Inspiration
We decided to try Finra's Analytics challenge. It is currently a huge problem to find valuable insights when the only source you have is very large dumps of noisy data, like the 60 GB set we were given for this hackathon.
What it does
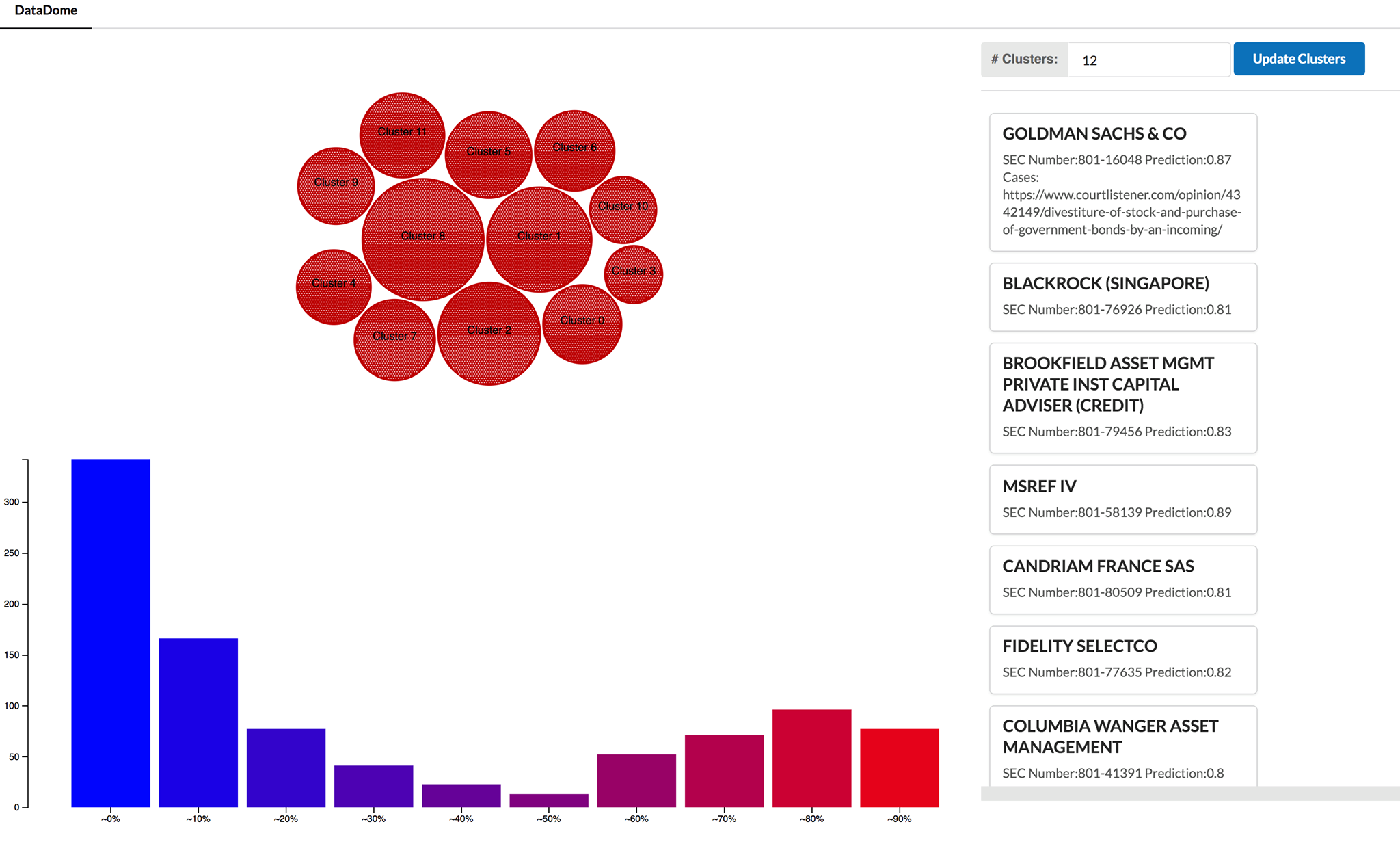
Datadome is a web app which allows analysts and engineers to explore the massive IADB dataset and related court data. This data includes gigabytes of SEC form submissions including hundreds of features such as the size of a firm, whether a firm operates outside the US, the number of broker-dealers and investment advisors, and whether they have been charged and convicted of a crime in the past.
By parsing and extracting this data, we use k-means clustering to clump similar firms together and a random forest regression learner to predict how likely a firm is to be charged or convicted of a crime in the future. Our model has 86% accuracy with a 32% true positive rate and 93% true negative rate. We visualize these clusters in our web app using D3.js, and allow users to select these clusters to view a histogram of classifier predictions for all firms in that cluster. This threat distribution gives an idea of how suspicious firms are.
How we built it
After using python to parse and clean large amounts of data, we used SciKit-Learn to highlight patterns and cluster data based on certain attributes that we found interesting. Then, we used d3.js to create a clear data visualization tool that highlights these patterns and cleanly displays useful information to the user.
Challenges we ran into
There was simply too much data to work with, that we did not have enough processing power to effectively extract and analyze through datasets in its entirety. To work around this, we had to work with the data we were able to get our hands on and try to identify patterns with the limited amount of data.
Accomplishments that we're proud of
We were able to create a fully functional web application that looks clean, and also gives us a lot of useful information about patterns in the data.




Log in or sign up for Devpost to join the conversation.