


INTRODUCTION
The goal of the "Data for Diplomas" hackathon is to use data analysis to discover new ways to increase high-school graduation rates in the US. To that end, I took two approaches.
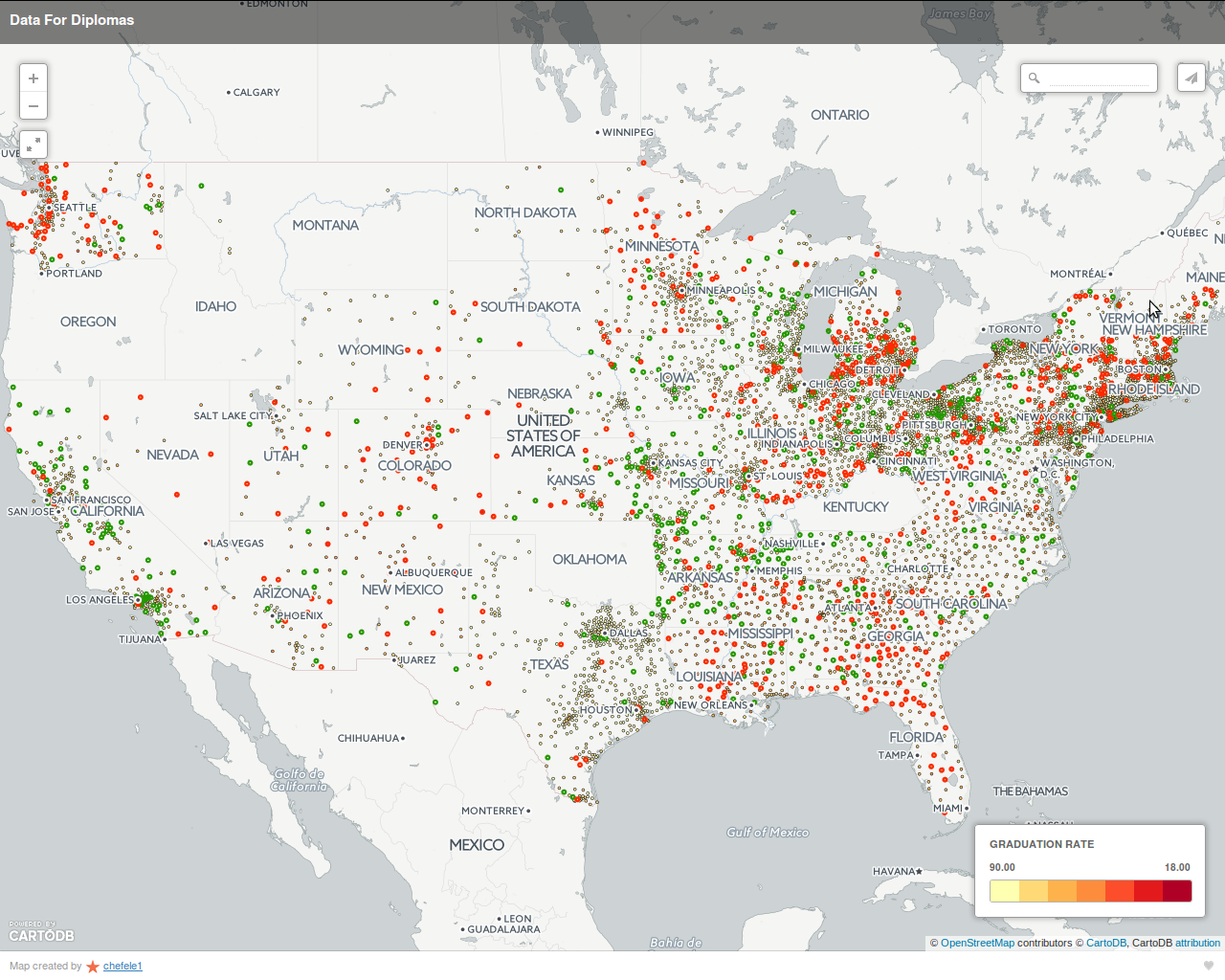
The first approach was to create an interactive map (available here) that incorporates relative graduation rates -- that is, graduation rates after controlling for variables available in Census data (e.g. local poverty, demographics).
The second approach was to analyze of the impacts of school size on graduation rate, after controlling for poverty and other confounding variables.
Both of these approaches used the same machine-learning model to predict the expected graduation rate of each school district.
A summary of the results and recommendations is below. A full description of the solution methodology is available in [this paper] (Judges: The paper is also in my .zip of uploaded code)
INTERACTIVE MAP OF RELATIVE GRADUATION RATES
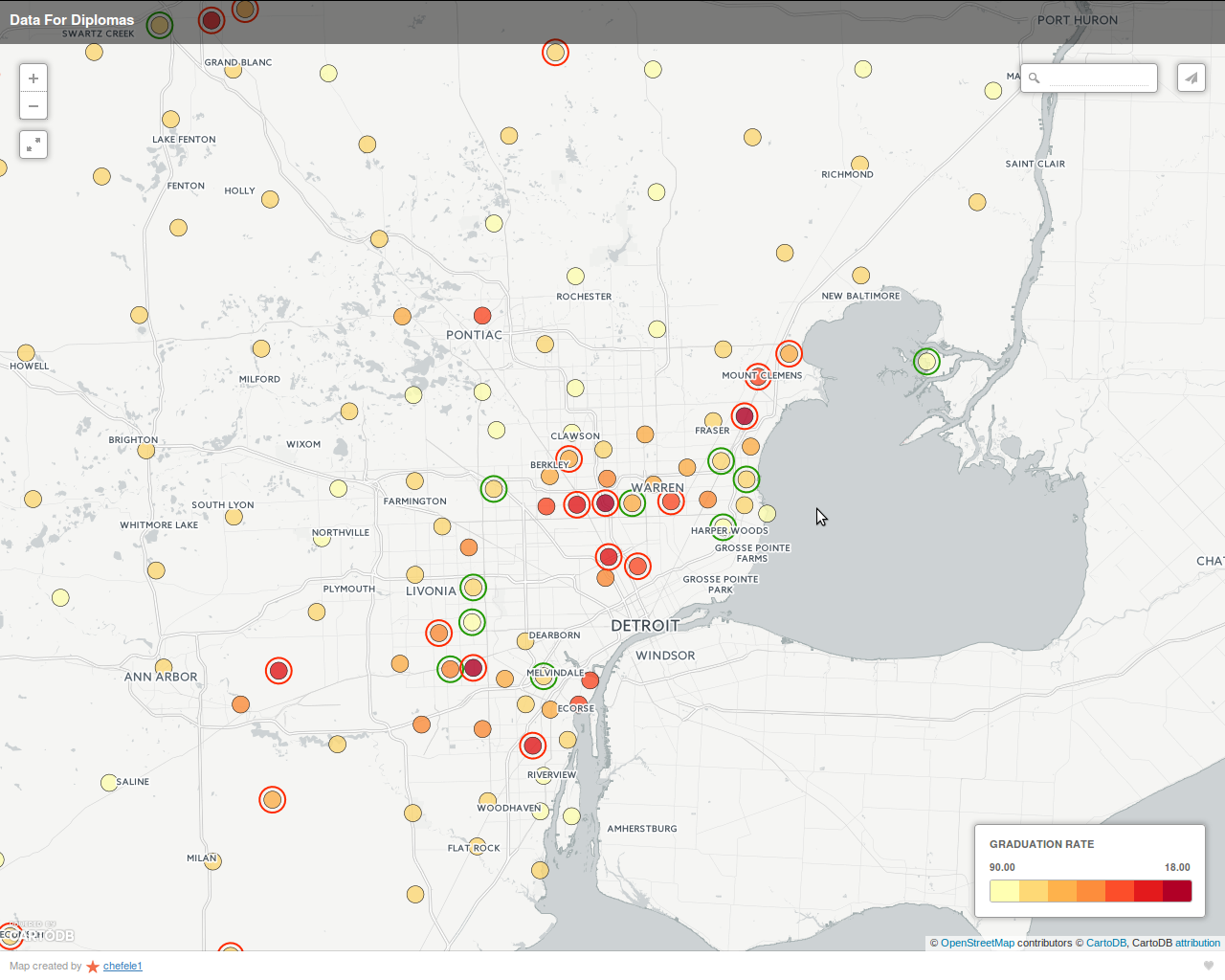
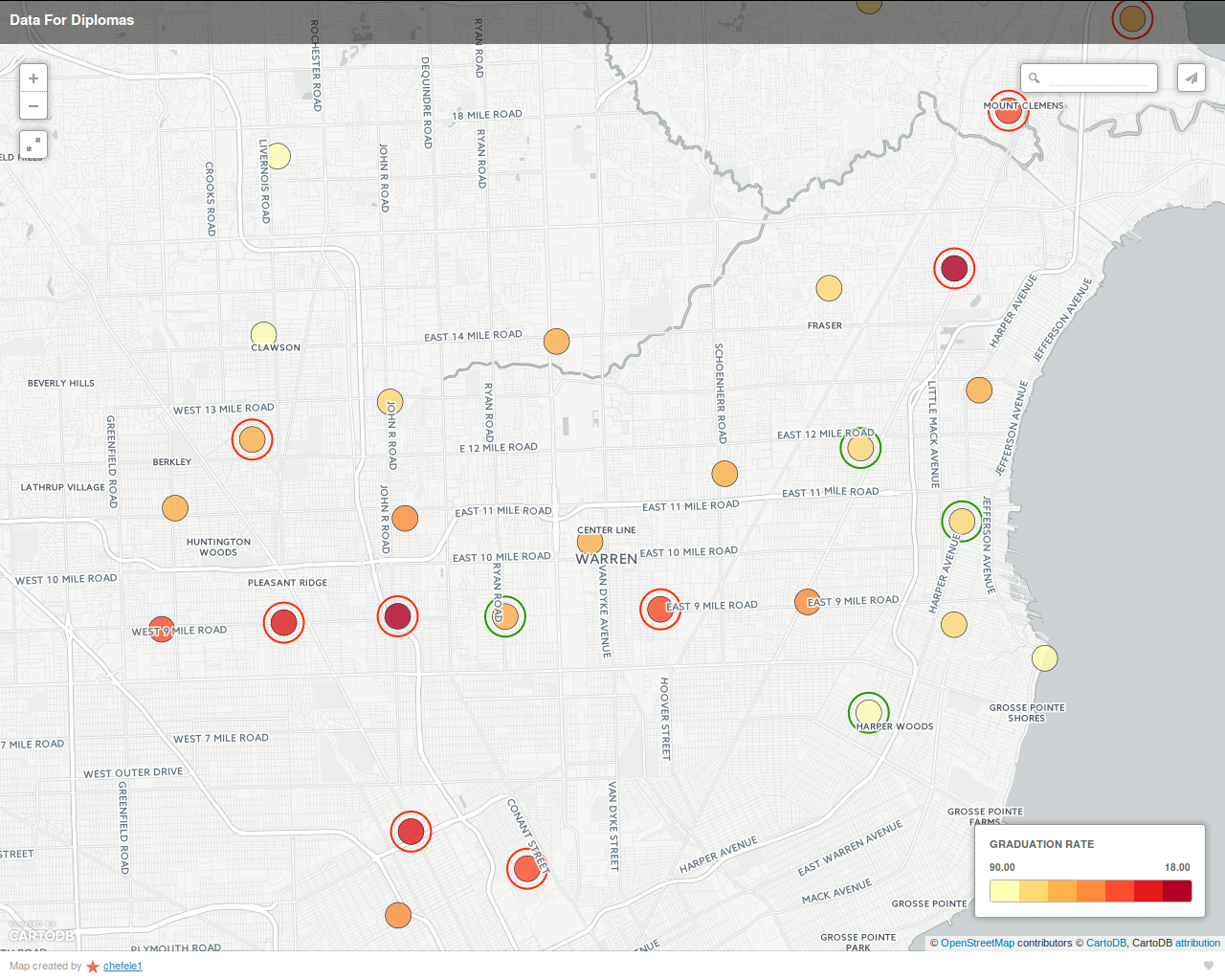
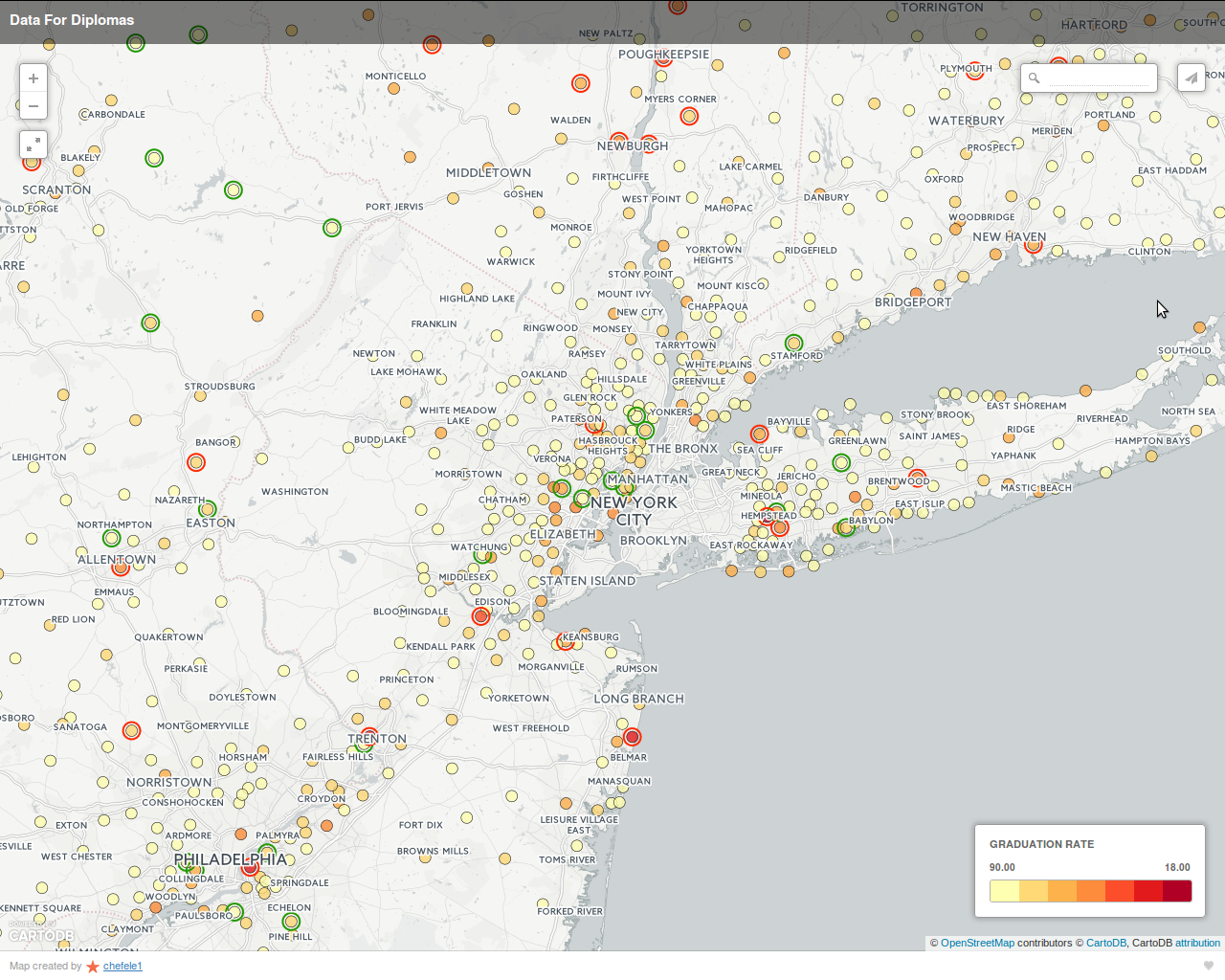
The screen-shots above show an interactive map that displays not only school districts and their graduation rates, but also their graduation rates relative to their expected graduation rates. The expected graduation rates were calculated using a machine-learning model that was trained on Census data.
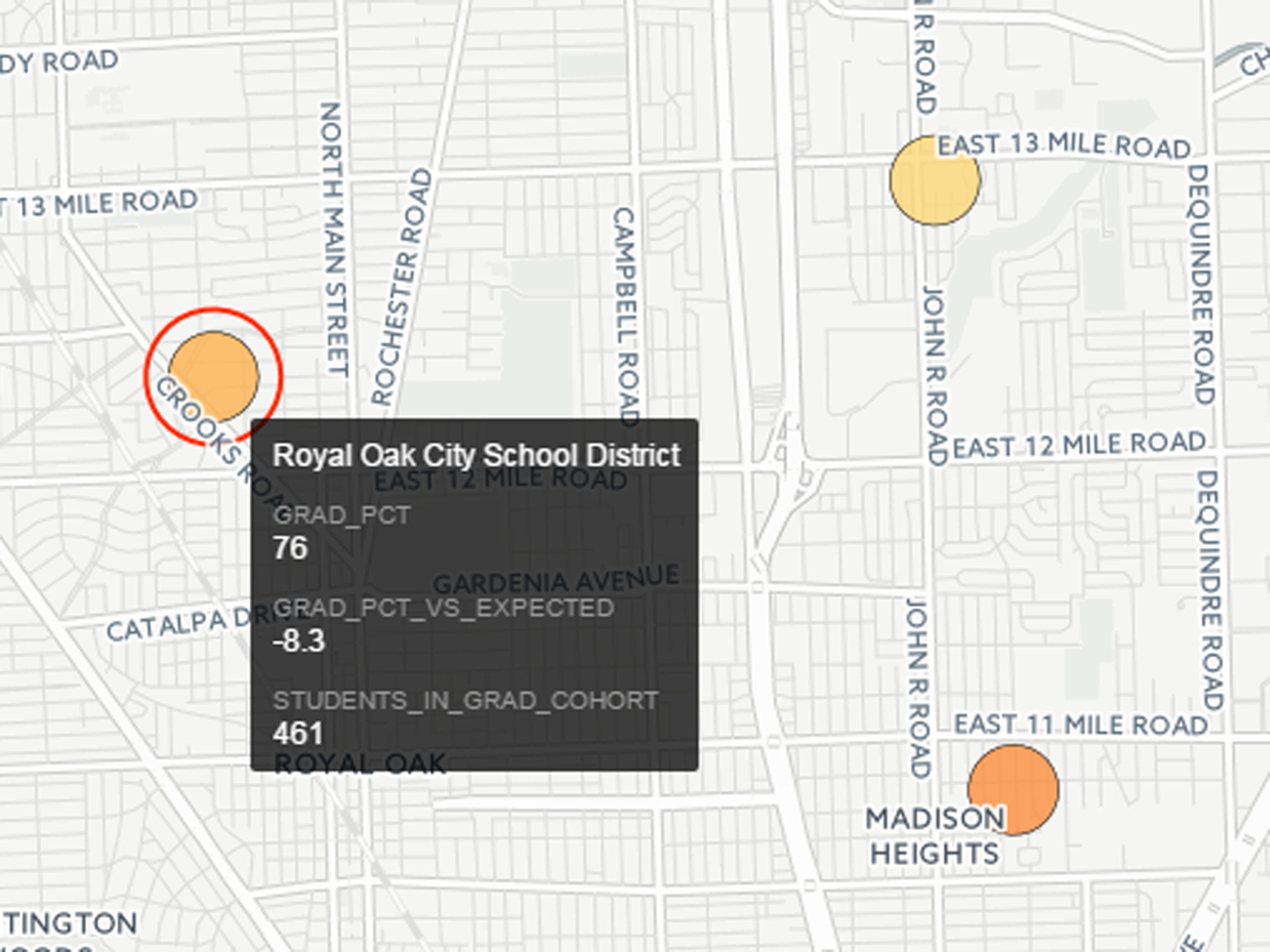
On the maps, school districts with a graduation rate 5% higher than expected (as predicted by the machine-learning model) are circled in green. Similarly, schools 5% or more below expectations are circled in red. The actual graduation rate is depicted by the color of the inner circle (yellow = highest graduation rate, red = worst). Hovering over a school district pops up an additional window with the school name and additional statistics: graduation rate, graduation rate relative to expectations, and number of students.
Relative performance can help distinguish "over-performing" schools from "under-performing" schools in ways that graduation rate alone cannot. For example, consider two schools with an 80% graduation rate, one in a poor urban area and the other in an affluent suburban area. Poverty has a significant negative impact on graduation rate, so the 80% graduation rate for the school in the poor area may be an achievement. In contrast, the 80% graduation rate for the more affluent school may be a disappointment.
This interactive map could be used by parents choosing between schools. It could also be used by school administrators who are trying to identify schools that may be under-performing relative to expectations, regardless of their graduation rate. It could also be used to identify the small subset of schools performing above expectations; those schools might be ones to investigate & emulate.
IMPACTS OF SCHOOL SIZE & RECOMMENDATIONS
The recent "small schools movement" holds that large, poorly performing high schools should be reorganized into multiple smaller schools. As part of this effort, the potential gains of reducing school size was assessed, using the machine learning model described below.
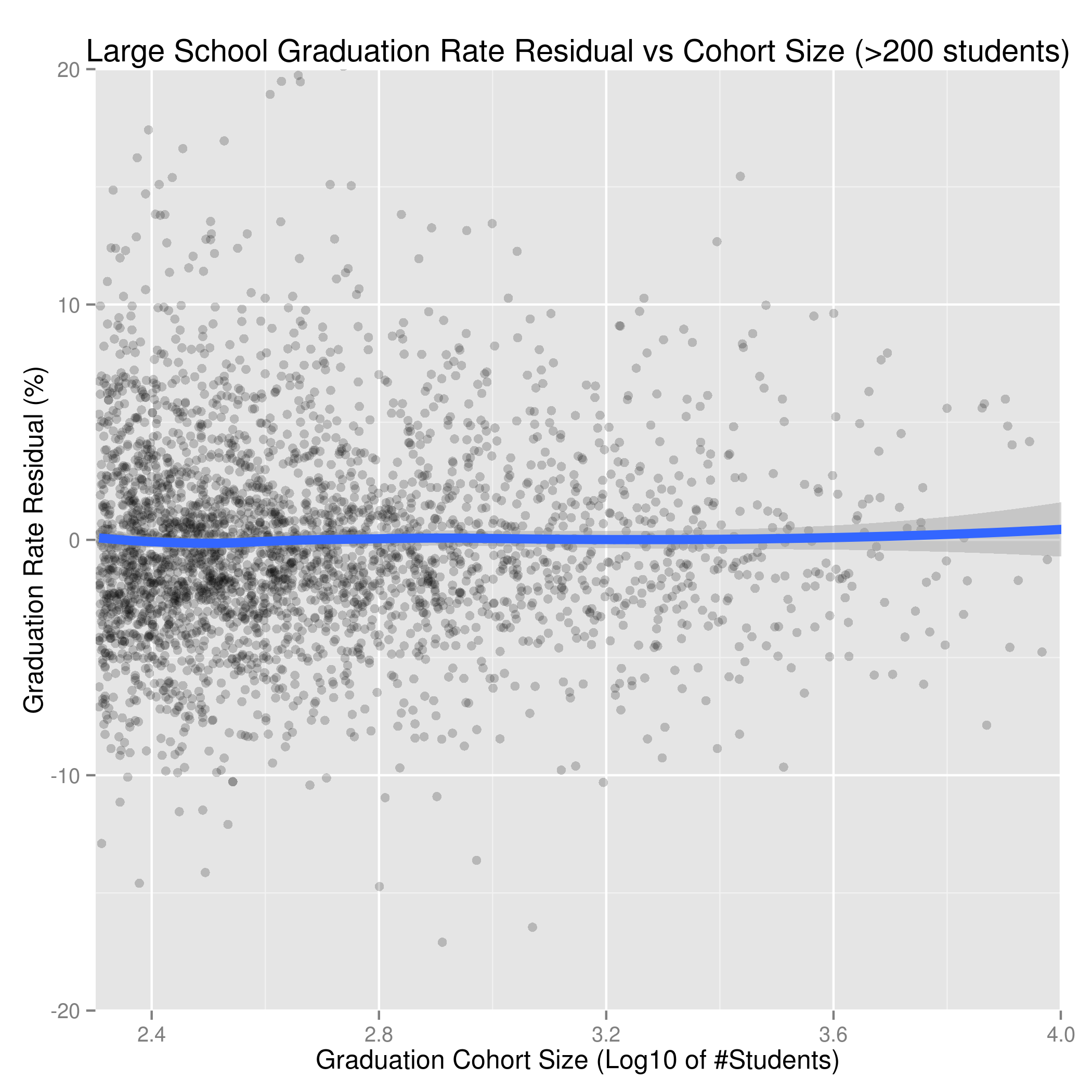
The results show little to no indication that school size had an influence on graduation rate, after controlling for 62 significant Census variables (e.g. demographics, income). School size had neither a positive or negative effect on its own, above and beyond the known impacts of poverty, demographics, etc.
Therefore, simply splitting large, poorly-performing schools into smaller schools may not be an effective way to increase graduation rates. School size changes should not be done in isolation in an attempt to correct for poverty, for example. However, reductions in school size could be done in conjunction with other reforms, if those other reforms might be enhanced by the school size changes.
MACHINE LEARNING MODEL
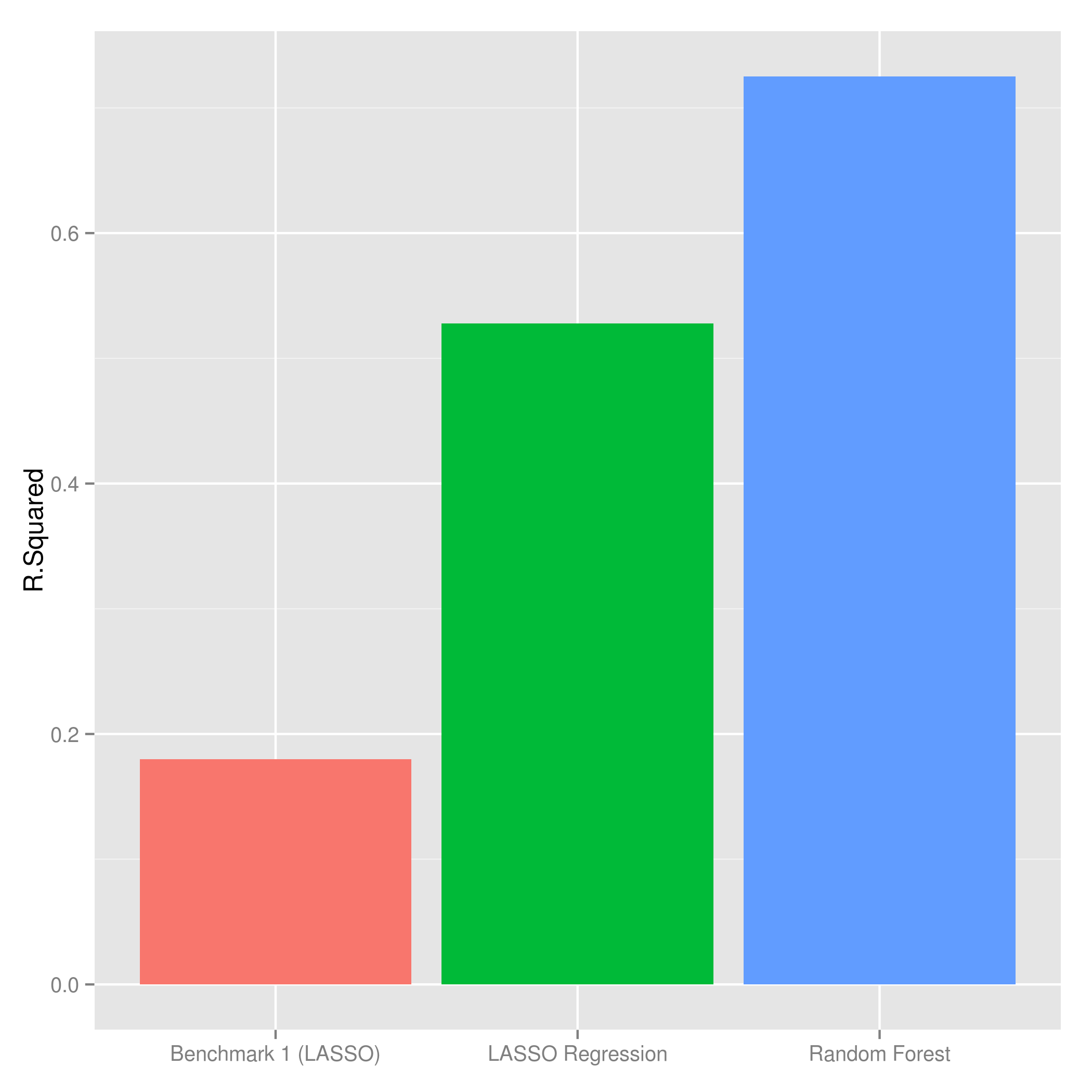
A machine-learning model was used to predict school graduation rates for the interactive map above, and to control for various factors in the school-size analysis. The Random-Forest algorithm that was used was significantly more accurate than linear methods (like linear regression) when applied to this competition’s dataset. It captured non-linearities that linear models missed, and required significantly fewer input variables.
The best performing random forest model captured 72% of variance, which was significantly higher than the 53% obtained using linear regression, and also higher than the 18%-25% achieved by the competition's "Benchmark #1."
CORRECTING SMALL vs LARGE SCHOOL BIASES IN THE DATA
One challenge in this work was working around an issue that distorted the graduation rate distributions for smaller schools.
Specifically, graduation rates were reported using ranges of varying size. For example, the smallest schools (<=15 students in the cohort) reported very wide ranges, e.g. GE50 (for greater or equal to 50%). Schools with 16-30, 31-60, and 60-200 students in the graduation cohort used progressively narrower ranges (e.g. 60%-79%). The largest schools (200+ students) were always reported exactly (e.g. 81%). The reason for these differences was not given.
The use of ranges was an issue because the pre-processing of range data can make small schools appear to have lower graduation rates than they actually do. The hackathon organizers wrote that when preparing GRADUATION_WITH_CENSUS.CSV, the median of reported ranges were used, and that any initial letters were dropped. So a smaller school's 75% graduation rate might be reported as a range (60%-79%), which in turn would appear in the dataset as 69.5% (the median of 60%-79%). Similarly, a very small school with a 75% graduation rate would report it using "GE50" (greater than or equal to 50%), which would appear in the dataset as 50%. In contrast, a large school (>200 students in cohort) with a 75% graduation would be reported accurately (as 75%).
Biasing smaller schools' graduation rates downward makes larger schools appear to have higher graduation rates. To work around this issue and allow proper comparisons between school districts, the analyses above were done after segmenting the graduation rates based on cohort size . The details are described in the paper.

Log in or sign up for Devpost to join the conversation.