Your friendly neighborhood DataBot
Inspiration
Let's start with a story. Joe and Jane has a weekly staff meeting with Alexa and a big screen in the room.
- Joe: Alexa, which tickets are due tomorrow?
- Alexa: There are 5 tickets due tomorrow.
- Alexa updates screen to show the 5 tickets in question
- Jane: Alexa, of these, which are critical?
- Alexa: There are 2 critical tickets due tomorrow.
- Alexa updates screen to show the 2 tickets in question
- Joe: Jane, I need you to fix this! Alexa. assign these to Jane...
- Alexa: Assigning 2 critical tickets due tomorrow to Jane...
- Jane sighs and leaves the room
Introduction
What if you could have Alexa with you in a meeting and just ask her to display data using natural language?
Your friendly neighborhood DataBot, is an experiment in how a user interface for exploring data via natural language could work. How it could be a operational tool to augment your and your teams decision making.
And before you get too excited, this is only a first small step.
What it does
It takes a question through Slack, interprets it and retrieves data from ZenDesk.
E.g. to check if there are any tickets which requires your attention
- Do we have any open critical tickets?
- Were there any tickets due during last 7 days? ### E.g. to do some basic calculations
- What is the average age of open tickets?
- What is the average age of open tickets created during last 7 days? ### E.g. or just to view them
- Which tickets were created during last 2 weeks?
- Which tickets are due tomorrow? ### And finally, you can ask to view them
- Can I see them?
- Show me
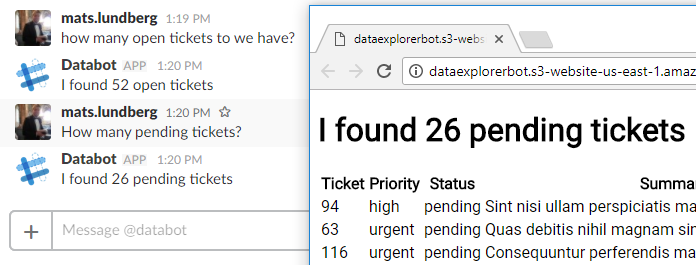
These will give you a link to a Results viewer, which is kept up-to-date in real-time.
How it works
There are two main parts in the DataBot,
- Bot/natural language interface - Main interface for interacting with DataBot
- Results viewer - Web page where results can be viewed, kept updated in "real-time".
Bot/natural language interface
User enters something in Slack which forwards this to an AWS Lex Bot bot-definition.json.
This bot matches utterance against intent, and sends it to lambda function, databot_handle_input.
databot_handle_input is the main processing stage, where request from Lex is transformed to a query against ZenDesk Search API (using DataQuery, DataMetric).
The query is validated as necessary and the executed. And result returned to user.
When a query has been executed, it's result is also published through AWS IoT, using MQTT. The results are published row by row through to a MQTT topic. Handled by lambda databot_publish
The bot definition itself is quite "flat" - ideally each question should result in a Fulfillment. This might be straying a bit outside how a Lex bot should work, but as long is it does work.
Results viewer
The user can also view results what he's asking from DataBot in the Results viewer. The Results viewer is a simple Single Page Application which fetches latest result on first load and subscribes to any updated published by DataBot.
The initial results are fetched via an API call, handled by lambda databot_get_results.
The viewer starts a subscription via an API call. This results in an endpoint through which an MQTT subscription can be started. Handled by lambda databot_subscribe
Session
When a user starts a conversation with DataBot a new session is automatically created. The active query is attached to the session, and the session is what ties Bot interface and the Results viewer.
A good side-effect of this is that Results viewer is a simple link, which can be shared far and wide. There are security implications too, see below.
Sessions are persisted in a simple Dynamo DB table, databot_sessions.
Technologies used
- AWS Lex - Used for main bot interface.
- AWS Lambda - Application logic
- AWS API Gateway - Expose lambdas as REST APIs
- AWS S3 - Hosting for Results viewer
- ZenDesk API - Through Zenpy Python library. Requesting data from ZenDesk
- DynamoDB - Session persistence.
- AWS IoT - Publish and subscribe to live results from DataBot
Challenges
Putting together the smorgasbord of options which AWS offers can be daunting at times. Especially when security and IAM roles get involved. E.g. my initial take would have had session persistence in RDS, but I abandoned this because I couldn't get Lambda to connect to RDS.
Configuring the bot in Lex itself took a lot of experimentation, and I had to take down initial scope to accommodate (perhaps imagined) limitations. I still prefer Lex before regexp:ing my way through it though... :-)
Testing lambda code locally is possible, but I often ran in into small, subtle changes between the environments.
Deployment and management of Lambda code is something that is not handled very elegantly in this project. There's a rudimentary bash-script, but not enough for production use in any way.
Since this has been an exploratory project in many respects, there wasn't a fully fleshed out design from the get-go. Which rears it's ugly head once or twice in the code. E.g. class HumanReadable is an mess of if's and else's...
My Python package management in this project is haphazard.
Performance
All queries for data goes through to the ZenDesk API. This limits the practical amount of data which can be processed. The the real-world usage of DataBot would be to review limited amounts of operational data (100s of entries), so this is a workable limitation.
However, some queries are invalid due to the number of requests it would result against ZenDesk API (e.g. all closed tickets).
Security
Note that anyone who knows the session_id can get access to the list of tickets displayed by the active query in the session. In a fully fleshed out product, this should probably be tried to some kind of authentication mechanism.
Accomplishments that I'm proud of
Tying this all together in a short amount of time using mostly new technologies.
What I learned
A ton of new AWS technologies and their possibilities and challenges. Better understanding of the possibilities and limitations of AWS Lex. New found respect for the Lambda programming model.
What's next for DataBot
Potential next steps for DataBot
- Combine current processing logic with Speech recognition
- Real-world testing (does the story match the reality?)
- Including different data sources (e.g. JIRA)
- Adding data to calculate on (currently only number of and age)
- Adding support to query more entities (e.g. Agents, users, organizations in ZenDesk)
- Reference previous result set (As example see second question in story above)
Built With
- amazon-web-services
- aws-iot
- aws-lambda
- javascript
- lex
- python

Log in or sign up for Devpost to join the conversation.