-
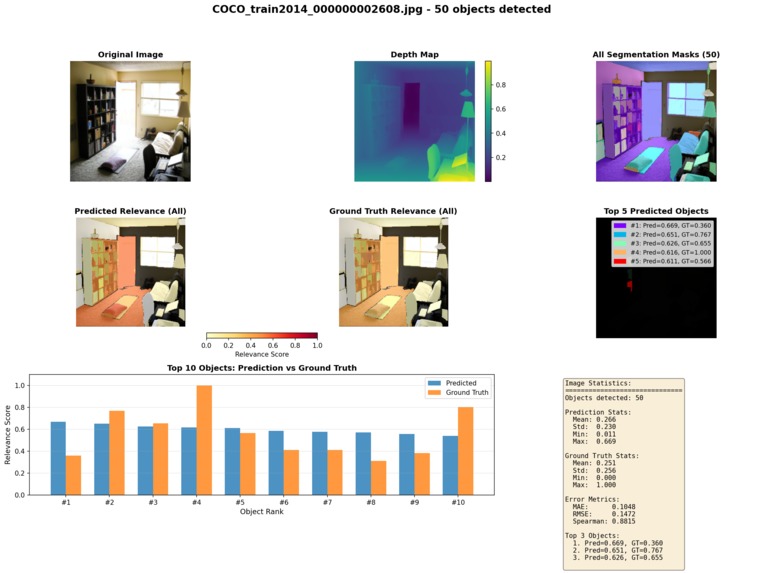
Input image, outputs of our Depth Anything and Segment Anything pre-trained models, and output of our custom transformer.
-
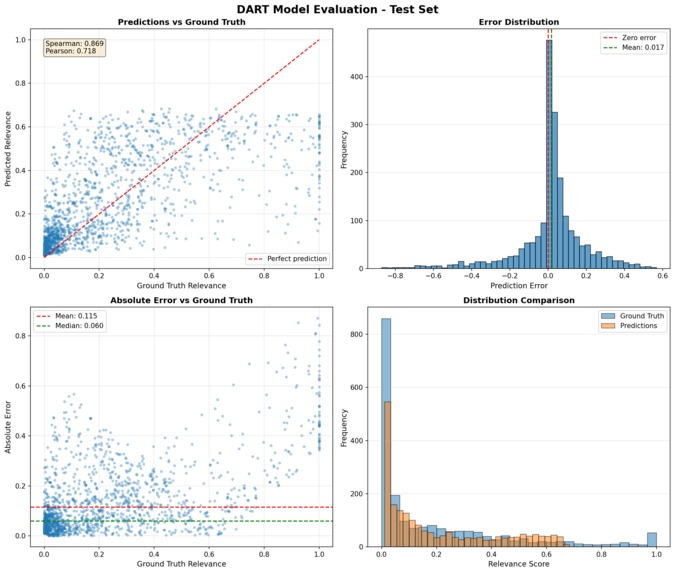
Evaluation of our model's performance against relevance score labels.
Our project introduces the Depth-Aware Relevance Transformer (DART), a model designed to predict how important different regions of an image are by combining RGB appearance, depth cues, and spatial information. Existing approaches either focus on pixel-level saliency or on object detection confidence, but neither captures contextual importance at the object level. By creating segment-level tokens from RGB crops, depth statistics, and geometric features, and then passing them through a custom transformer, our model aims to learn how objects interact within a scene and which ones draw more human attention. This capability is useful for tasks such as assistive image captioning, robotic scene understanding, and general visual summarisation.
Modern computer vision systems lack the ability to evaluate the contextual importance of objects within a scene. Existing methods either focus on pixel-level attention, such as saliency prediction models like SALICON, which generate visual attention maps, or operate at the class level through object detection, which provides confidence scores but not context-aware relevance. Currently, no widely adopted model assigns task-independent importance scores to individual segmented regions while jointly leveraging RGB appearance, spatial geometry, and depth information.
Such a capability is crucial for applications that depend on intelligent prioritisation, including image captioning, robotic scene understanding, autonomous navigation, and content summarisation. By identifying which objects matter most in context, downstream systems can allocate resources more effectively and focus on the most meaningful elements of a scene.
The downstream goals of our project’s directive are to enable navigational assistance technology for persons with impediments or disabilities that prevent them from detecting salient objects, obstacles, and characteristics in their environment. One example of its application is through a wearable camera-attached audio-assist device that chains DART with a language model to narrate salient objects and events in a person’s proximity. In the context of robotics, DART can be used to enable robots greater contextual awareness of their environment, providing object saliency information useful to robotic limbs built to manipulate their surroundings. Using street-level surveillance camera information as input, DART may also be used to provide public service information to government organisations such as road congestion.
Built With
- pytorch
- salicon

Log in or sign up for Devpost to join the conversation.