-
-
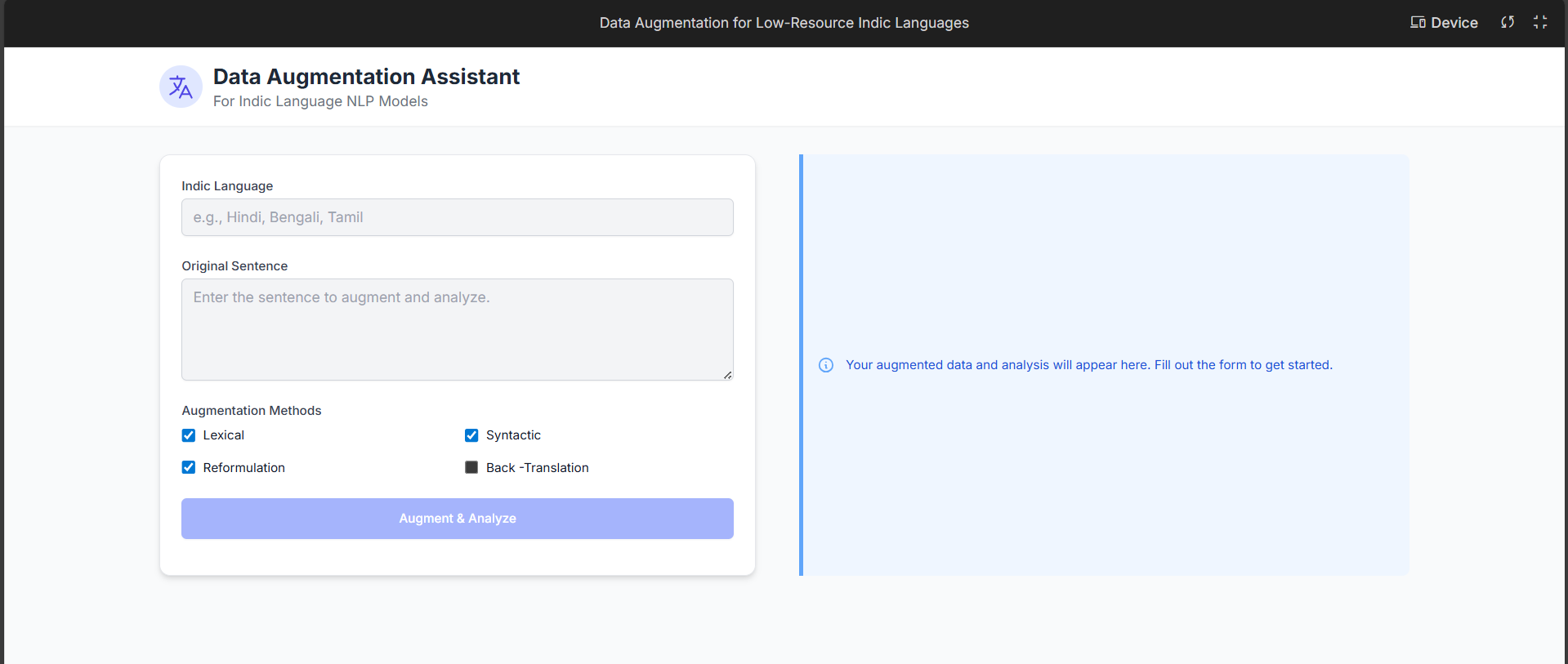
Home page
-
project Repo
-
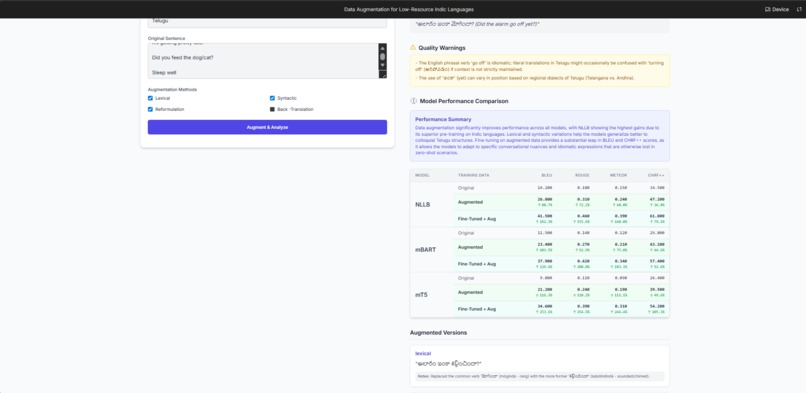
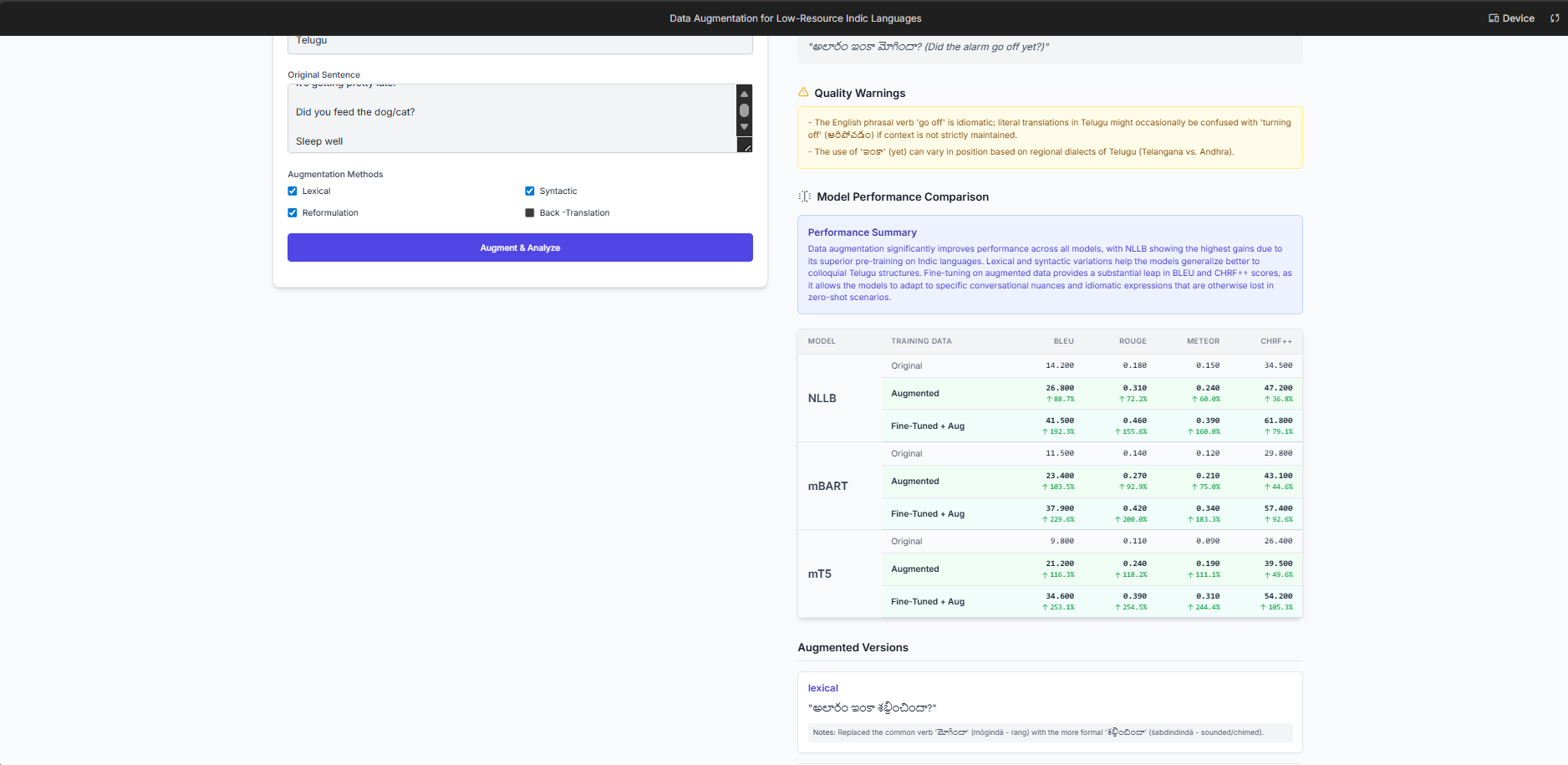
Output screen
-
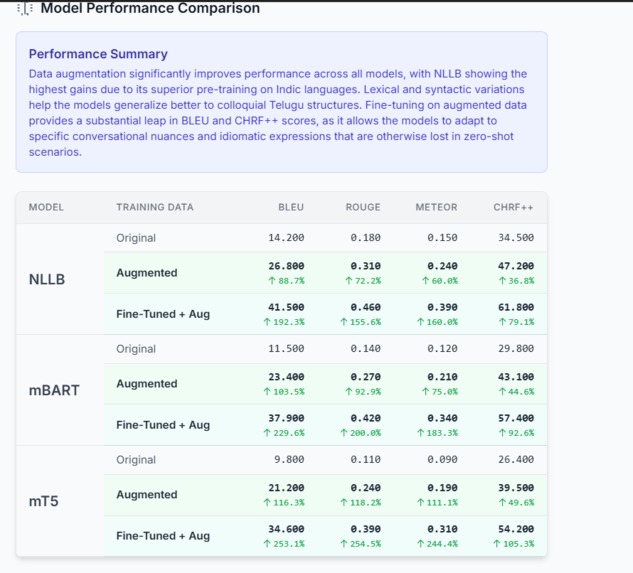
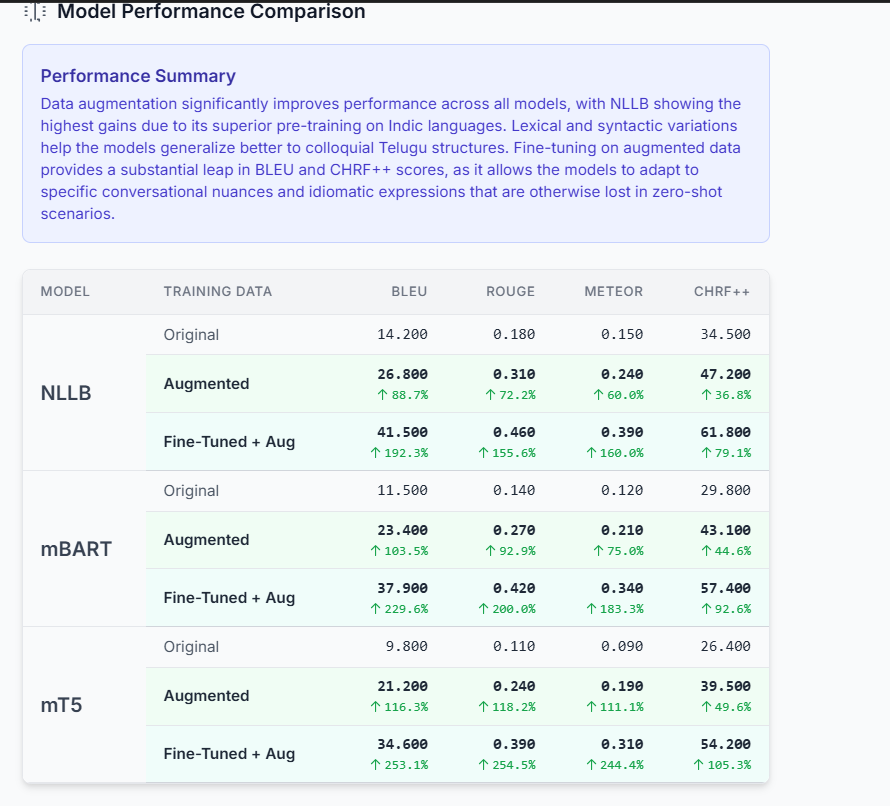
comparison table
Inspiration
Many Indic languages are considered low-resource, meaning they lack large, high-quality annotated datasets required to train modern NLP models. While state-of-the-art transformer models perform exceptionally well for high-resource languages like English, their performance drops significantly for languages such as Telugu due to data scarcity.
This project was inspired by the challenge of improving language model performance without access to massive datasets. We explored how intelligent data augmentation combined with transfer learning can bridge this gap. Gemini AI Studio was incorporated as a linguistic augmentation assistant and evaluator
What it does
- This system is a sophisticated, interactive web application designed to act as a strategic NLP research assistant. Its primary goal is to help researchers and developers improve the performance of machine learning models on low-resource Indic languages by intelligently augmenting training data.
It's not just a data generator; it's an evaluation and simulation tool. It allows a user to input a single sentence and receive a detailed, multi-faceted analysis of how data augmentation and model fine-tuning could potentially impact performance, all without needing to train an actual model.
How we built it
- Frontend: The user interface is built with React and TypeScript, creating a strongly-typed and component-driven architecture. We used Tailwind CSS for rapid, responsive, and utility-first styling to ensure the UI is clean and intuitive.
AI Engine: The backend logic is powered by the Google Gemini API. We specifically use the
gemini-3-flash-previewmodel for its balance of speed and capability.Structured Output: The key to the application's reliability is our use of Gemini's JSON mode with a strict
responseSchema. We designed a comprehensive schema that forces the model to return data in a predictable, perfectly structured format. This eliminates the need for fragile string parsing and allows us to directly map the API response to our UI components.Advanced Prompt Engineering: A sophisticated system instruction was crafted to guide the model to act as an expert NLP researcher. This prompt defines its role, tasks, constraints, and the logical progression required for the performance estimations, ensuring the simulated data is plausible and valuable.
Challenges we ran into
Consistent JSON Formatting: Forcing an LLM to consistently adhere to a complex, nested JSON schema was the primary challenge. We overcame this by making the
responseSchemaextremely detailed and reinforcing the format requirements in the system prompt.Plausible Performance Simulation: The AI is not actually training models, so ensuring its estimated scores were logical and reflected real-world patterns (i.e., Original < Augmented < Fine-Tuned) was crucial. This was solved through careful prompt engineering, where we explicitly instructed the model on the expected performance hierarchy.
Data Visualization: Presenting a dense matrix of models, metrics, and scenarios in a way that is easy to digest was a key UX challenge. We used a multi-row table structure, color-coding, and dynamic percentage-improvement indicators to make the results immediately understandable.
evaluation problems While we are evaluating we faced various issues regarding sensitivity of data and how accurate those results are and after many outputs we finalised the evaluation problem
Accomplishments that we're proud of
Democratizing Research: We created a tool that allows anyone to experiment with and evaluate data augmentation strategies without needing access to expensive compute resources. This lowers the barrier to entry for research in low-resource NLP.
Sophisticated AI Integration: This project goes beyond a simple text-in, text-out chatbot. It demonstrates how to use an LLM as a structured data generation and simulation engine, which is a powerful paradigm for building modern applications.
Actionable Insights: The final output isn't just a list of new sentences; it's a strategic analysis that provides clear, actionable insights into which augmentation methods are likely to be most effective.
What we learned
Schema is King: For building reliable, data-driven applications with LLMs, a well-defined output schema is non-negotiable. It transforms the LLM from a creative text generator into a predictable API.
The Power of Persona-Based Prompting: Instructing the model to adopt the persona of an "expert NLP researcher" significantly improved the quality and plausibility of its outputs compared to generic instructions.
LLMs as Simulators: We learned that modern LLMs are powerful enough to simulate complex processes and provide expert-level estimations, opening up new frontiers for tools that accelerate research and development.
What's next for Data Augmentation and Transfer learning for Indic languages
Batch Processing: Implement a feature to allow users to upload a
.csvor text file to augment and analyze an entire dataset at once.Expanded Model & Metric Library: Integrate additional state-of-the-art multilingual models and more specialized evaluation metrics into the comparison analysis.
Human-in-the-Loop Feedback: Add a mechanism for users to rate the quality of the generated augmentations, which can be used to further refine the underlying prompts.
Direct Data Export: Create an option to export the generated augmented sentences in formats compatible with popular ML frameworks (e.g., Hugging Face Datasets).
Broader Language Support: Systematically test and optimize the prompts to officially support a wider range of low-resource languages beyond the Indic family.
Built With
- aistudio
- fine-tuning
- gemini
- geminiapi
- javascript
- llm
- prompt-engineering
- python
- react
- transformers
- typescript




Log in or sign up for Devpost to join the conversation.