Inspiration
37% of active shootings last less than 5 minutes, and the rest last less than 15 minutes. With police response times ranging from 5-15 minutes, every minute is crucial. We created a video surveillance system to help decrease this response time by cutting out the lag due to human interaction. With over 285 million surveillance cameras, this software could help immensely by alerting the proper authorities about large problems the second they occur.
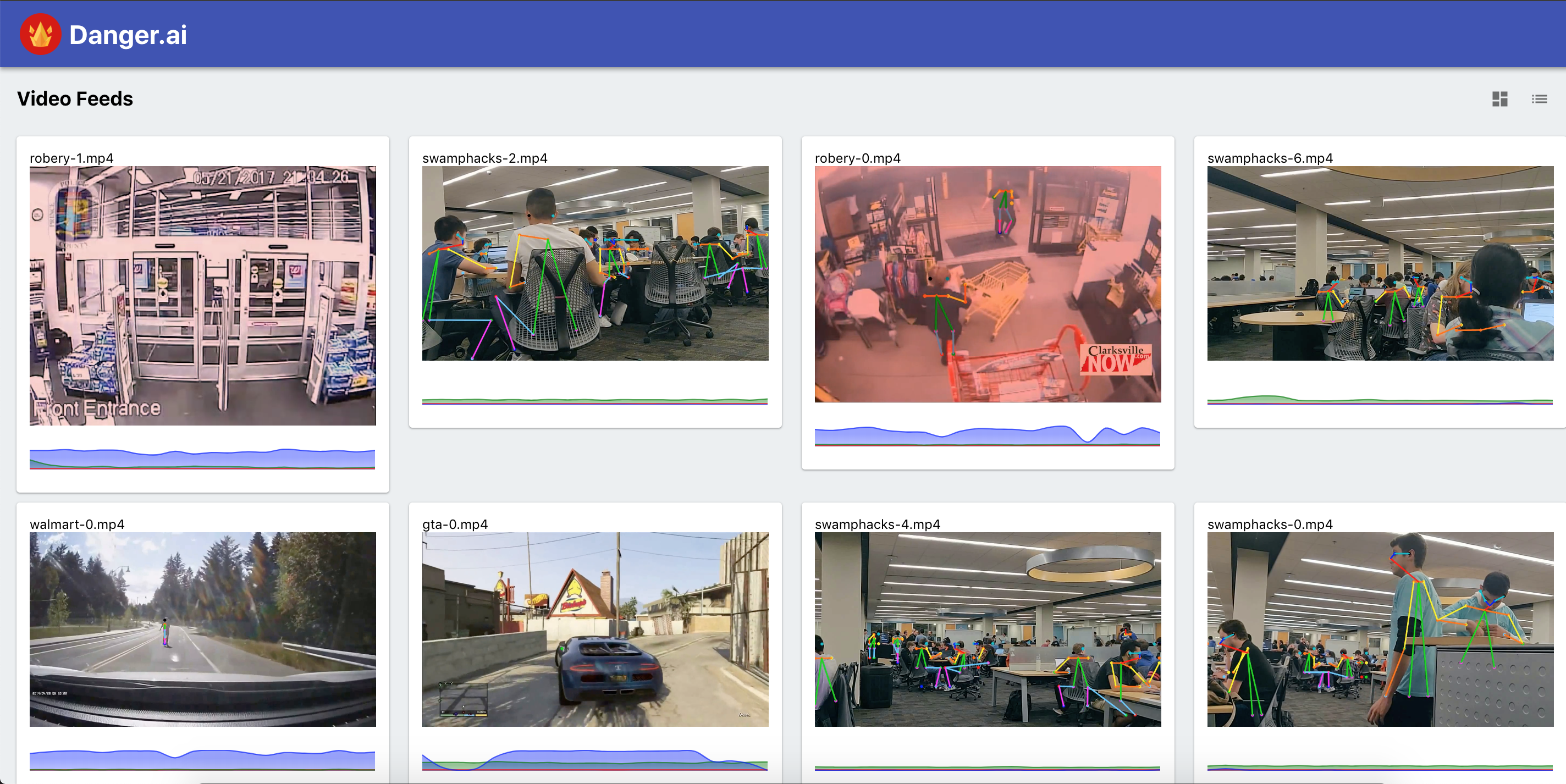
What it does
Uses a diverse set of machine learning technologies to detect danger in surveillance videos
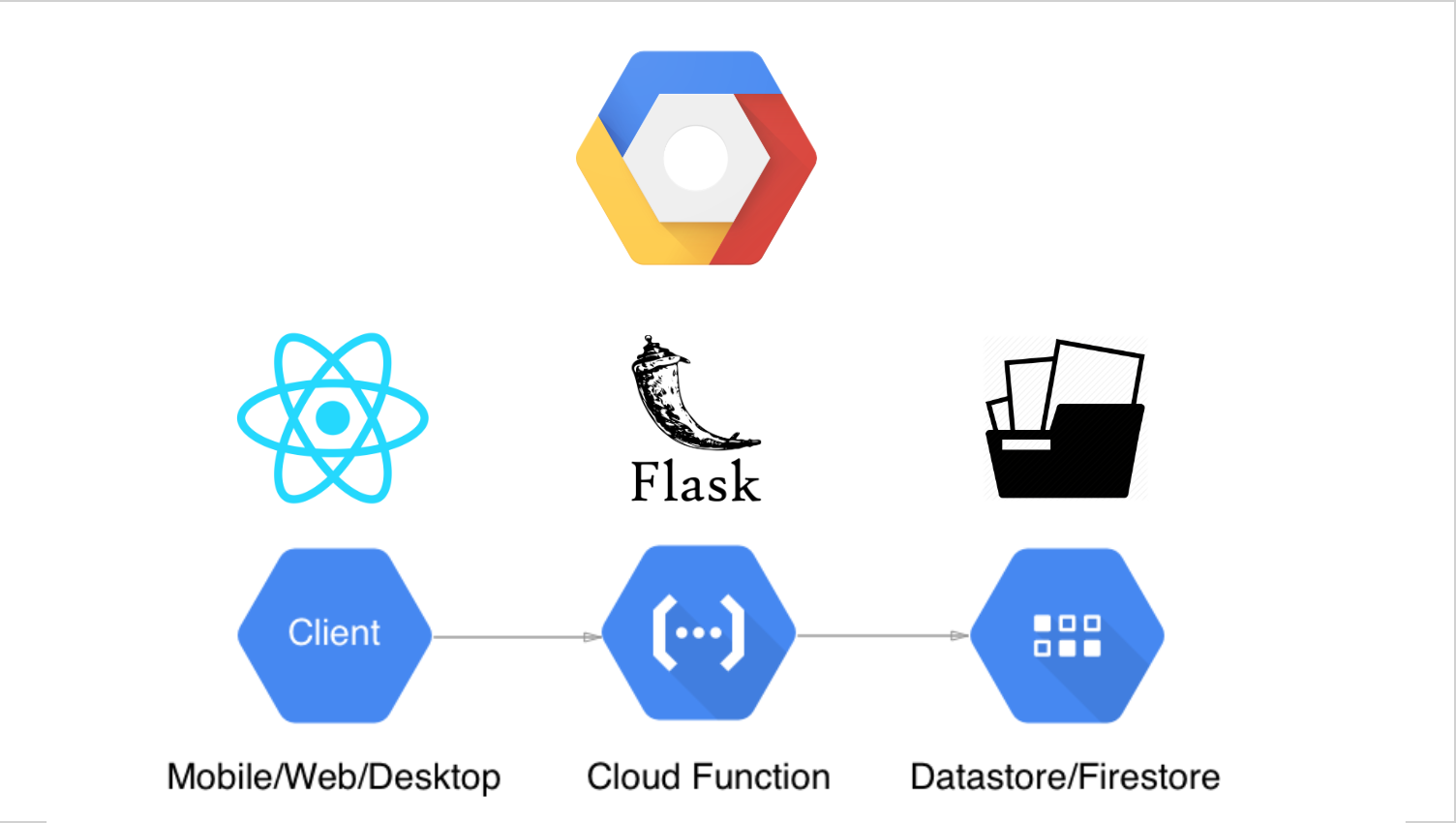
How we built it
GCP Storage
- Used a GCP Storage bucket to hold the processed video footage
GCP Cloud Firestore
- Used Cloud Firestore to save all of the danger score data that corresponded to the video footage in the GCP storage bucket
GCP Cloud Functions
- Used Cloud Functions to implement a serverless RESTful architecture to
- Save danger score data into Cloud Firestore
- Save processed video footage into GCP Storage
- Retrieve danger score data from Cloud Firestore
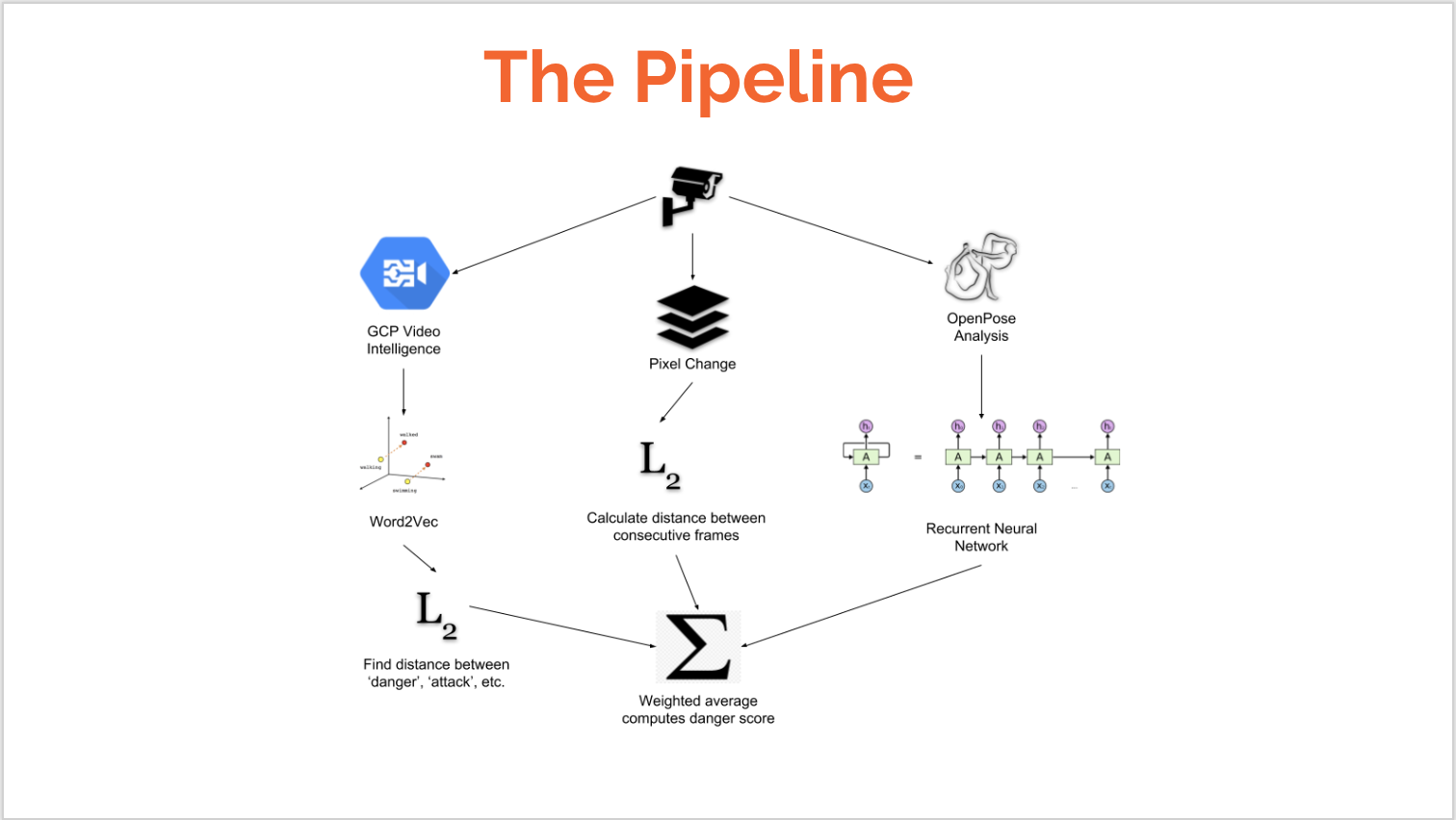
GCP Video Intelligence
- Used the GCP video intelligence API to detect objects throughout the video streams.
- The api enabled to us to track dangerous items like knives, guns, and other dangerous objects.
- The detected objects where then converted to vectors via Word2Vec.
Word2Vec
- Word2Vec takes a list of words and converts them to a 250-dimensional space.
- The general heuristic of this space is that words that are related to each other are closer together within the space.
- We take the words outputted by GCP Video Intel and using Word2Vec compare them to words related to danger.
Pixel Change
- The L1 norm was calculated to determine a difference score between every 2 consecutive frames of the video.
- Those values were then scaled to occupy the range from 0 to 1.
- This value was used as part of the final danger score.
RNN
- The RNN takes the positional data outputted by openPose
- It trains and learns based off of the positions of body parts of people in frame.
- 15 frames at a time were sampled and then predictions were based off of those 15 frames
OpenPose
- OpenPose is an open-source multi-person system to detect human body, hand, facial, and foot key points on images and video.
- It is a state of the art convolutional neural network.
- OpenPose was used to detect the positions of all humans in our set of videos
Challenges we ran into
- Manually labeling our ~13,000 frames of video
- Harnessing enough computing power to smoothly run videos through our pipeline
- Getting the cloud functions working to support our serverless API
Accomplishments that we're proud of
- Our RNN boasts a 94% accuracy rate.
- Successfully implemented a state of the art CNN for body tracking.
- Functional web app that appropriately displays the videos
- Dynamic charts to display danger scores to a user.
What we learned
- Google Cloud Platform APIs
- RNNs for time series data
- Data pipelining
- Full-stack web development
- AWS accelerated computing tools
What's next for Danger.ai
- Improve our pipeline and use more compute for live video analysis
- Collect more training examples
Built With
- deep-learning
- ensemble-learning
- flask
- google-cloud
- machine-learning
- openpose
- python
- react
- recurrent-neural-network
- serverless
- word2vec


Log in or sign up for Devpost to join the conversation.