Data Trust Desk
======================== Inspiration
As a person sitting outside a tech team at a bank, I've watched critical projects stall for months waiting on overwhelmed data teams. Our latest challenge: vetting 10,000+ healthcare facilities for future planning and decision making—but the dataset quality was unknown.
The standard workflow? Submit a ticket, wait 8-12 weeks for a quality report, schedule meetings, wait another 6 weeks for fixes. Meanwhile, our contract deadline looms.
I want to take control—but I'm not a data engineer. Could I build something myself using Databricks?
======================= What it does
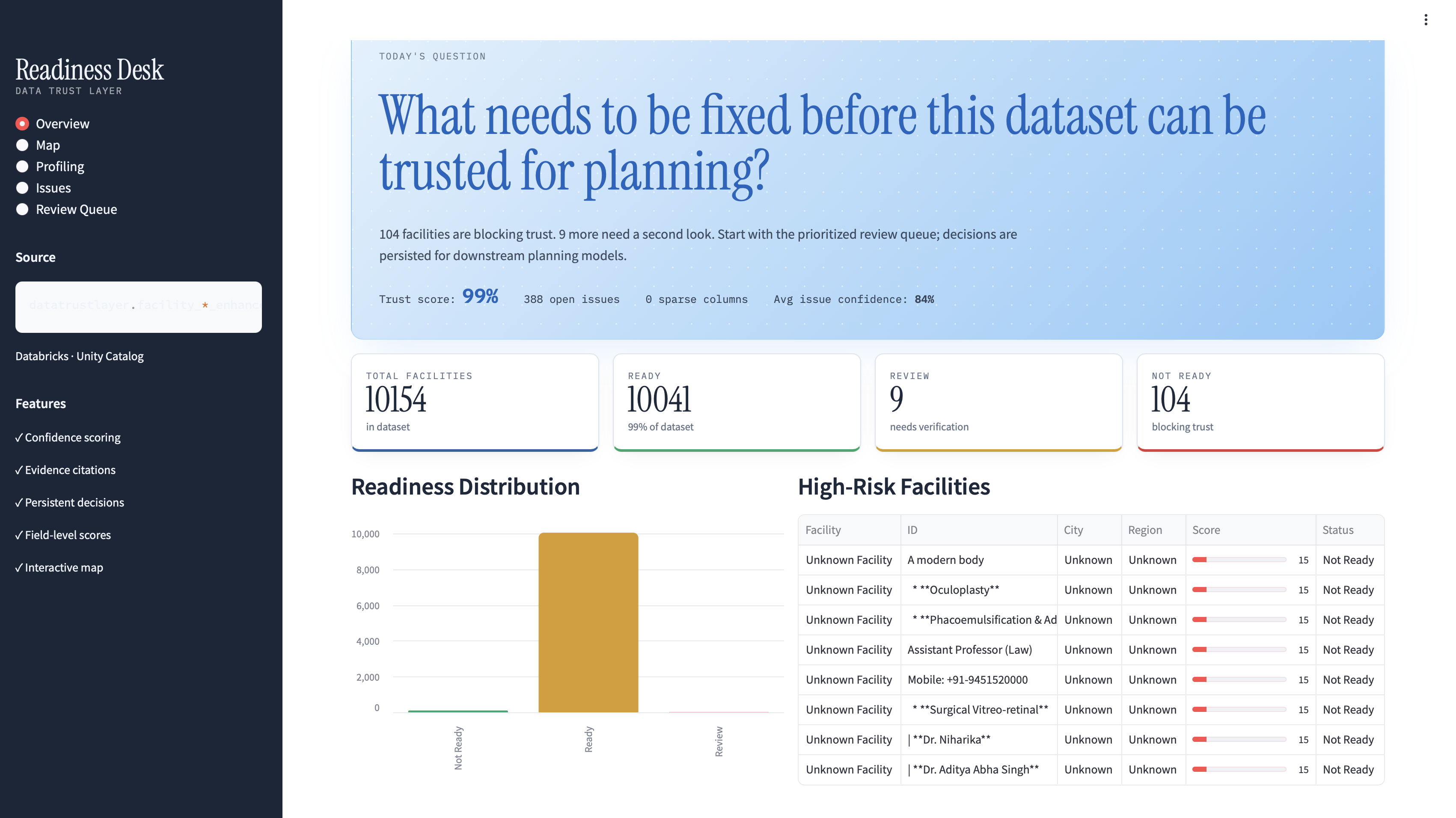
Data Trust Desk transforms untrusted datasets into planning-ready assets through evidence-based review workflows—built by a business user in under 8 hours.
Key capabilities:
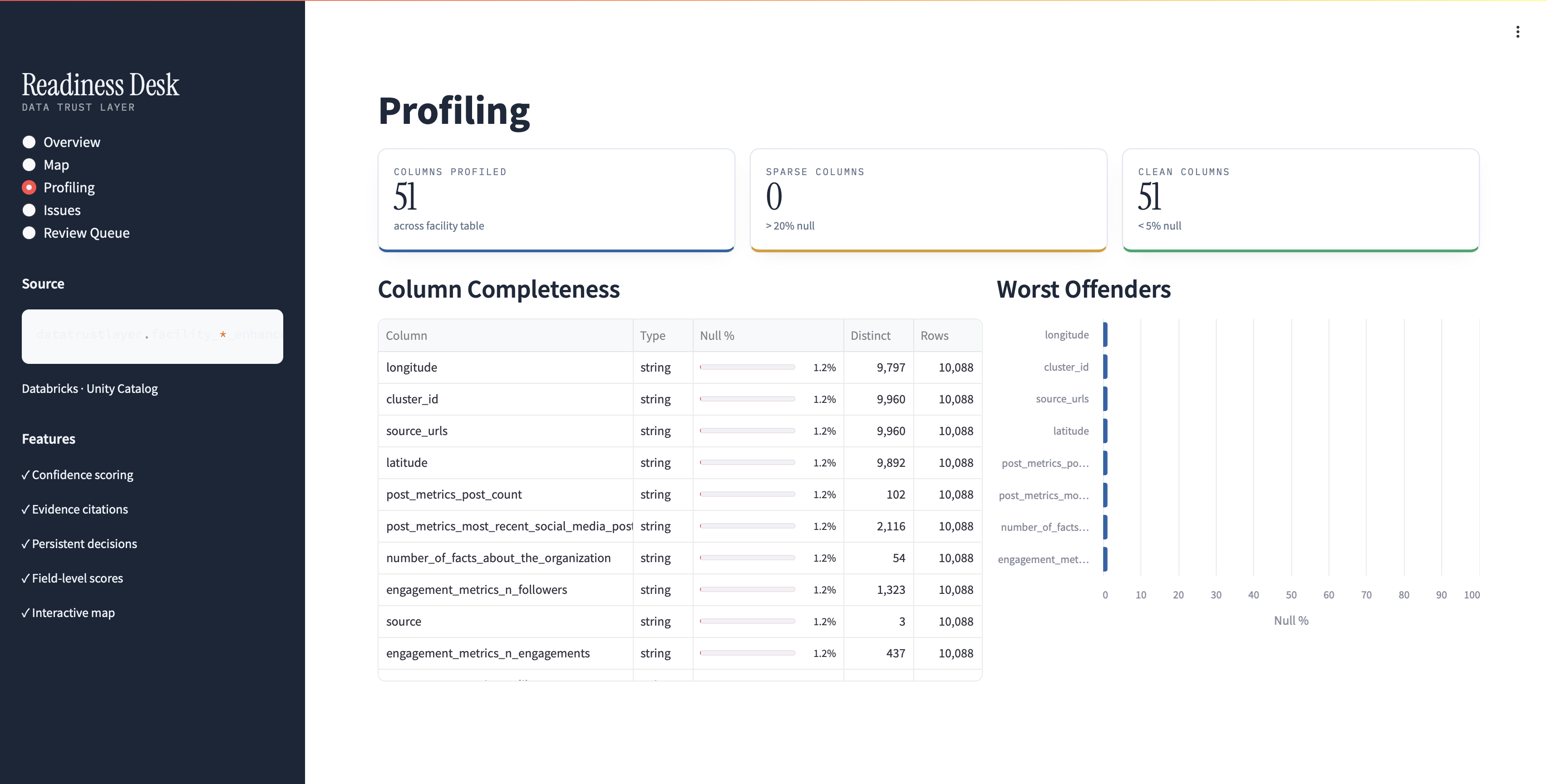
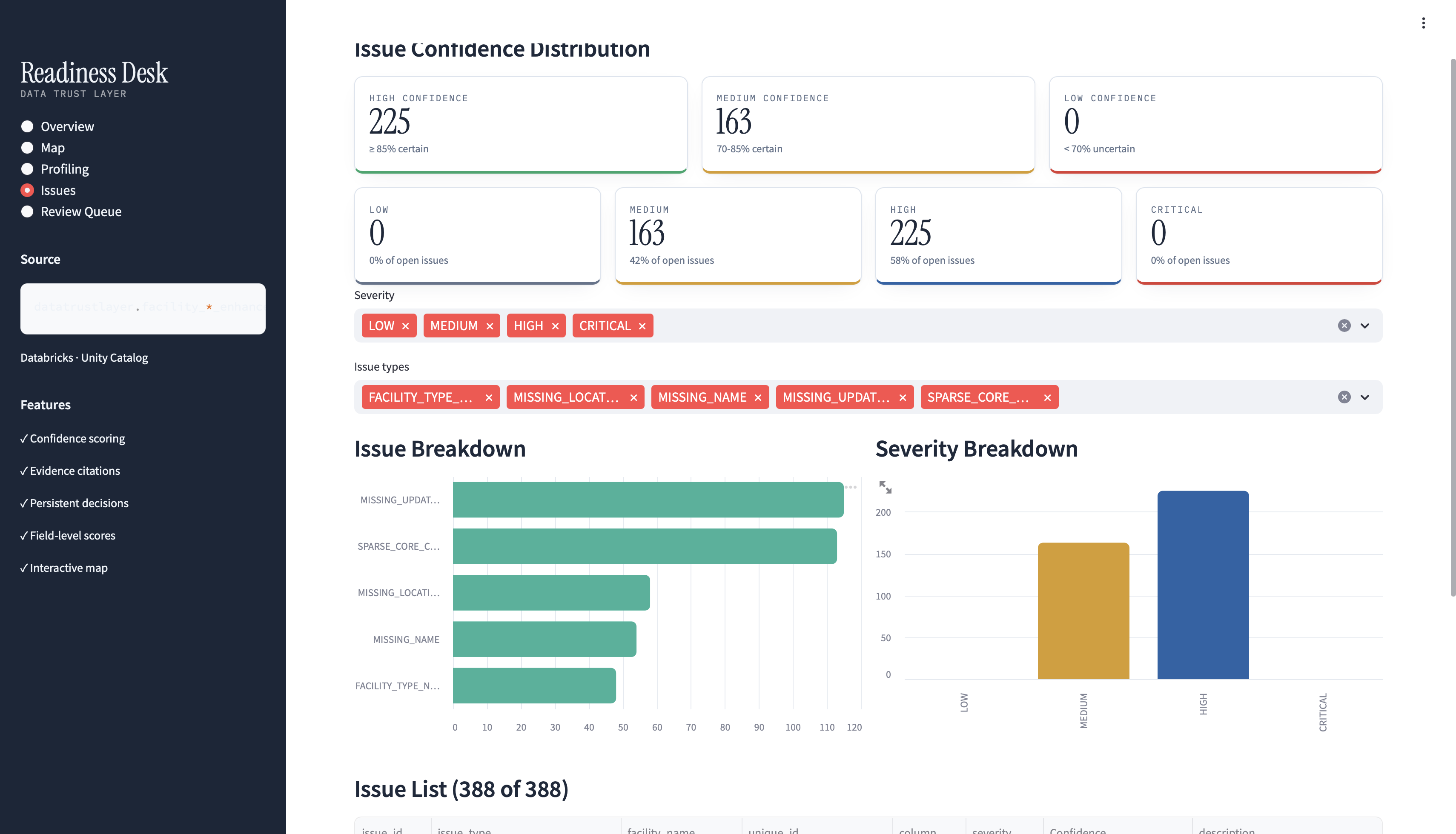
Confidence-scored issues: Every quality problem has a 0-100% certainty score (missing names: 100%, outlier detection: 65%)
Evidence citation: See actual field values that triggered issues, not black-box verdicts
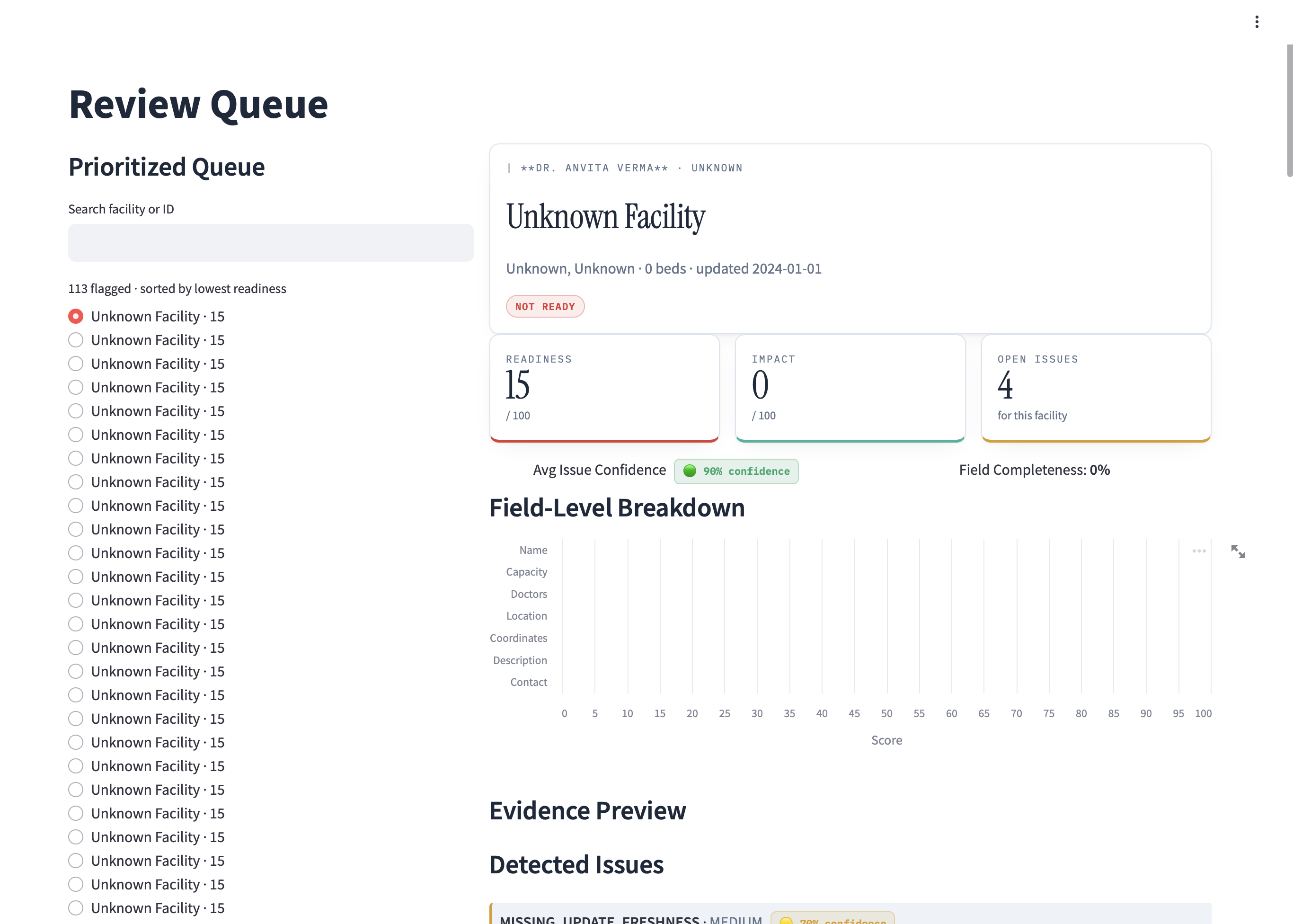
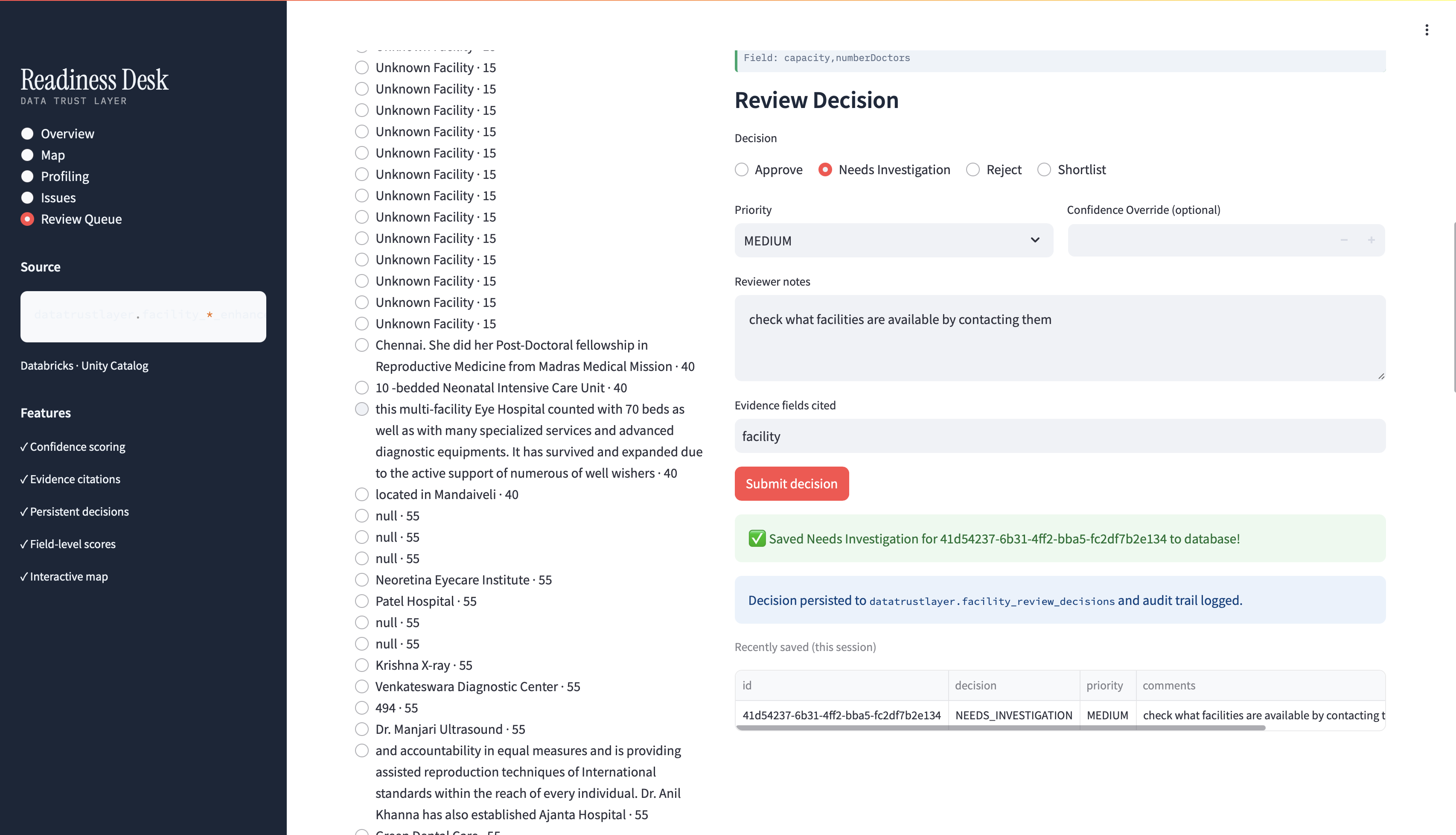
Interactive review queue: Prioritized by readiness score; APPROVE/REJECT/INVESTIGATE with notes
Persistent decisions: Write back to Unity Catalog—downstream models query facility_review_decisions for approved-only data
Field-level transparency: Visual breakdown showing exactly which fields block readiness
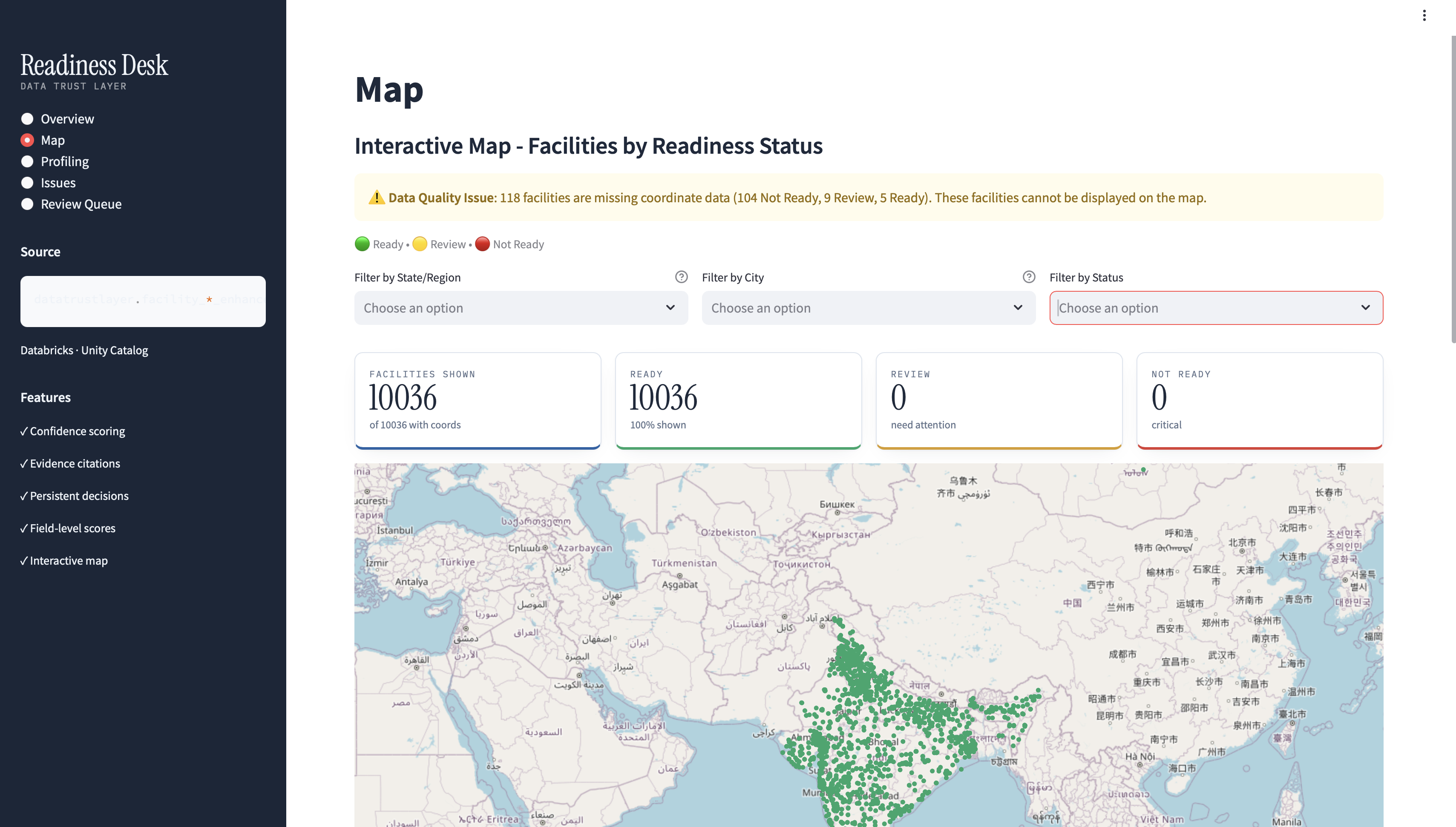
Geospatial triage: Map immediately revealed 113 facilities lack coordinates—a meta-quality issue!
Impact: What would've taken 3-4 months with data teams took 7 hours to build, 2 hours to review 113 facilities.
============================
How we built it
Total build time: Under 8 hours using the full Databricks stack:
Hours 0-2: Data exploration
Used Genie Agent to explore datatrustlayer.facilities with natural language queries
Discovered quality patterns through *Databricks SQL Editor *
Created enhanced views with confidence scores using Databricks AI Assistant to help write SQL
Hours 2-5: Schema design
Built layered schema in Unity Catalog: issues → field scores → review queue → decisions AI Assistant helped optimize queries and suggest scoring logic
Computed readiness scores (0-100) based on field completeness
Hours 5-8: App development
Built Streamlit app with real-time SQL Warehouse queries Deployed via Databricks Apps (one-click, no DevOps) Implemented decision persistence back to Unity Catalog Tech stack (all Databricks):
Unity Catalog: Governed data access SQL Warehouses: Serverless compute Genie Agent: Natural language data exploration AI Assistant: SQL/Python code generation Databricks Apps: One-click Streamlit deployment Visualization: Altair + Plotly ** **Key enabler: As a business user with no prior Databricks experience, I could build this because the platform handles infrastructure, governance, and deployment—I just focused on business logic.
=============================
Challenges we ran into
Schema evolution mid-build
Simplified facility_review_decisions from 8 to 5 columns during development Hit CAST_INVALID_INPUT errors from column mismatches
Solution: Packed metadata into structured comments field
SQL injection from user input
Comments with single quotes broke INSERT statements Solution: Built escape function for safe string handling
Coordinate data gaps
Map showed only READY facilities—113 needing review had no lat/long Solution: Turned bug into feature by exposing the meta-quality issue with warnings
======================== Learning curve
First time using Databricks SQL Connector, Unity Catalog permissions,
Streamlit Solution: Leaned heavily on Databricks AI Assistant and documentation—answered 90% of questions in-context Accomplishments that we're proud of
Sub-8-hour end-to-end build As a business user with no Databricks experience, shipped a production-ready app in a single workday.
Production-grade persistence Not a prototype—decisions write to Unity Catalog with audit trails. Downstream planning models can consume immediately.
Uncertainty quantification Most tools are binary (pass/fail). We quantify confidence, enabling informed precision/recall tradeoffs.
Evidence-first design Every claim backed by field values and citations—critical for regulated industries like banking.
Fully governed, no shadow IT Built within Databricks workspace using Unity Catalog—no rogue databases, Excel sprawl, or compliance violations.
Self-service data democratization Proved business users can build sophisticated data apps when the platform handles infrastructure and governance.
==============================
What we learned
The Databricks ecosystem enables true self-service Unity Catalog + Genie + AI Assistant + SQL Warehouses + Apps = business users shipping in hours, not months.
AI assistance accelerates non-experts Genie for exploration, AI Assistant for code generation—reduced learning curve from weeks to hours.
Trust requires transparency Quality isn't just detecting issues—it's communicating uncertainty, citing evidence, and capturing decisions as reusable data.
Persistence is the missing piece BI tools let you explore but not write back. Making decisions first-class data unlocks downstream consumption.
Visualization surfaces hidden issues Map revealed coordinate gaps that SQL missed—spatial context adds critical dimension.
==============================
*What's next for Data Trust Desk *
Near-term:
Bulk actions: Approve/reject multiple facilities based on filters Scenario modeling: "What if we fix coordinates—how many become Ready?"
AI-assisted review: Use Databricks Foundation Models to suggest decisions based on similar past reviews
Collaboration: Multi-user workflows with assignment and approval chains
Medium-term:
Generic framework: Works for any dataset (customers, vendors, products), not just facilities dbt integration: Auto-generate enhanced tables from dbt tests Slack alerting: Notify when high-confidence issues appear
Long-term vision:
Data trust marketplace: Share review templates across teams
Regulatory compliance: Export audit trails for SOX/GDPR—prove decisions were based on trusted data
Make "data trust" a first-class lakehouse concern with trust scores and audit trails for every dataset
Closing: As a business user, I went from "waiting months on data teams" to "shipping in 7 hours" using the Databricks platform. That's data democratization in action—and why Data Trust Desk represents the future of self-service data quality. Built entirely in Databricks, in under 8 hours, by a non-engineer.

Log in or sign up for Devpost to join the conversation.