) in one pipeline was challenging. We also had to turn AI outputs into structured features that actually improve ML models, not just summaries. Keeping the system fast while doing all of this in ~90 seconds was another key challenge.
What's next
As this is a base model, we plan to build upon this project by incorporating a more robust model to improve accuracy and usability.










Log in or sign up for Devpost to join the conversation.