nationalgradstat.org
AT&T Data Analysis competition
Purpose & How It Works
This analysis tool was the result of nearly two months of hard work. The purpose of this analysis tool is to identify key actionable insights that can account for variation in Adjusted Cohort Graduation Rates (ACGR). We communicate this information with an easy to use data driven web application founded on our results.
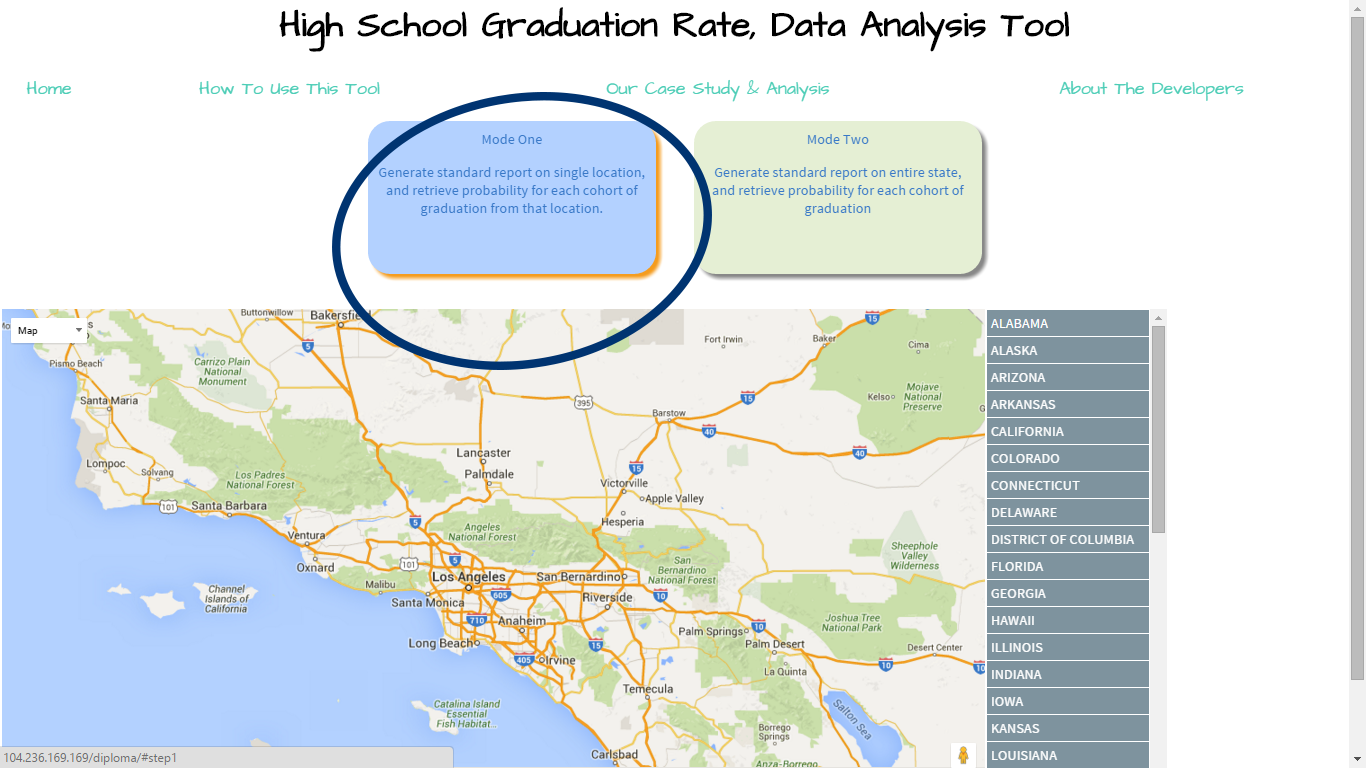
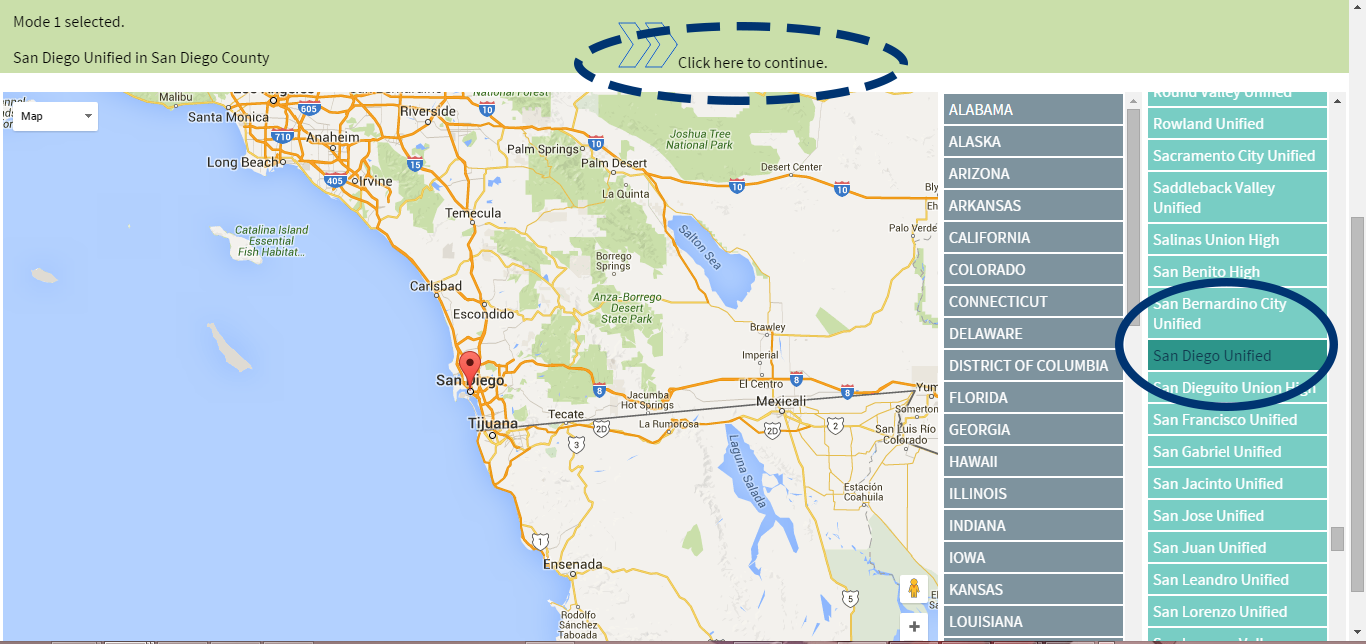
For each state, our web application establishes the magnitude of the graduation problem by identifying the cohorts that account for the most failures. For each cohort the web app considers at greatest risk of failure, the user can discover the variables that have the most predictive power in determining a given cohort's graduation rate. The user can then select actionable variables from options provided by the web app and stress test the variables in a linear regression model. Finally, after finding actionable variables that can improve a cohort's graduation rate, the user can determine the improvement required by the cohort to reach an overall 90% graduation rate by 2020.
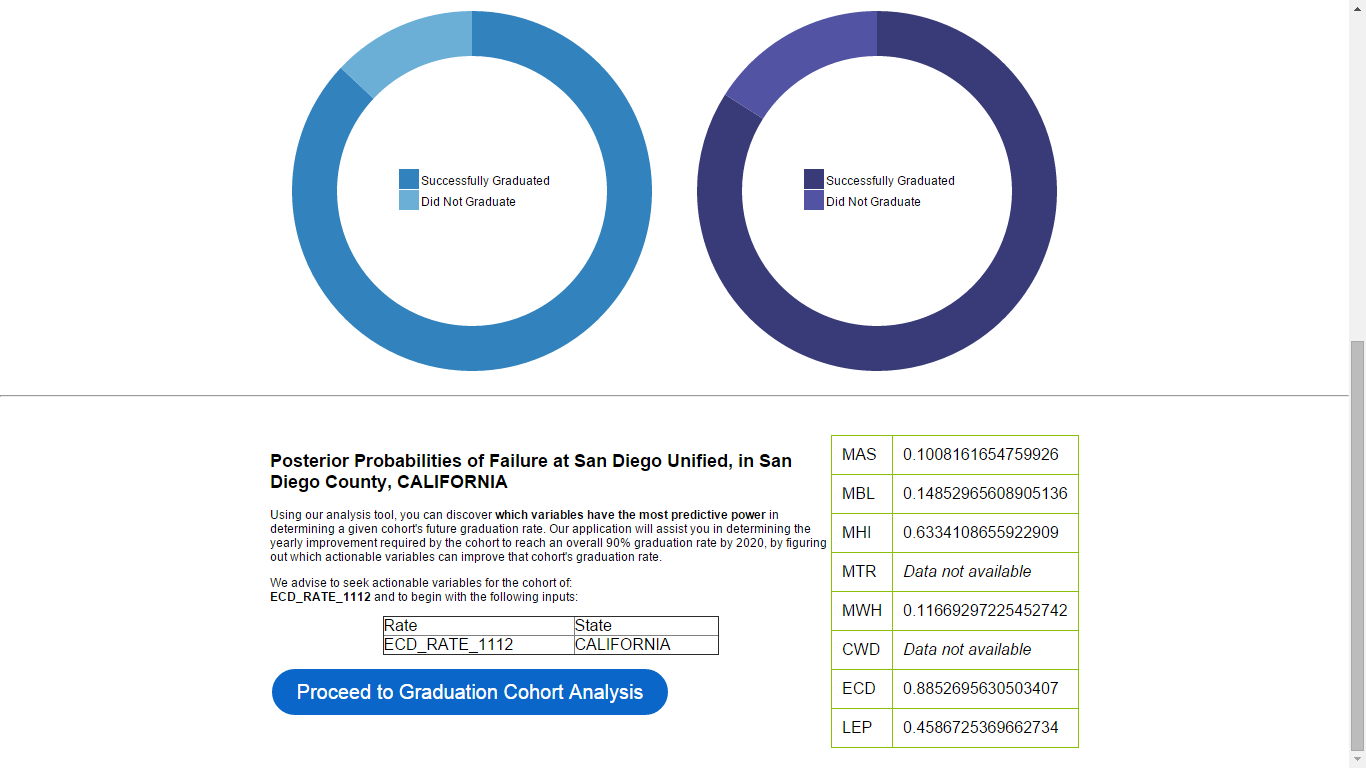
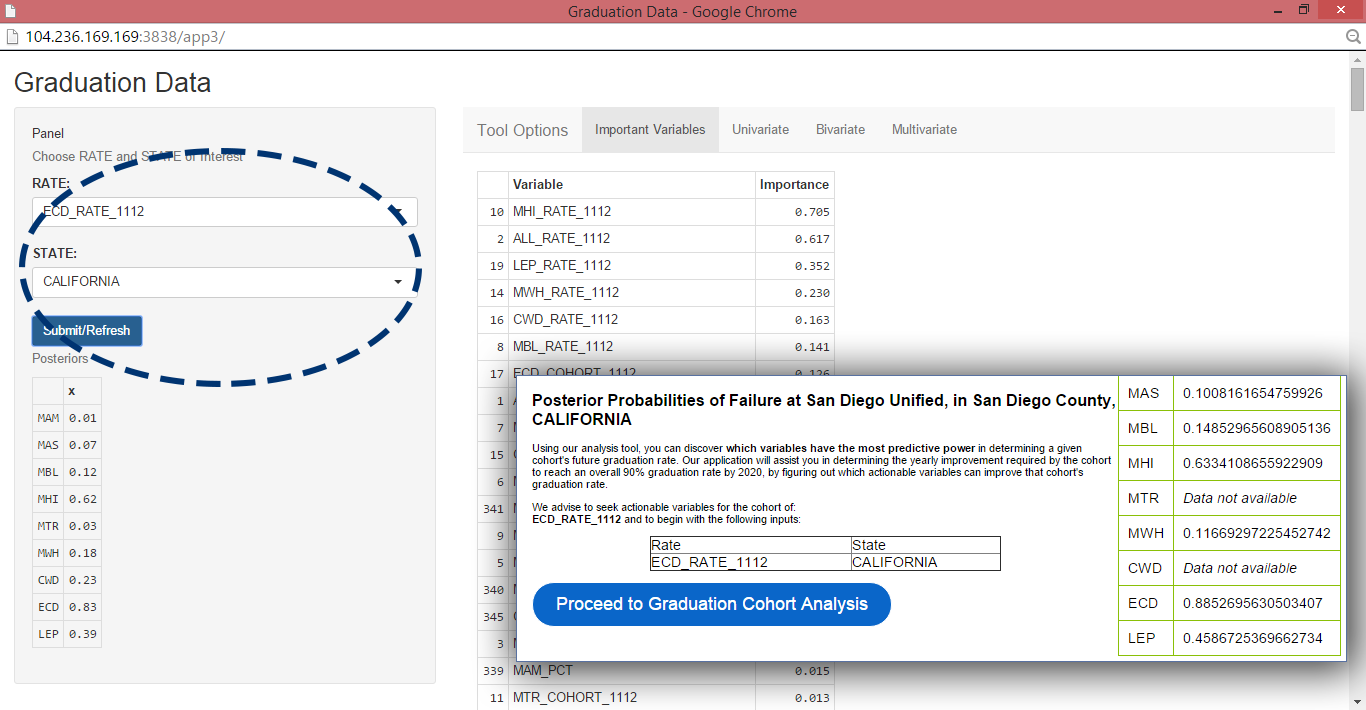
Step One: By using current evidence on cohort graduation we can determine which cohorts are of greatest concern based on the number of students failing. Using Baye's Theorem, we calculate the posterior probability of each cohort in the location of interest given that they did not graduate. The expression is written as P({COHORT}|NOT_GRADUATE). The quantity is calculated by (P(NOT_GRADUATE|{COHORT})*P({COHORT}))/P(NOT_GRADUATE)
Step Two: Having ranked the cohorts that are hindering the overall graduation rate, we can focus on knowing what variables predict their graduation rate. We do so by calculating the information gain of each variable in the dataset as it relates to the given cohort. The task is accomplished using the FSelector package written by Kotthoff and Romanski. The package discretizes all values, calculates entropies of each variable, and computes the information gain. Information gain is calculated by H(Class)+H(Attribute)-H(Class,Attribute).
Step Three: The user now knowing which cohort to focus on and and which variables may predict graduation rates can now make an informed decision to use variables they find actionable. The user can test the predictive power of each of these variables in a univariate, bivariate, or multivariate linear regression. As the user selects each variable the web app provides them with a suggested course of action knowing that the variable effectively predicts graduation rate.
Development Process
We had many obstacles throughout the project, which took an excruciating amount of work. We had poured so many hours into this analysis tool, that we went the extra mile to publish this as a live web application for the public to use at nationalgradstat.org
System Administration & Configuration
One of Claire's biggest challenges was dealing with a lot of server configuration issue, and balancing all of the different technology necessary to build this application. She had to take care of a multitude of tasks including increasing the swappiness of an Ubuntu server to be able to load all of the necessary R packages that Luis would need to work with. She had to upgrade the server memory, configure the server to be able to serve R files through a framework called Shiny.
Database Administration & Preparation
It was a true effort of teamwork to get the data necessary for the application. Luis went through the entire data set and cleansed it, before writing a script in Python to be able to create the database based off the CSV, while Claire ran it on the production server, to populate everything. We had to migrate the database twice, from one server to another, and ran into obstacles because of the sheer size of the data set (chunking down the data during population, dealing with memory consumption in Apache when loading the data).
Web Application Development & Joining Technologies
We ran into many situations where we are passing data between different technologies. We are querying a very large database we populated with the CSV provided (over 9000 records), and allowing the user to select options through PHP & SQL. Once our application retrieves that information, which returns as a mySQL object, we had to convert it into variables accessible by Javascript in order to reverse geocode the district's city/county locations, and adjust the Google Map on our UI. After that data is passed, we must send it to our graduation report portion of the application, where further calculations are performed on the variables retrieved by a series of SQL queries. Using SQL, we are querying more cohort information from the database, and calculating values such as graduation rates, and posterior probability of failure. The second half of the application which is the analysis tool is in a completely different realm and was written in R, using the Shiny package. It is hosted on a different port from the first half of the application, where it is configured to run in a browser.

Log in or sign up for Devpost to join the conversation.