-
-
Intro page
-
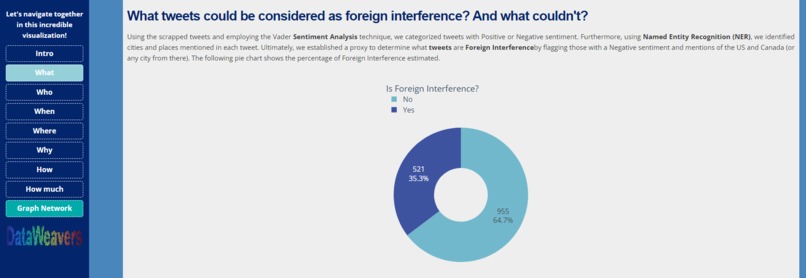
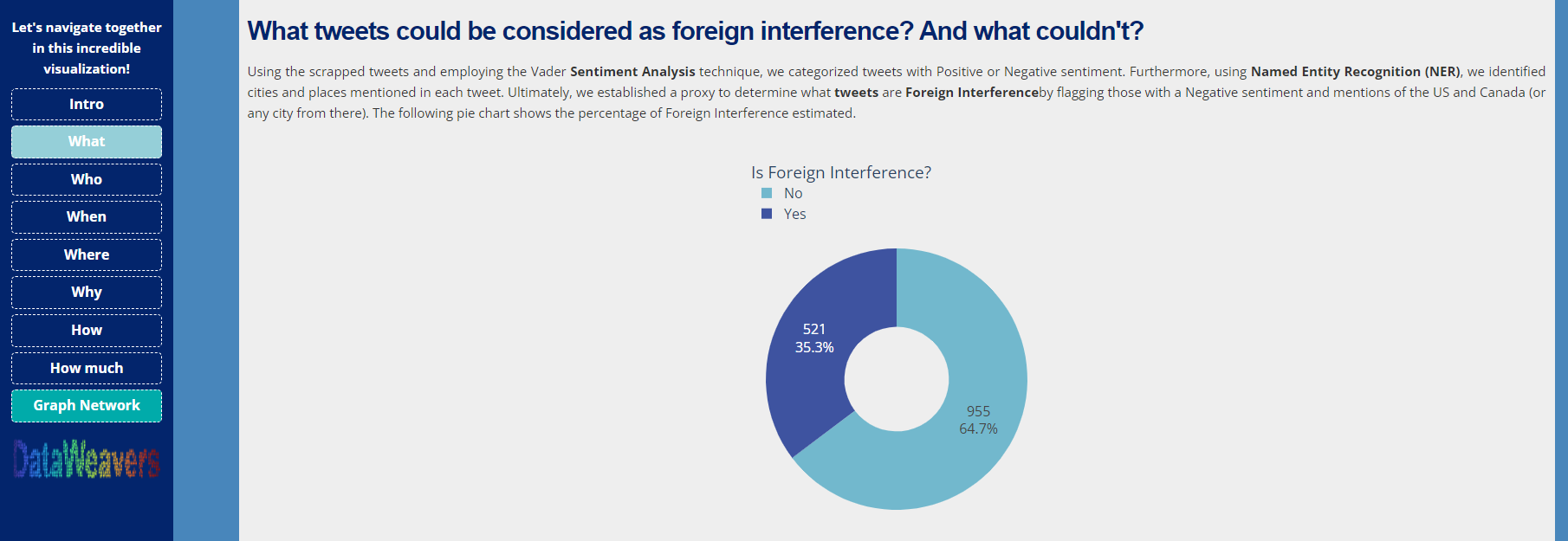
What page
-
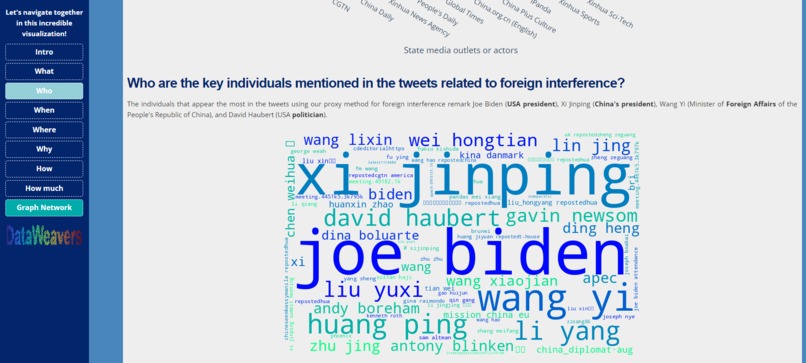
Who page
-
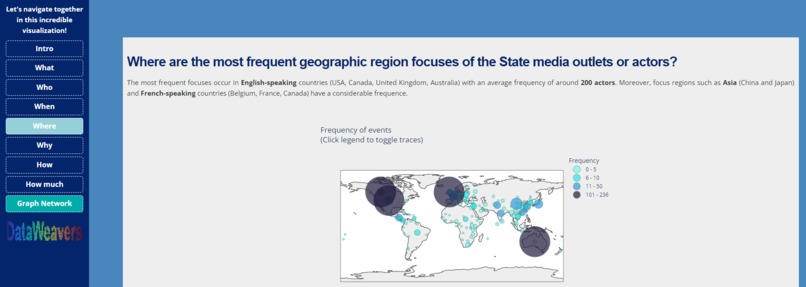
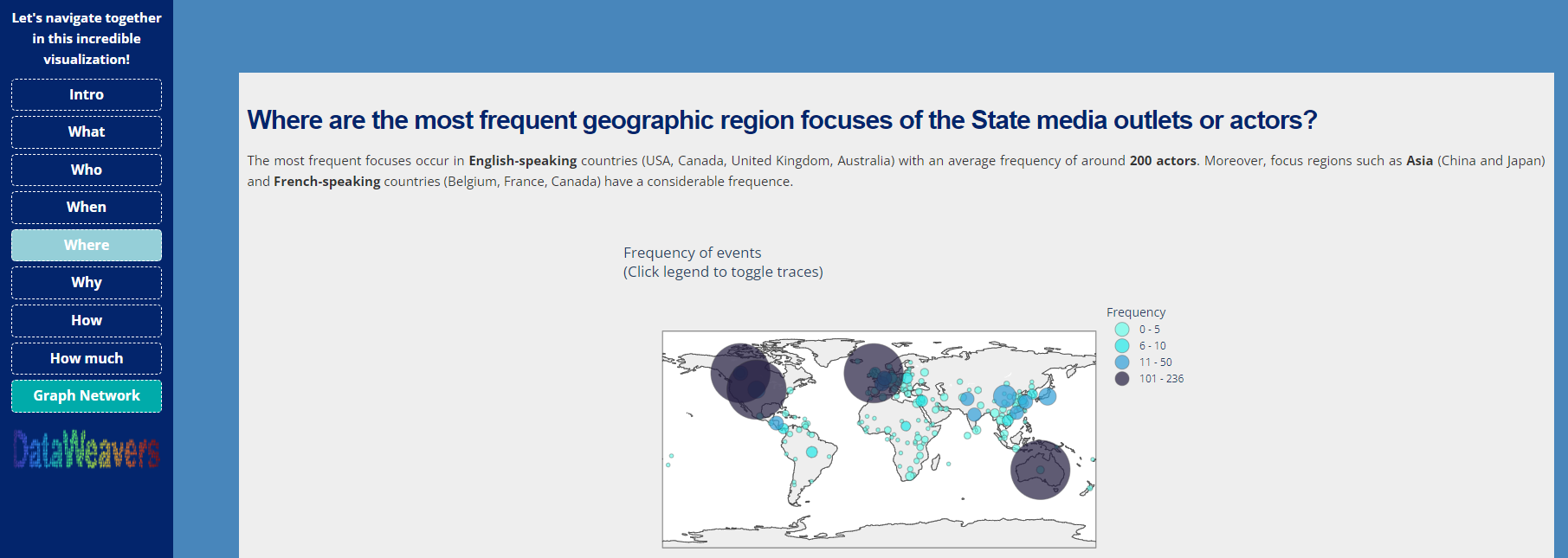
Where page
-
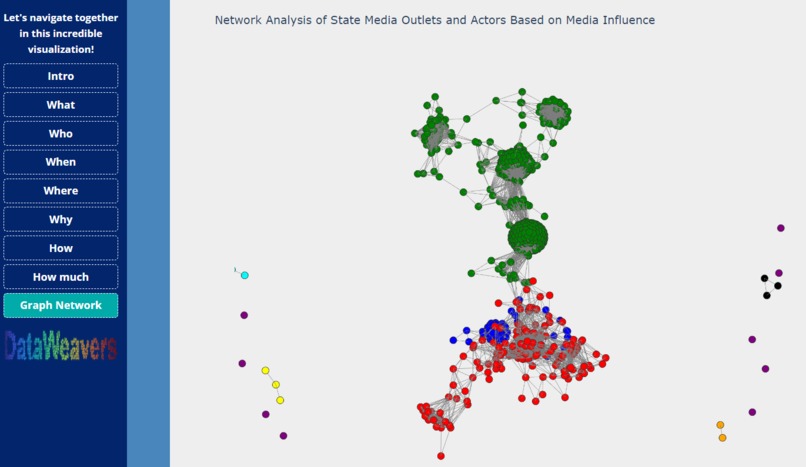
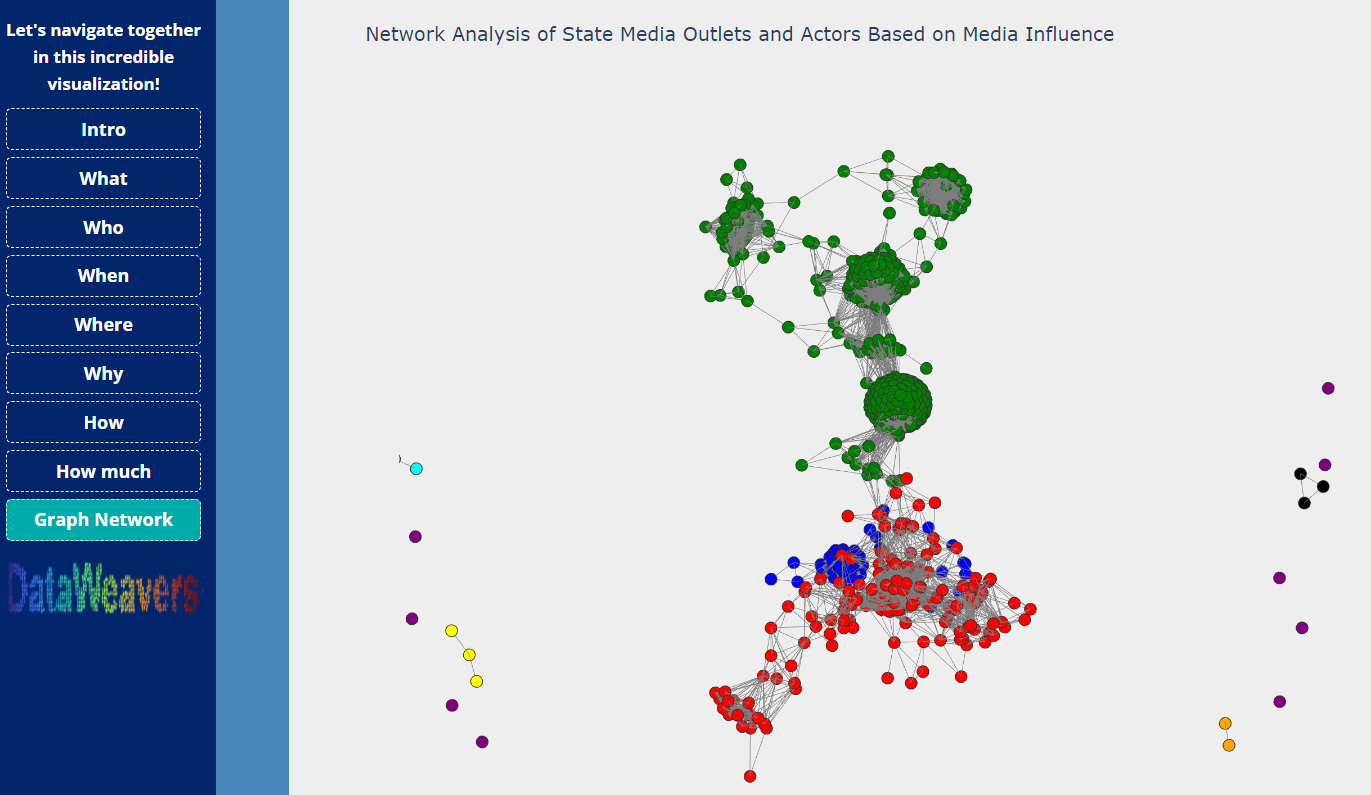
Graph network


Inspiration
The inspiration for "5W2H-4-Foreign-Interference" stemmed from a collective curiosity about understanding the impact of foreign interference on various media actors from China. The given data was good but insufficient to analyze what we wanted, so we tried to find more useful data. The 5W2H is suited perfectly to answer the required questions systematically.
What it does
5W2H Methodology
We adopted the 5W2H methodology—Who, What, When, Where, Why, How, and How much—as the foundation for our analysis. This structured approach allowed us to systematically dissect and comprehend the multifaceted aspects of foreign interference.
Web Scraping
To collect Twitter data, we implemented web scraping. This enabled us to capture useful information, ensuring our dashboard had relevant insights into foreign interference.
Named Entity Recognition (NER)
Integrating NER was instrumental in identifying and categorizing entities involved in the tweets. Whether it was people mentioned or cities and countries, NER played a pivotal role in enhancing the granularity of our analysis.
Sentiment Analysis
Using the Vader approach for analyzing the sentiment of tweets and online content was crucial in gauging foreign interference's emotional tone and potential impact. This aspect provided a deeper understanding of the narrative being shaped and the key asset to create a proxy of foreign interference.
Graph and Community Detection
We leveraged graph theory (cosine similarity-based graph) and community detection algorithms (Girvan-Newman and others) to visualize the intricate relationships between actors. This facilitated a clear representation of networks and identified communities of coordinated foreign interference.
How we built it
We employed Selenium from Python to retrieve the Twitter data. The questions were solved using Python and Google Colab. The dashboard was created in Dash and D3. We used Render and GitHub to deploy the web app.
Challenges we ran into
The application is not online (active) the whole time. It is necessary to wait 2-3 minutes for the system to start the app the first time Getting additional data from Twitter was challenging, but the team retrieved enough. Some algorithms tried for sentiment analysis (BERT) were too slow to execute. The application needed a lot of details to be good, but we managed to have an MVP of it in record time.
Accomplishments that we're proud of
We achieved Twitter data extraction, a problem reported by several competence teams. Creating an app in record time, which is interactive and well-designed. Gaining insights from data analysis and creating a nice graph interactive network.
What We Learned
Throughout the project, we delved into the intricate world of data analysis and strategic information extraction (web scraping). We gained valuable insights into the challenges of foreign interference and honed our skills in utilizing diverse graph theory techniques. We also obtained new skills for making impactful presentations. Finally, we got experience in Natural Language Processing (NLP) analysis.
What's next for 5W2H-4-Foreign-Interference by DataWeavers
Optimize the tweets’ extraction code for more extensive and efficient analysis. Analyze tweets using NLP algorithms trained on large datasets, i.e., Large Language Models (LLM). Explore data-gathering methods from social media platforms, such as APIs, web scraping libraries, etc., to examine the dynamics of each platform.

Log in or sign up for Devpost to join the conversation.