-
-
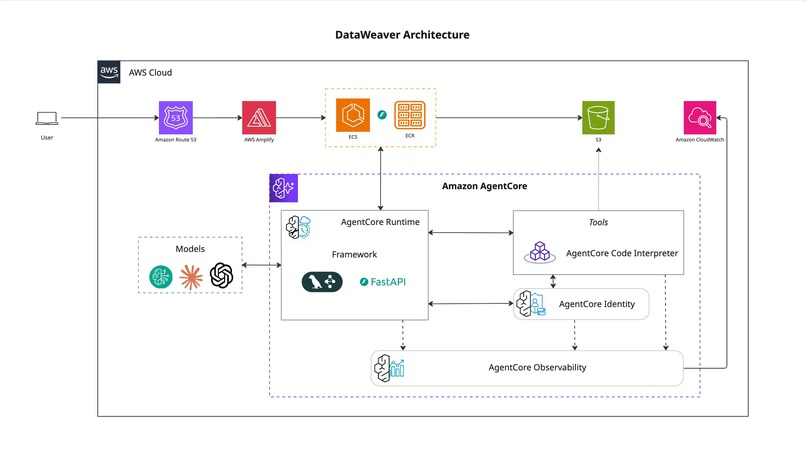
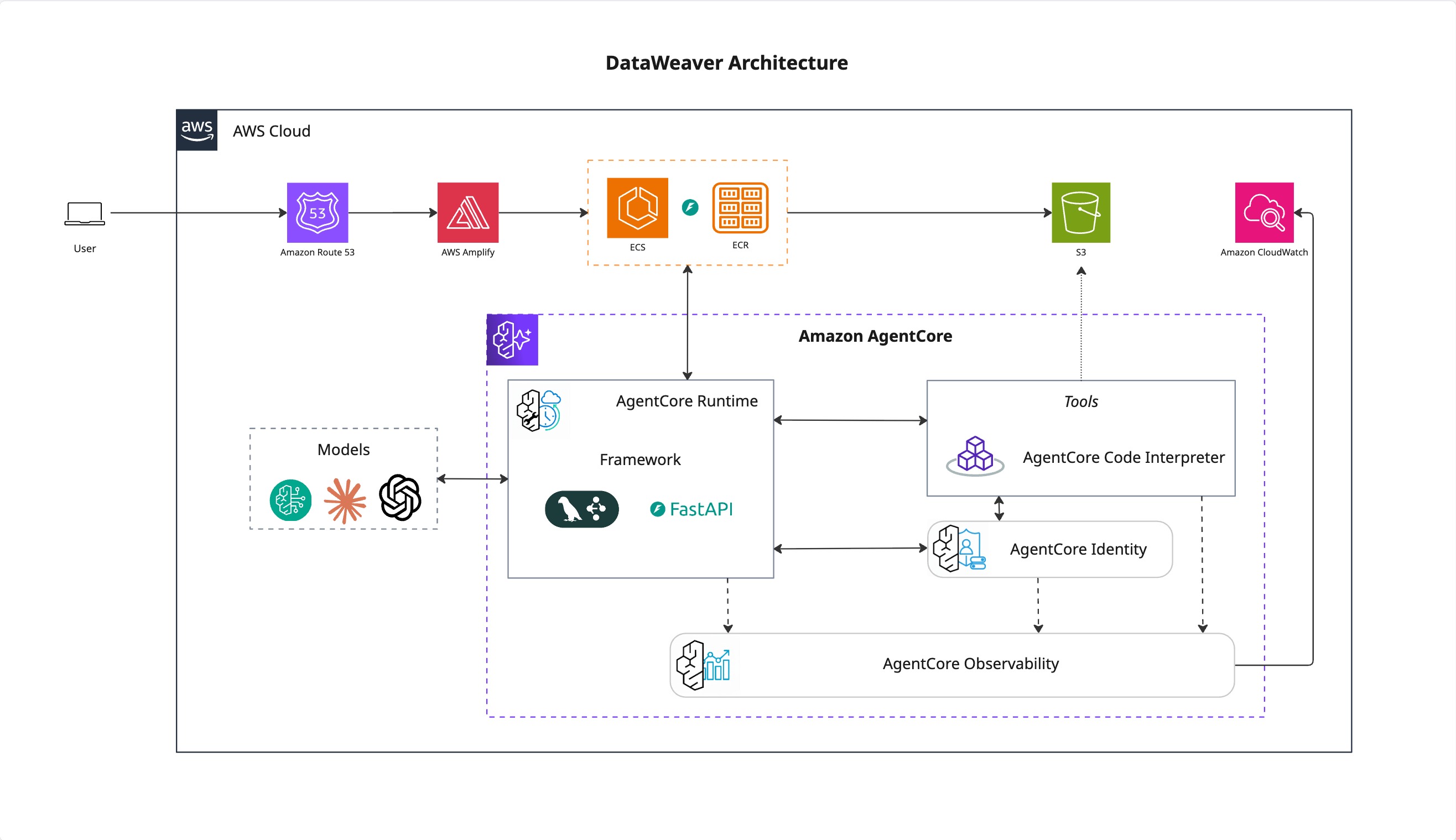
Architecture
-
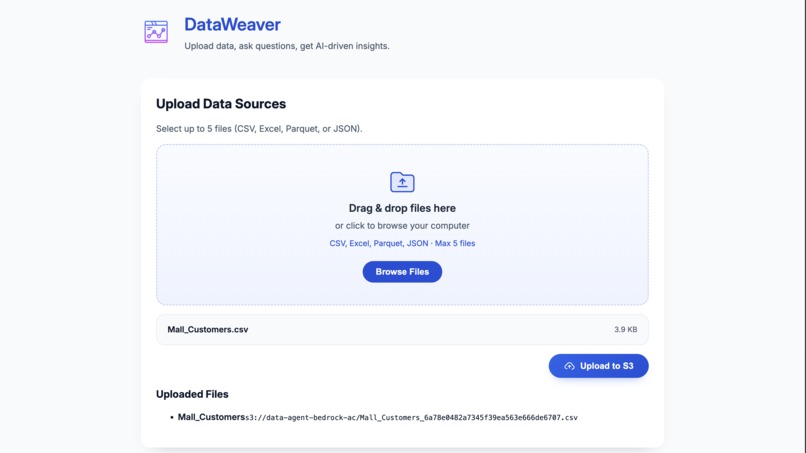
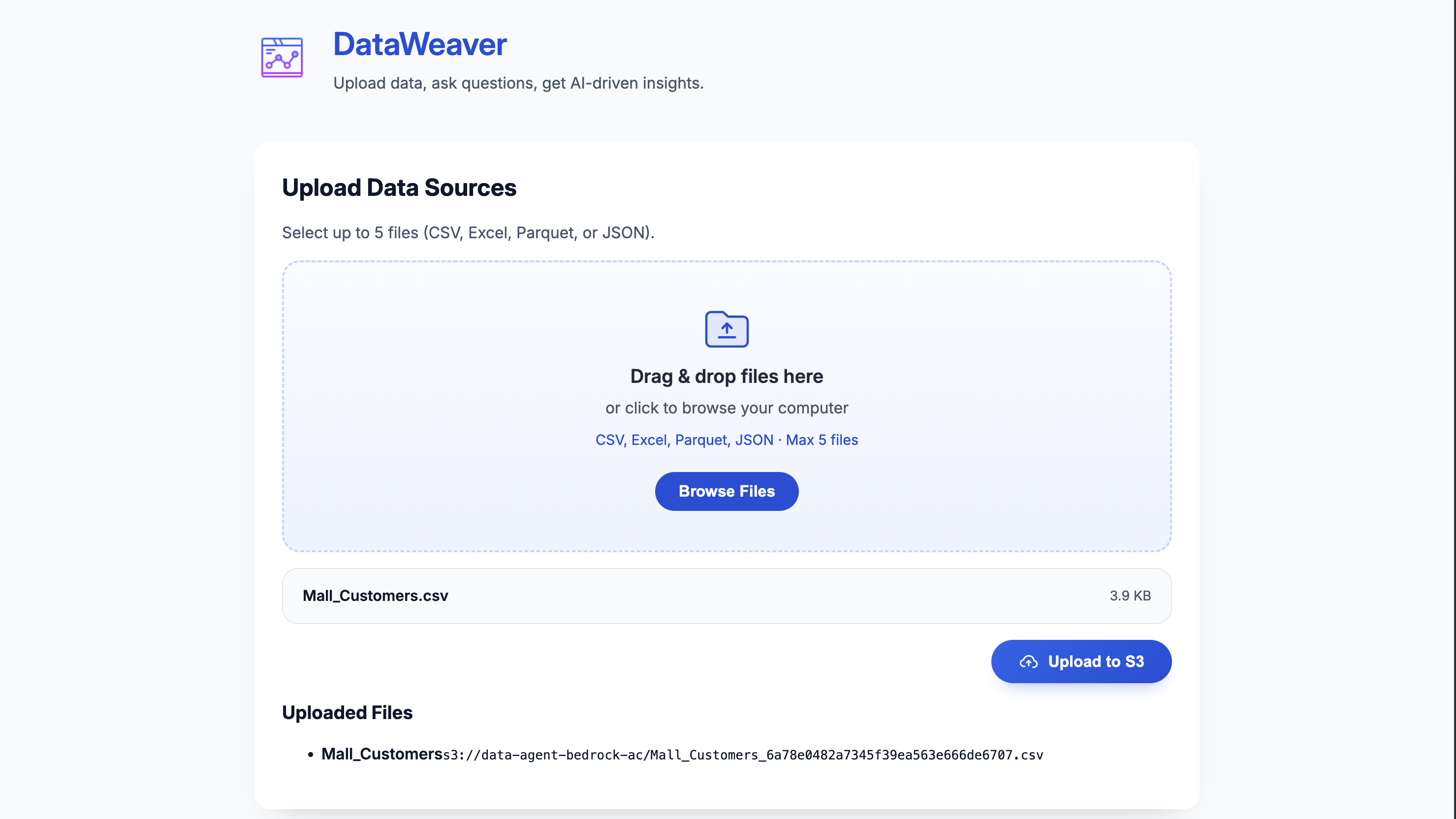
File Upload
-
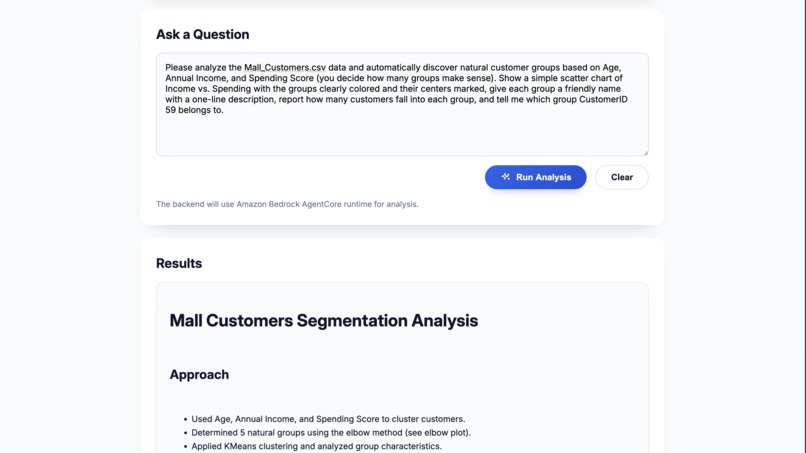
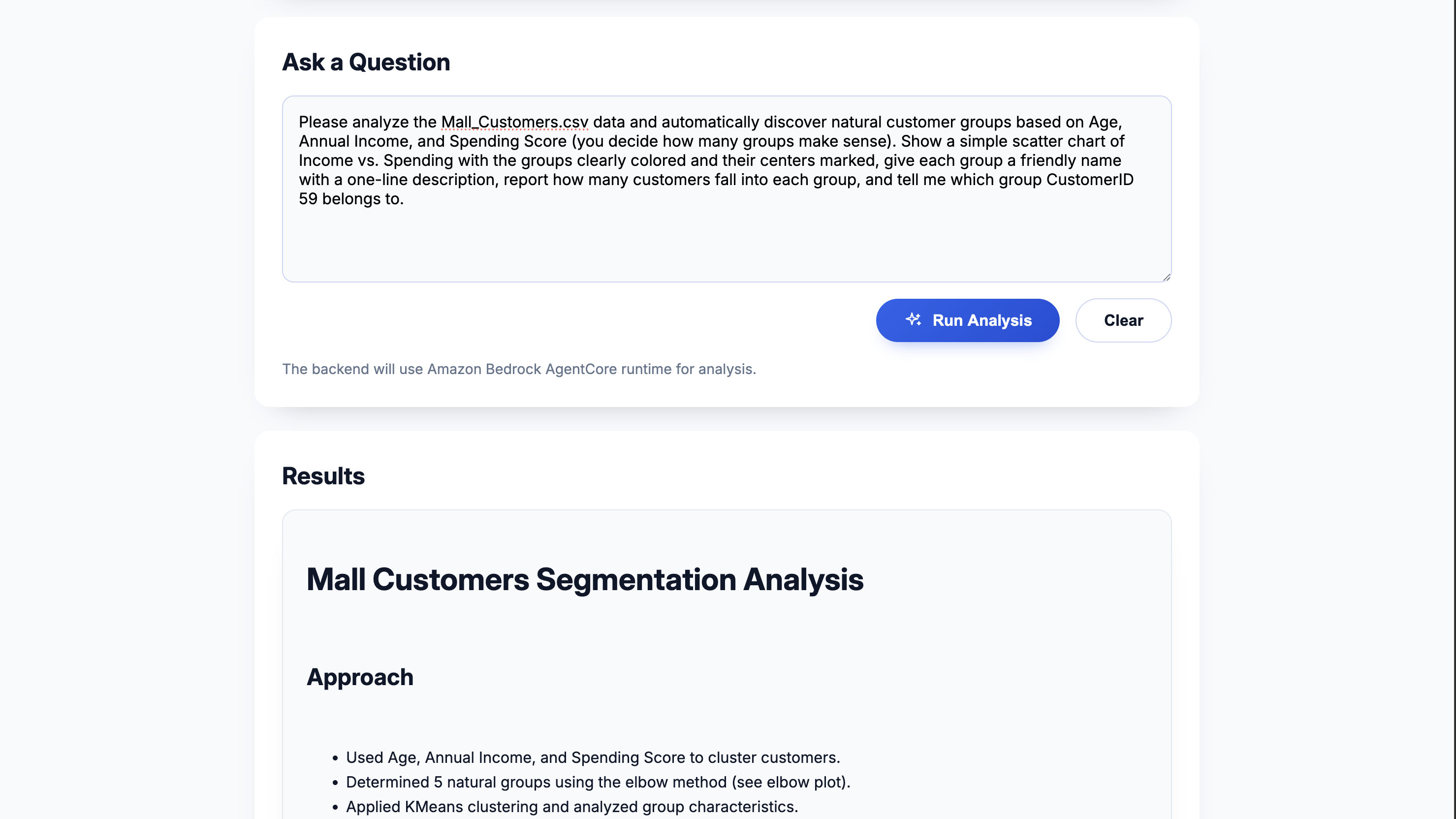
Questioning
-

Analysis Results
-
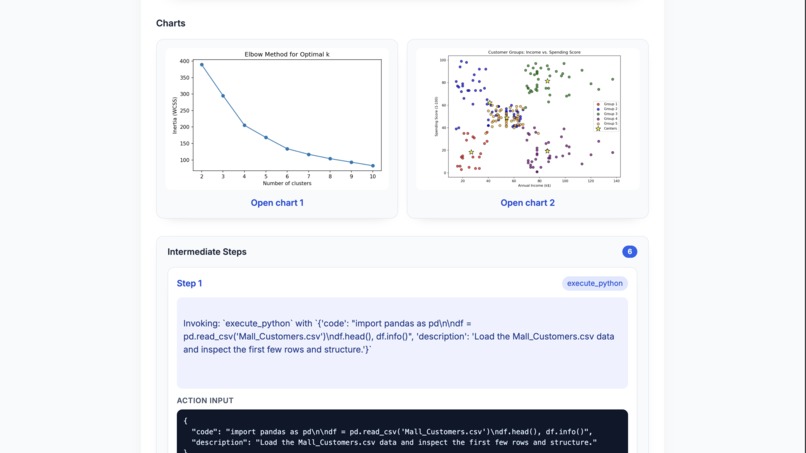
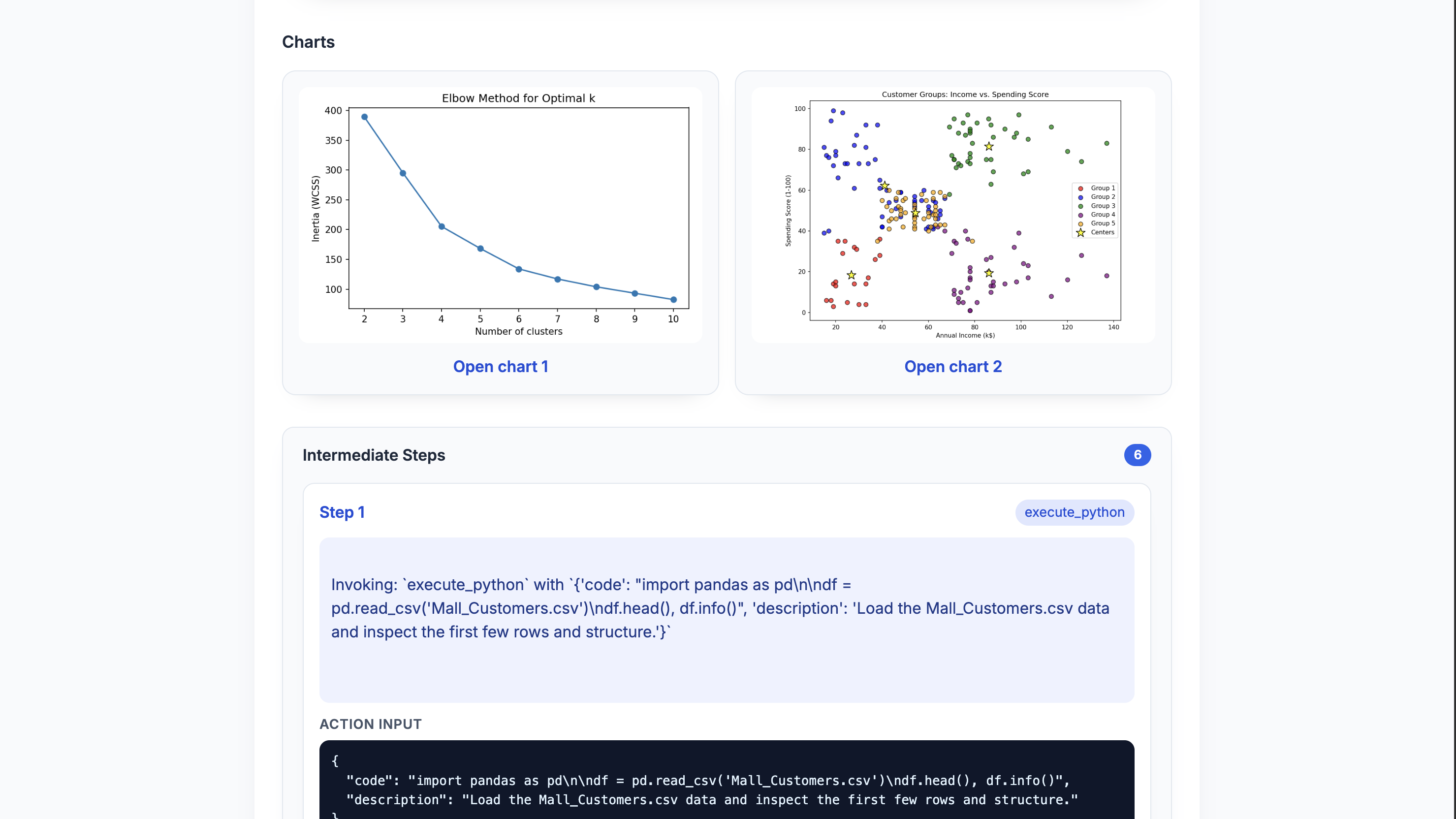
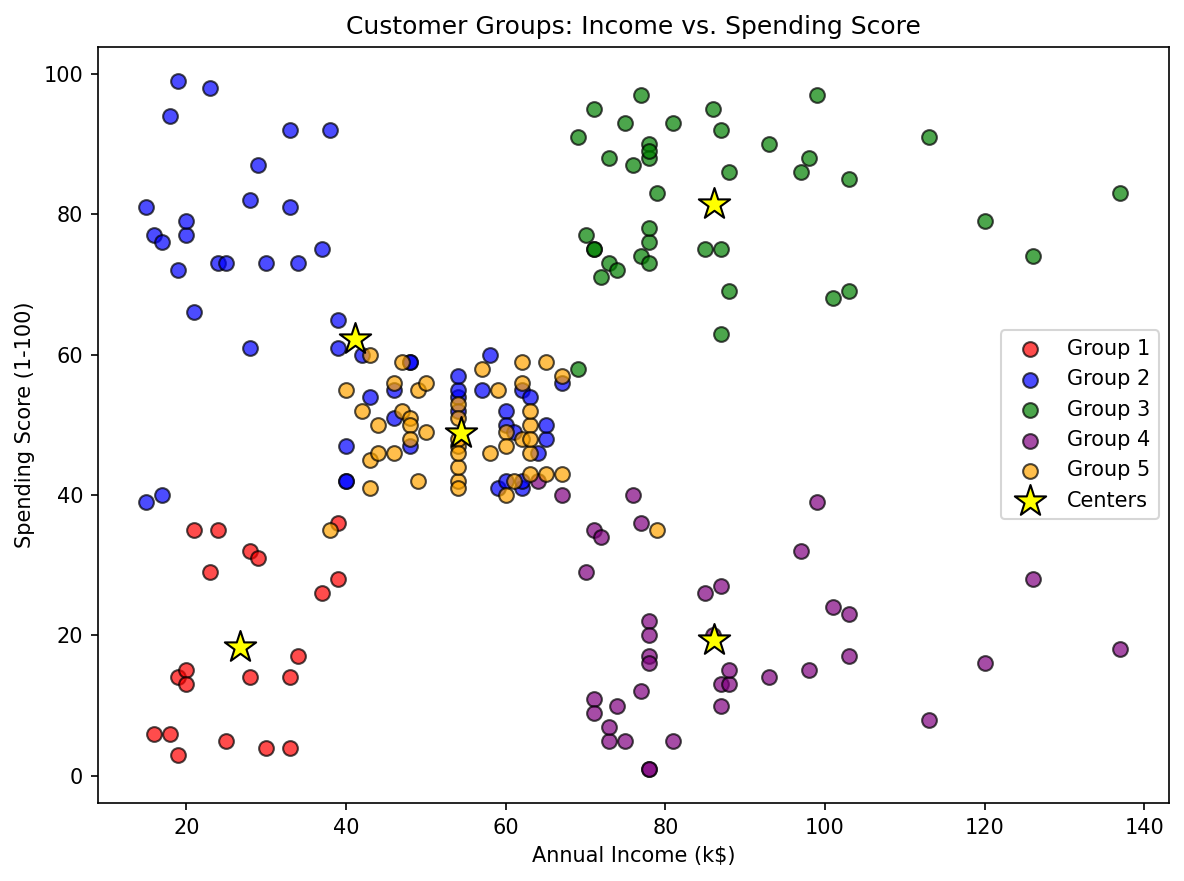
Chart Generation
-
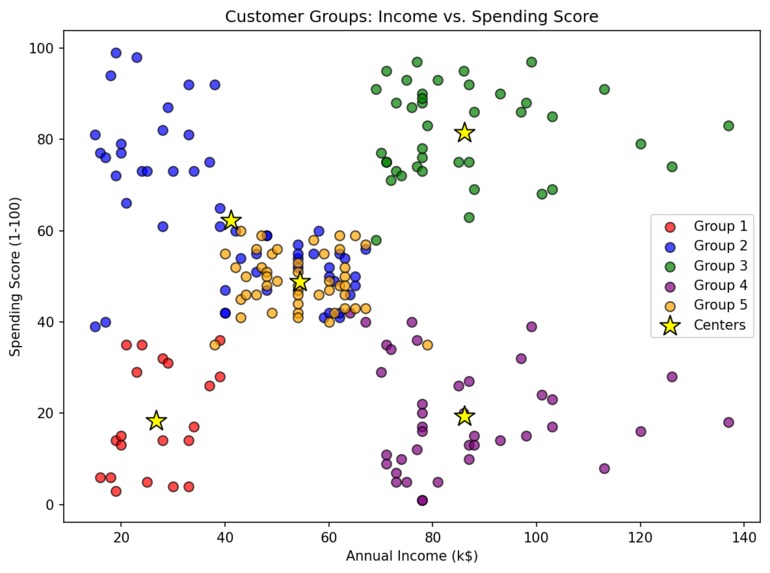
Sample Generated Chart
-

Full Analysis Sample


Inspiration
The project was inspired by the need to simplify data analysis for users who are not proficient in Python or SQL. Our goal was to build a reusable, scalable, and serverless agent for Amazon Bedrock that could accept natural language queries to perform complex data analysis on files stored in Amazon S3. We wanted to create an intelligent tool that could be easily integrated into various data workflows, empowering business users to get insights from their data without writing any code.
What it does
DataWeaver is a containerized service and web UI that acts as a conversational data analysis agent. Users upload tabular data (like CSV, Excel, Parquet, or JSON) to S3 via the application. They can then ask complex questions in natural language. The service coordinates with Amazon Bedrock AgentCore and its Code Interpreter tool to generate and execute Python code, delivering answers as formatted Markdown narratives and shareable charts stored in S3. It can handle everything from simple data lookups to running unsupervised machine learning models to discover customer segments on the fly.
How we built it
The project is a containerized web service with a Python backend and a Vue.js frontend, designed for a dual hosting model (either in ECS as a proxy or directly in the Bedrock Agent Runtime).
Backend: We built a FastAPI application that exposes the /ping and /invocations endpoints required by the Bedrock AgentCore runtime. It also includes a /chat endpoint that serves as an API proxy for the user interface.
Agent Logic: We used LangGraph and LangChain to construct a cyclical, stateful agent. This allows the agent to iteratively generate Python (Pandas) code, execute it using the Bedrock Code Interpreter, reflect on the output, and self-correct if an error occurs. The agent is equipped with tools to create visualizations using matplotlib and upload the resulting charts to an S3 bucket.
Frontend: The UI is a lightweight single-page application built with Vue 3 and Vite. It uses axios for API communication and includes a Markdown renderer to display the narratives and a gallery for the charts generated by the agent.
Cloud & Deployment: The entire application is packaged into a Docker image. The architecture is cloud-native, relying on Amazon S3 for data ingress and chart storage, Amazon ECR for the container image, and Bedrock AgentCore for the managed agent runtime. We also integrated the AWS Distro for OpenTelemetry (ADOT) for end-to-end observability into CloudWatch.
Challenges we ran into
Code Generation Reliability: Ensuring the LLM consistently generated correct and safe Pandas code was a primary challenge that required careful prompt engineering and a strict tool interface.
Handling Diverse Data Structures: Building a robust data loader to handle various file formats, especially the nuances of multi-sheet Excel files, required significant logic.
Tool Calling: Instructing the agent to properly utilize the available tools based on the user's intent and to return a relevant, synthesized answer was a key hurdle.
Trace Context Propagation: Configuring OpenTelemetry to correctly propagate trace context from the Bedrock runtime (via headers like X-Amzn-Trace-Id) through our FastAPI application was complex but crucial for observability.
Accomplishments that we're proud of
Stateful, Self-Correcting Agent: Moving beyond simple chains to build a cyclical agent with LangGraph that can reflect on its own output and retry on failure was a major success.
End-to-End Observability: We successfully integrated ADOT to achieve full request tracing from the Bedrock runtime through our container and back, a feature crucial for production-grade applications.
Seamless User Experience: We created a simple, intuitive workflow where a user can ask a complex machine learning question in one sentence and receive a complete narrative, a visualization, and a specific data lookup in a single response.
Flexible Deployment Model: The dual hosting architecture, allowing the same container to run as a standalone service in ECS or as a managed agent in the Bedrock Runtime, provides significant operational flexibility.
What we learned
This project was a deep dive into building production-grade agents on AWS. Key learnings include: Bedrock AgentCore Services: We learned the specifics of building and hosting an agent in the Amazon Bedrock AgentCore Runtime, from correctly implementing the required endpoints to leveraging its built-in tools.
Stateful Agents with LangGraph: We learned how to construct sophisticated, stateful agents that can manage a multi-step reasoning process, which is essential for complex tasks like data analysis.
Production Observability: We gained practical experience integrating the AWS Distro for OpenTelemetry (ADOT) to achieve full observability, learning how to configure auto-instrumentation to trace requests across managed AWS services and our own application code.
What's next for Data Weaver
Expanded Data Sources: Integrate directly with data warehouses like Amazon Redshift and databases like RDS, allowing users to ask questions about data without needing to upload files.
Proactive Insights: Enhance the agent to perform an initial automated exploratory data analysis (EDA) on new datasets and proactively suggest interesting questions or highlight potential data quality issues.
More Advanced Tooling: Add more tools to the agent's arsenal, such as the ability to call external APIs or perform web searches to enrich the uploaded data.
Interactive Dashboards: Move beyond static charts to allow the agent to generate and host simple, interactive dashboards as a final output for user queries.
Built With
- agentcore
- amazon-web-services
- bedrock
- bedrock-agent
- fastapi
- langgraph

Log in or sign up for Devpost to join the conversation.