-
-
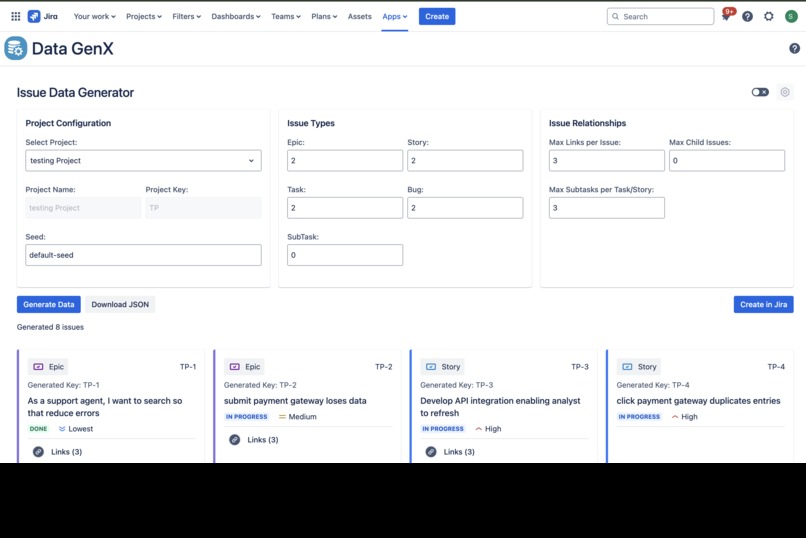
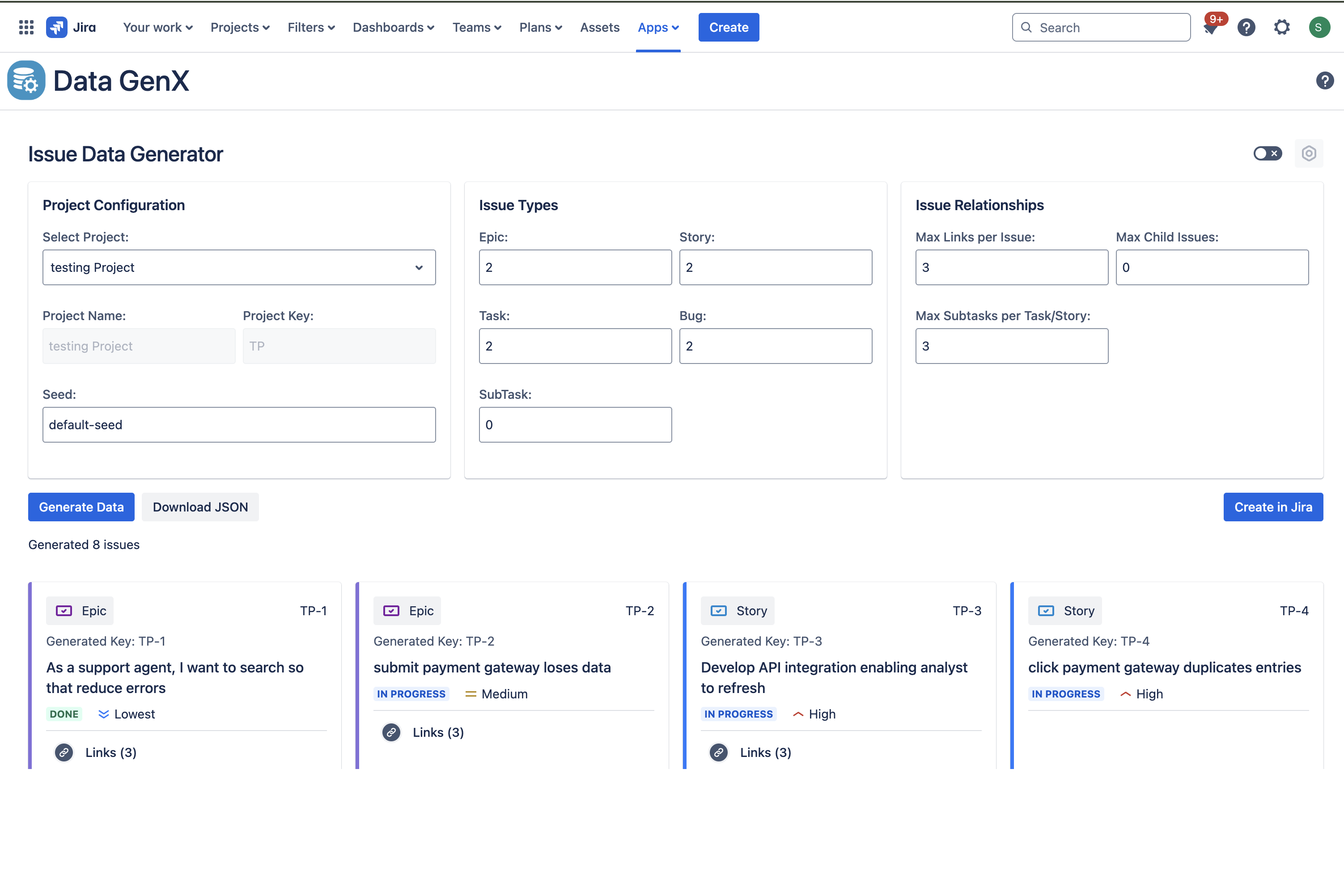
Data GenX: Data Generation
-
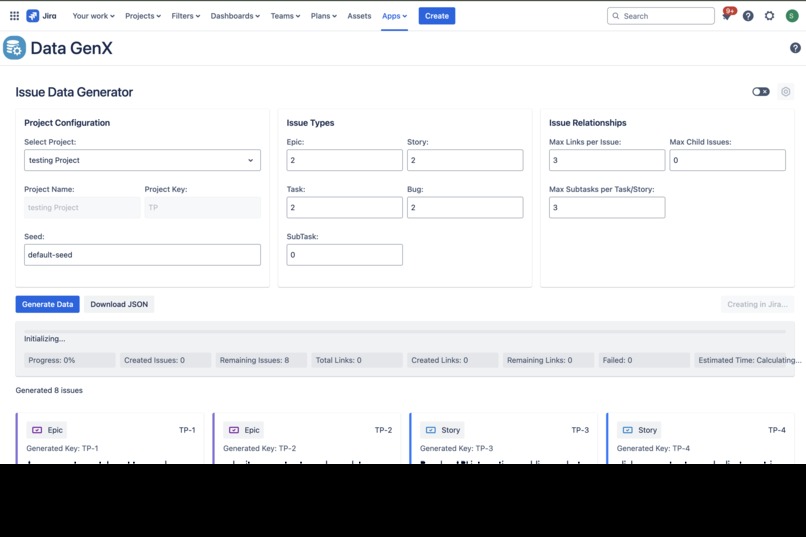
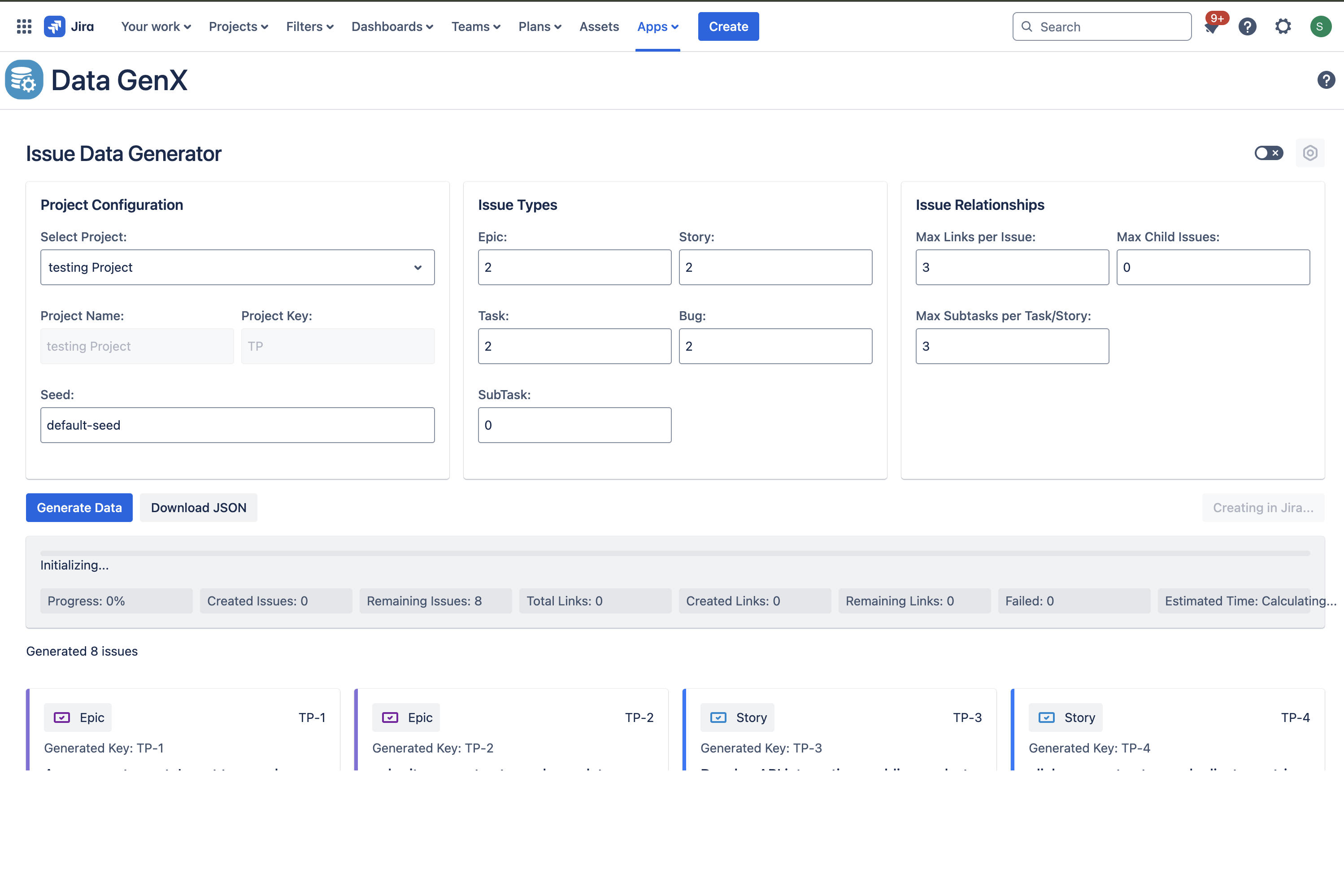
Data GenX: Data Creation in Jira
Inspiration
What it does
How we built it
Inspiration
In testing, demos, and test case management, teams often need realistic Jira data to simulate real-world scenarios. Creating this data manually is time-consuming and error-prone. We built Data GenX to simplify and automate this process, helping testers, developers, and product teams save time and ensure consistency.
What it does
Data GenX allows users to generate sample data directly in their Jira instance. It can:
- Create epics, stories, tasks, bugs, and subtasks
- Support custom issue types, custom fields, and custom link types
- Build hierarchies with linking relationships
- Set statuses and priorities
- Randomly generate data around a provided seed value (ensuring reproducibility)
By using the same configuration and seed value, users can recreate the exact same dataset anytime — perfect for consistent test environments and repeatable scenarios.
How we built it
We developed Data GenX as a Jira app that works with Jira Cloud as well as Jira Data Center (Server).
We used:
- Atlassian Forge for cloud app integration
- Jira REST APIs for interacting with Jira Cloud and Jira DC
- React for the custom UI
- TypeScript and JavaScript for type safety, flexibility, and maintainability
- Java and XML for Jira Data Center (Server) app development
- Seeded random logic for deterministic data generation
This combination of technologies allows Data GenX to integrate seamlessly across Jira environments and deliver consistent, repeatable data generation.
Challenges we ran into
- Ensuring the generated data matched complex Jira configurations and workflows
- Handling custom fields, issue types, and link types dynamically
- Guaranteeing data consistency when using seed values across different environments
- Managing API rate limits and error handling during large data generation
Accomplishments that we're proud of
- Successfully implemented seeded random data generation, allowing users to recreate identical datasets
- Built flexible support for custom issue types, fields, and links
- Created an intuitive UI that makes data generation accessible for testers and demo purposes
- Enabled efficient creation of complete project structures, from epics to subtasks
What we learned
- The importance of handling Jira API edge cases and permission models
- How seed-based randomization can bring powerful repeatability to data generation
- How critical it is to provide flexible configurations to match varied Jira setups
What's next for Data GenX
- Add more advanced configuration options (e.g., workflow transitions, comments, attachments)
- Provide export/import options for configurations and generated datasets
- Support bulk deletion and cleanup of generated data
- Integrate AI to help users design data configurations faster and as well as provide Prompt based Data Generation and creation based on the user needed.
- Enhance UI/UX for easier setup and monitoring of data generation

Log in or sign up for Devpost to join the conversation.