-
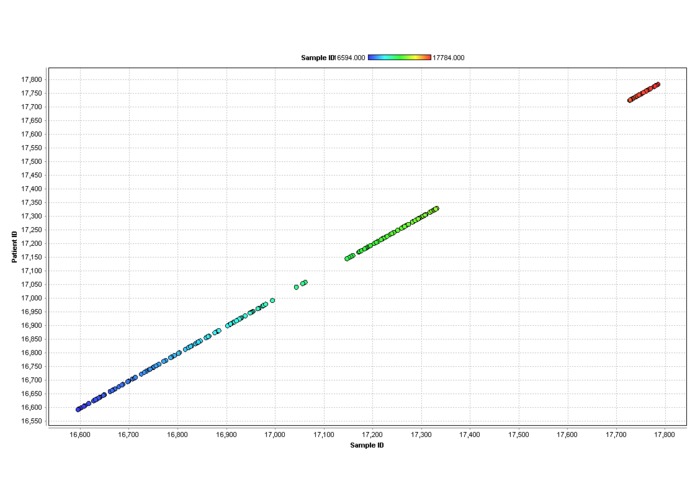
Genetic Mutations Data View
-

File Data Sorting View
-
GDC File Size View
-
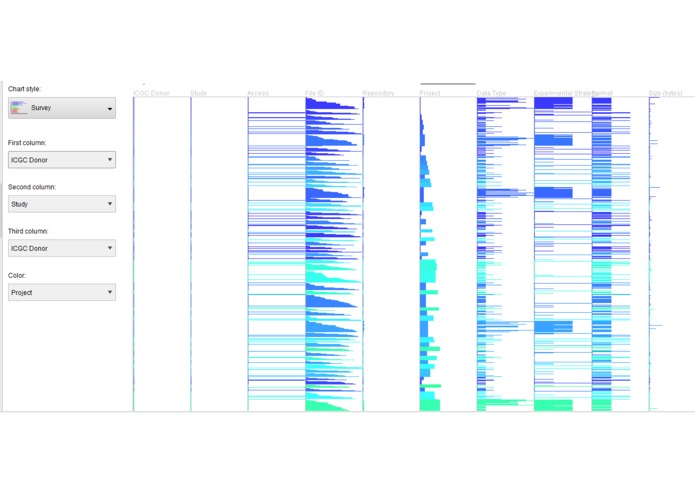
Genomic Donor Experiment Data View
-
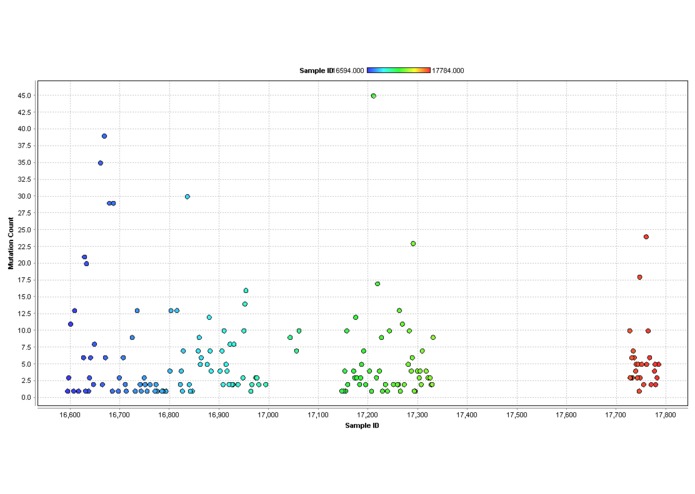
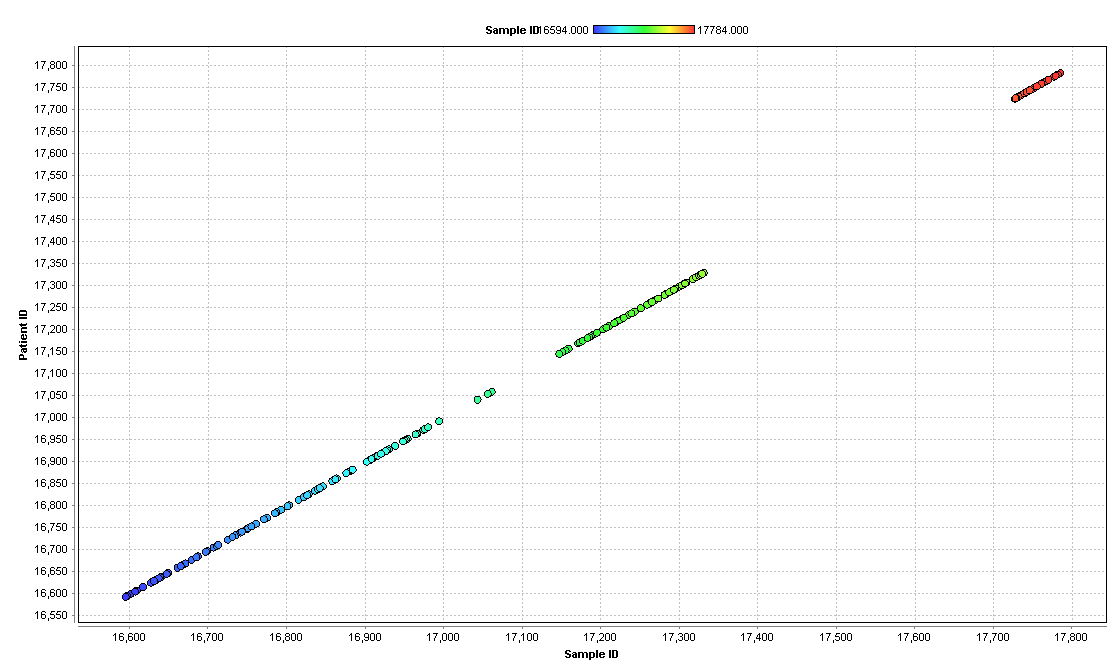
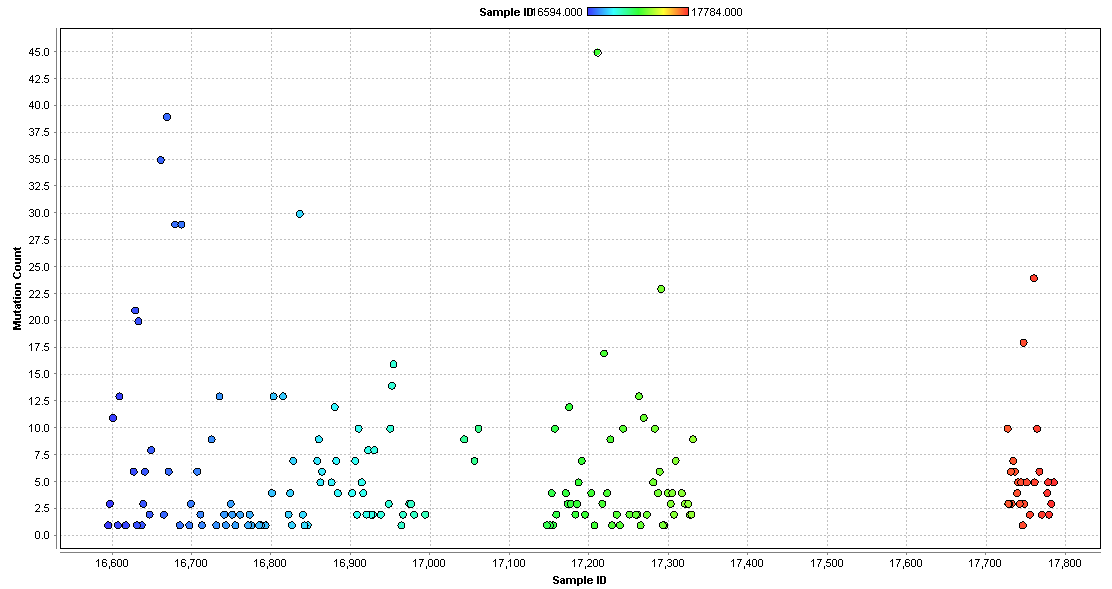
Genetic Mutation Count Scatter Plot
-

Stacked Bar Data Visualization for Studies
-
-
-
Custom API created using Dropbox (Private)

Inspiration
Knowing how fast it takes Microsoft to calculate the human genome, I wanted to do something further with some of that data. Many open bio portals have lots of genomic cancer case studies in the public domain, and this is where the inspiration came from. I want to be able to build a cloud repository and create an API that can compress and mine through hundreds of thousands of cancer case studies and visualize the most important ones at once, draw conclusions using MD5 data, and perform experimental analysis.
What it does
Right now from the cBioPortal, the GDC Portal, and the NCI Data commons are where the repositories are from. I added them as processes using Data Miner 4 and started work on a custom API connected through Dropbox's API explorer that will validate and be able to analyze/predict outcomes.
How I built it
I built is utilizing RapidMiner's 4 built in model program, DropBox's API explorer and utilized R as well as Python for gplot. Visualizing the data was mainly the easier part.
Challenges I ran into
I wasn't able to fully finish the custom API yet, but have got a long way ahead in validating the process of being able to use predictive analysis to look at different case studies
Accomplishments that I'm proud of
I am proud that I started a large data science project and how far I gotten in under a few days. If I have more time, I plan on taking this much further. Utilizing R, as well as other technologies for Data Visualization can lead to better statistical outcomes for machine learning and the IOT. This can lead to technologies such as getting us closer to the P vs. NP, Riemann Hypothesis or being able to predict millions of strands of data from hardware in real time.

Log in or sign up for Devpost to join the conversation.