Inspiration
Every day, clinicians spend hours manually cross-referencing lab results, medication lists, imaging reports, and clinical notes scattered across fragmented EHR systems — time stolen from patient care. We saw a specialist physician spend 45 minutes piecing together a patient summary before a ward round. That shouldn't happen in 2026. We asked: what if an AI could function as a virtual attending physician — one that never sleeps, never misses a drug interaction, and synthesises an entire patient record in seconds?
What it does
Our system is a production-grade clinical decision support platform built on Google's Agent-to-Agent (A2A) protocol. A clinician types a natural-language question into Prompt Opinion — and our orchestrator activates the right specialist agents automatically.
Eight AI agents collaborate in real time:
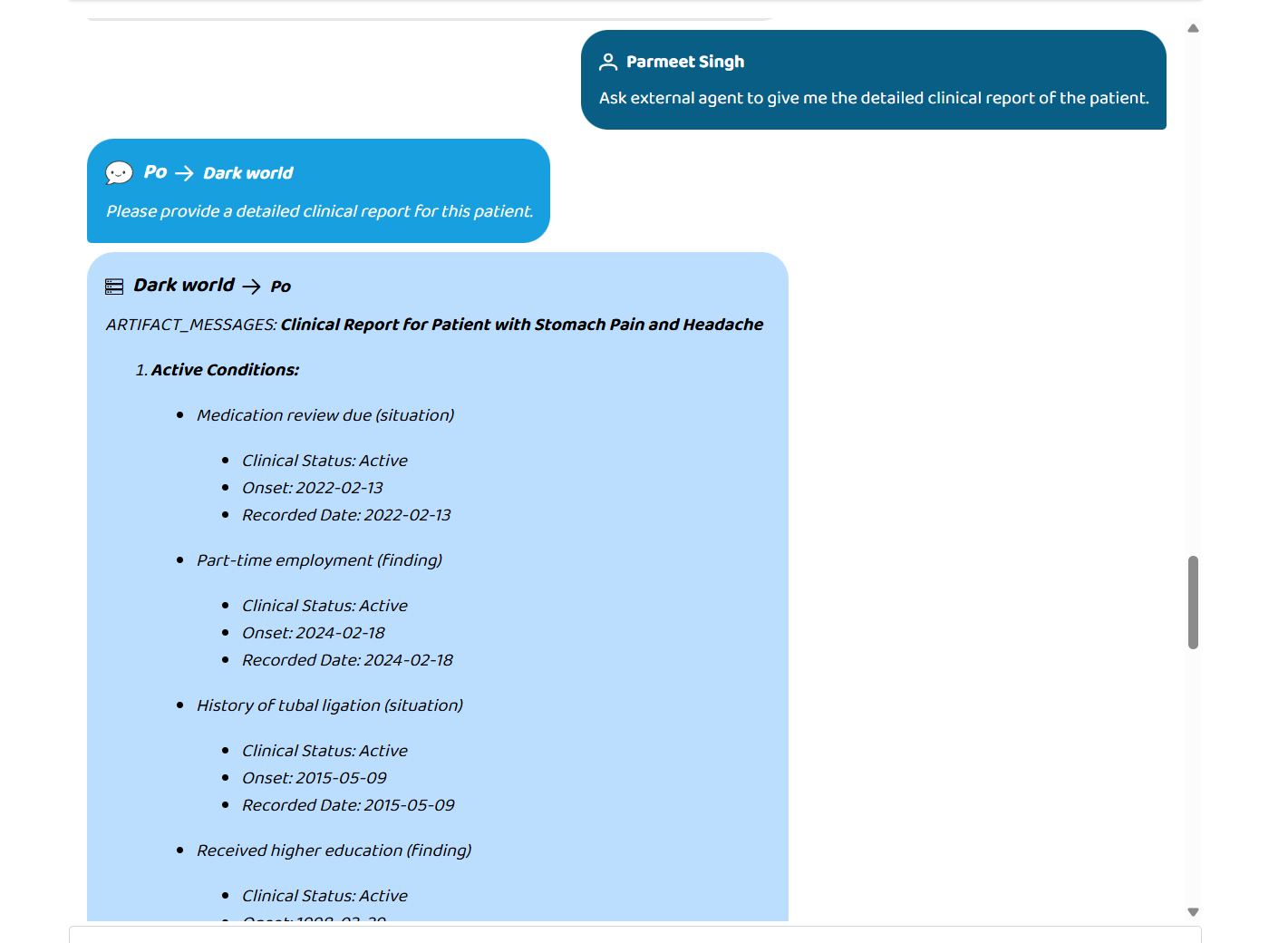
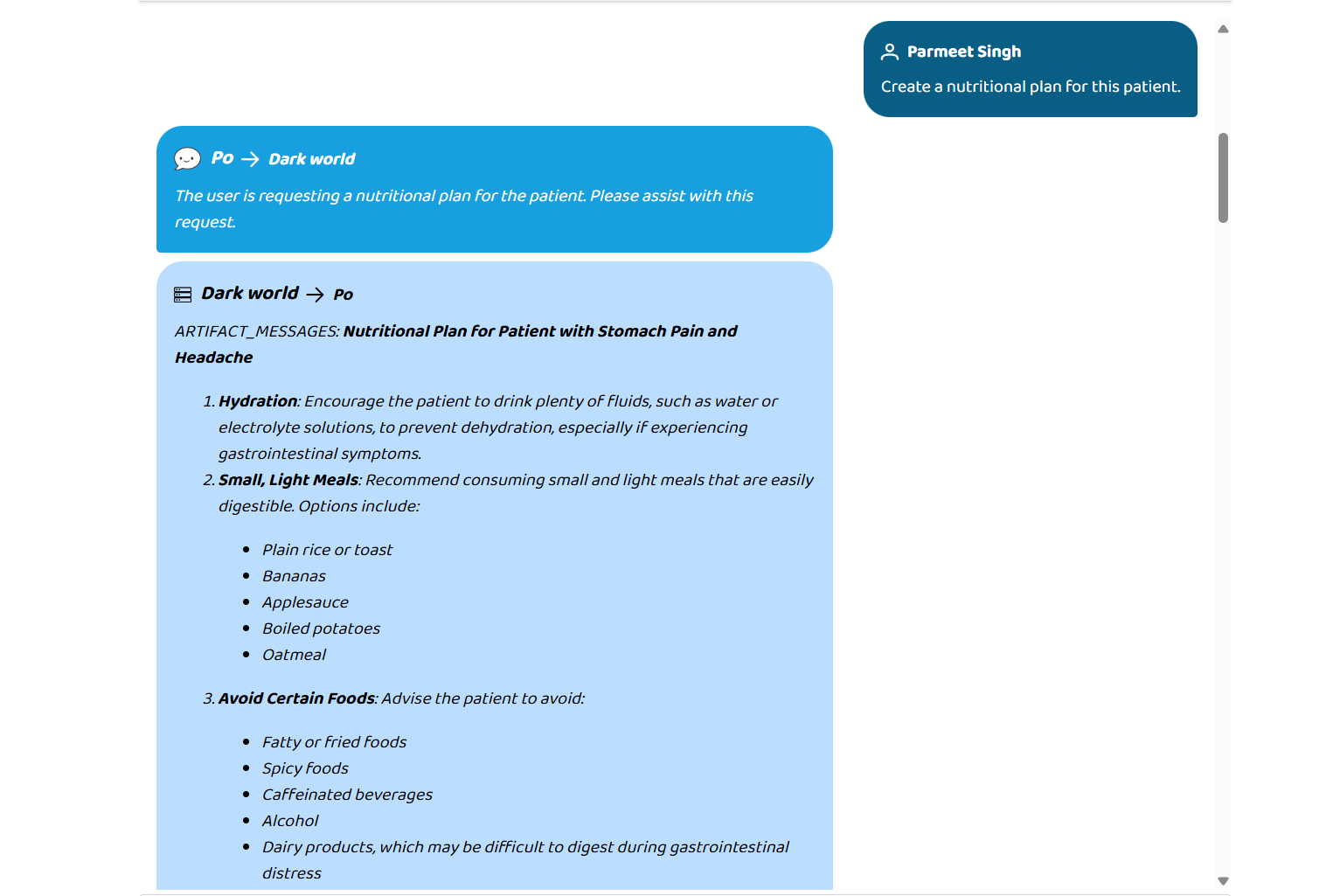
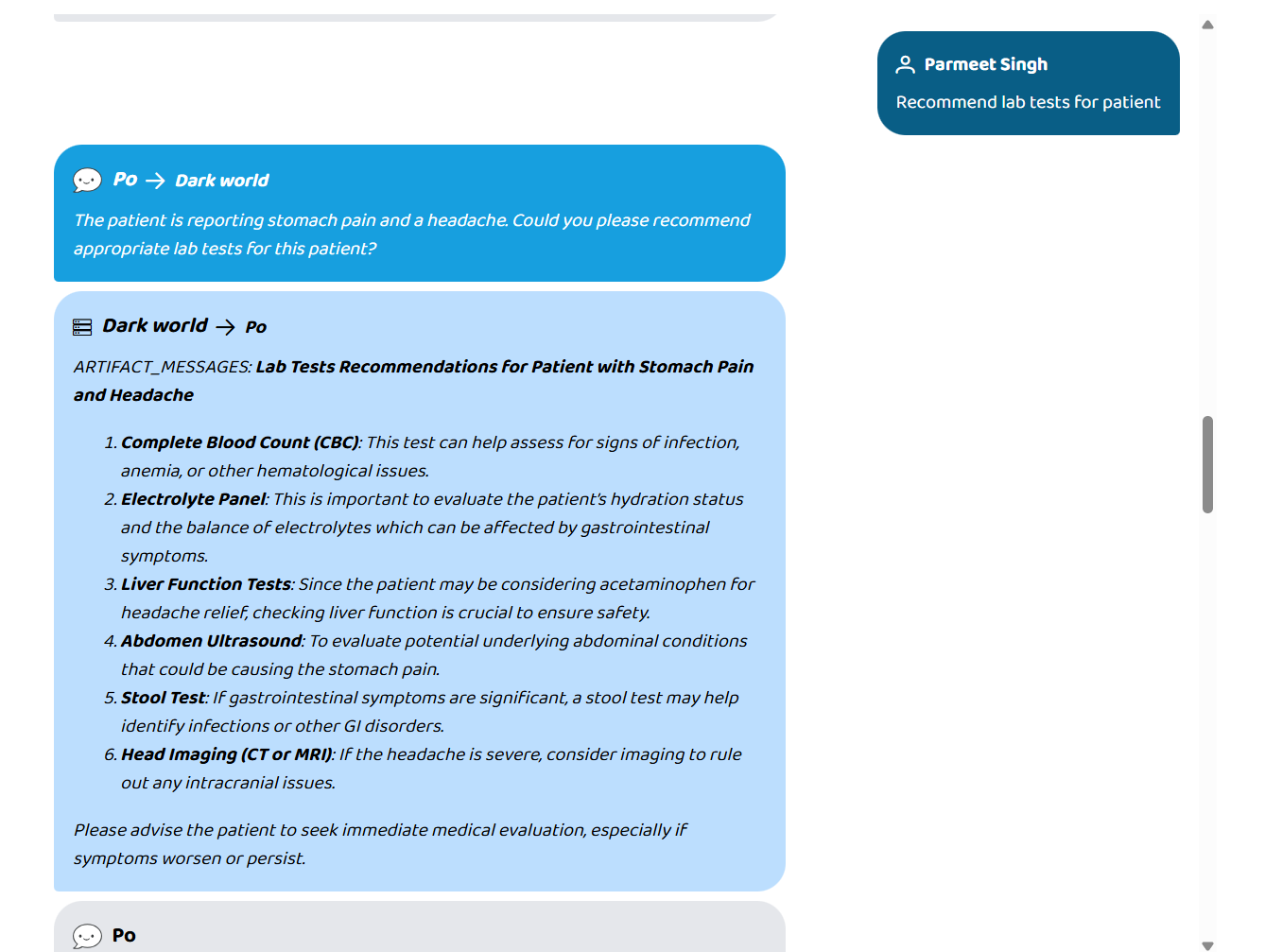
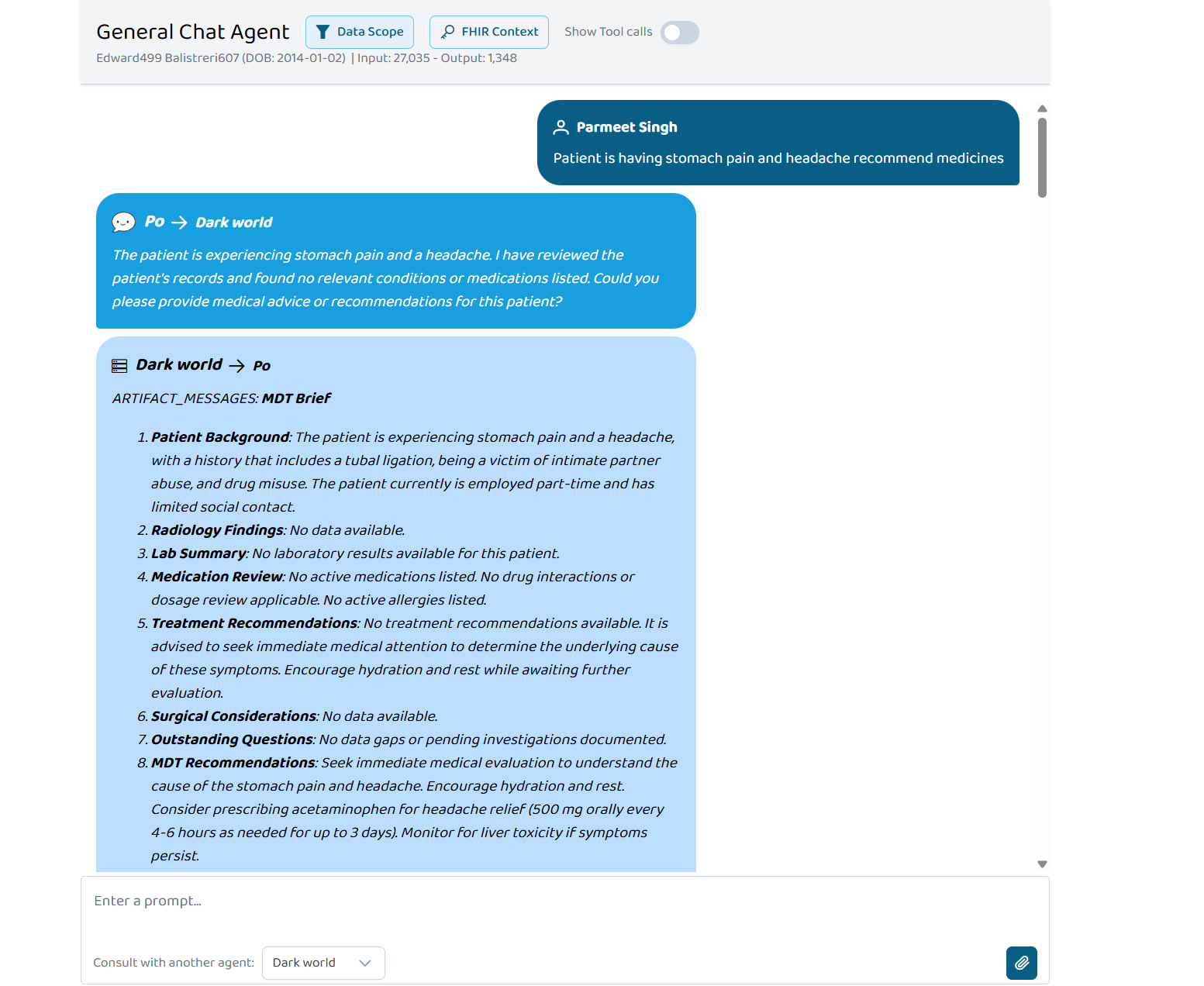
- Patient Records — pulls demographics, conditions, and medications from a live FHIR R4 server
- Lab Diagnostics — interprets blood work and flags abnormal trends
- Pharmacist — detects drug interactions with severity ratings (major / moderate / minor)
- Radiology — surfaces imaging findings
- Clinical Notes — summarises discharge notes and clinical history
- Surgical Planning — assesses pre-operative risk
- Attending Doctor — generates evidence-based treatment recommendations
- MDT Coordination — synthesises everything into a multi-disciplinary team brief
The response is grounded in real FHIR data, validated by output guardrails, and returned in seconds — not hours.
How we built it
- A2A v1 Protocol — a single Orchestrator endpoint on port 8003 handles all agent communication, publishing a standards-compliant agent card at
/.well-known/agent-card.jsonthat Prompt Opinion discovers automatically - CrewAI hierarchical crew — eight specialist agents run in-process; a keyword classifier performs dynamic task routing, activating only the agents relevant to each query
- FHIR R4 integration — credentials travel securely in A2A message metadata, never touching the LLM prompt
- RAG memory — ChromaDB with sentence-transformers gives every agent persistent long-term memory across sessions
- Patient chat history — stored in PostgreSQL and prepended to each query for full conversation continuity
- Output guardrails — a custom validator checks for hallucination indicators, verifies clinical claims are grounded in FHIR data, prevents PII/token leakage, and sanitises output before it reaches the clinician
- One-command deployment — the entire stack runs with
docker-compose up
Challenges we ran into
- A2A spec compliance — implementing the full v1 agent card schema (
supportedInterfaces, SMART-on-FHIR scopes, security schemes) correctly so Prompt Opinion could auto-discover our agents took significant iteration - FHIR credential security — ensuring credentials flowed through A2A metadata and were never serialised into LLM prompts required a careful architecture review
- Dynamic task routing accuracy — tuning the keyword classifier to correctly activate the right subset of agents without over- or under-firing across diverse clinical queries
- Hallucination guardrails — defining reliable heuristics for grounding checks without blocking legitimate clinical language that lacks explicit FHIR citations
- Agent coherence in hierarchical crew — getting eight agents to produce a unified, non-contradictory output required careful prompt engineering and result synthesis in the MDT agent
Accomplishments that we're proud of
- Built a fully A2A v1 compliant multi-agent system that Prompt Opinion discovers and invokes with zero manual wiring
- Achieved 40–60% latency reduction through dynamic task routing — irrelevant agents are never invoked
- Delivered end-to-end FHIR security — no credentials, no PHI, no API tokens ever leak into an LLM context window
- Built production-grade guardrails covering hallucination detection, PII scrubbing, and clinical grounding checks
- The entire system — eight agents, RAG, PostgreSQL, ChromaDB — deploys from a single
docker-compose upcommand
What we learned
- The A2A protocol is genuinely powerful for healthcare: the agent card's skill taxonomy maps naturally to clinical specialties, and the metadata channel is the right place for sensitive credentials
- Dynamic routing matters more than raw model quality — sending only relevant context to each specialist agent produced more accurate, faster responses than a single monolithic prompt
- Guardrails are non-negotiable in clinical AI — even well-grounded models occasionally hedge with language that could mislead a clinician; automated output validation is essential, not optional
- FHIR R4 is rich but inconsistent — real-world FHIR servers return incomplete or missing resources; resilient tooling that degrades gracefully is critical
What's next for Agentic Medical Team
- SMART-on-FHIR OAuth — replace API key auth with full SMART launch flow for EHR-embedded deployment
- Streaming responses — implement A2A streaming so clinicians see agent outputs appear incrementally, reducing perceived latency
- Additional specialist agents — Cardiology, Oncology, and Psychiatry agents are already scoped
- Audit trail & explainability — every clinical recommendation linked back to the specific FHIR resource that grounded it, for regulatory compliance
- Multi-patient dashboard — extend beyond single-patient Q&A to ward-level triage and escalation prioritisation
- Clinical trial matching — integrate a trial eligibility agent that cross-references patient conditions against open trials in real time
Built With
- agents
- crewai
- docker
- docker-compose
- fhir-r4
- google-a2a-sdk
- google-adk
- google-gemini
- httpx
- litellm
- pgvector
- postgresql
- python
- rag
- render
- sentence-transformers
- smart-on-fhir
- uvicorn

Log in or sign up for Devpost to join the conversation.