-
-

Logo
-
Home
-
Enterprise grade Security
-
Demo Product
-
Dalil AI
-
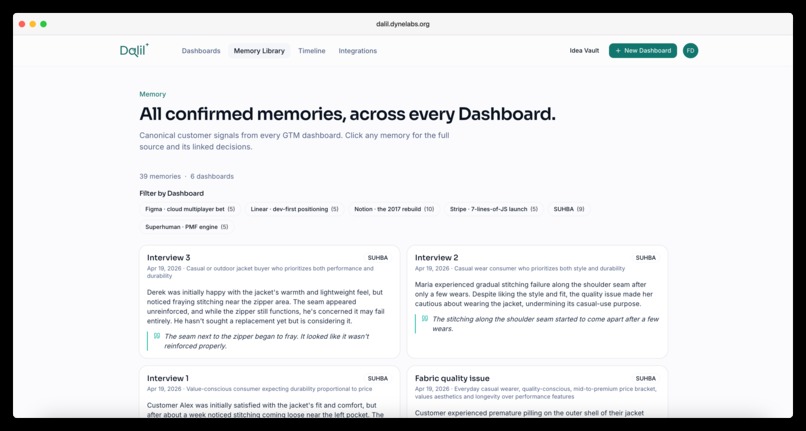
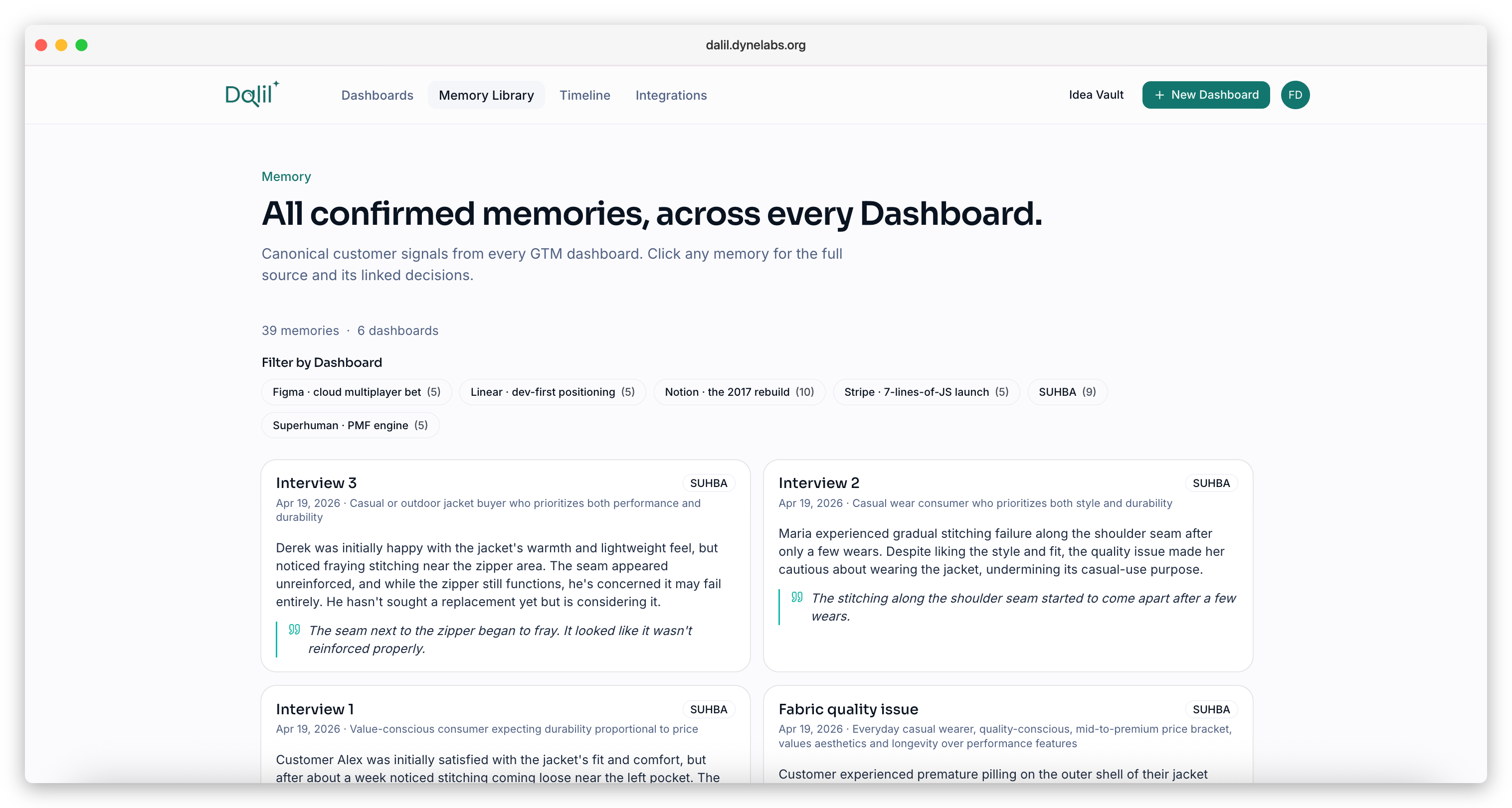
Memory Library
-
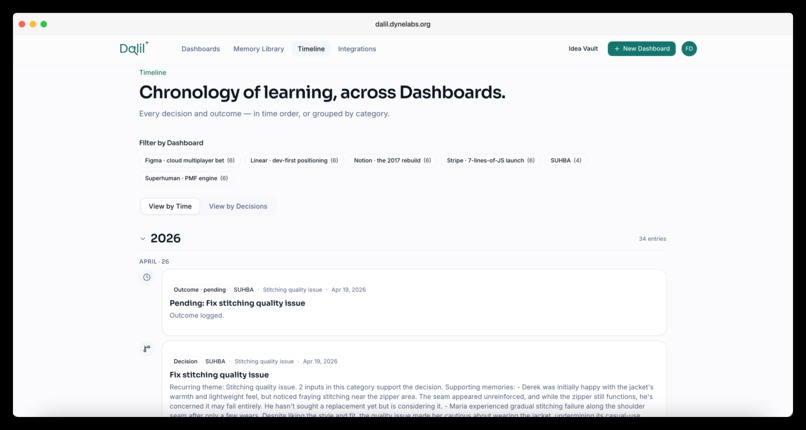
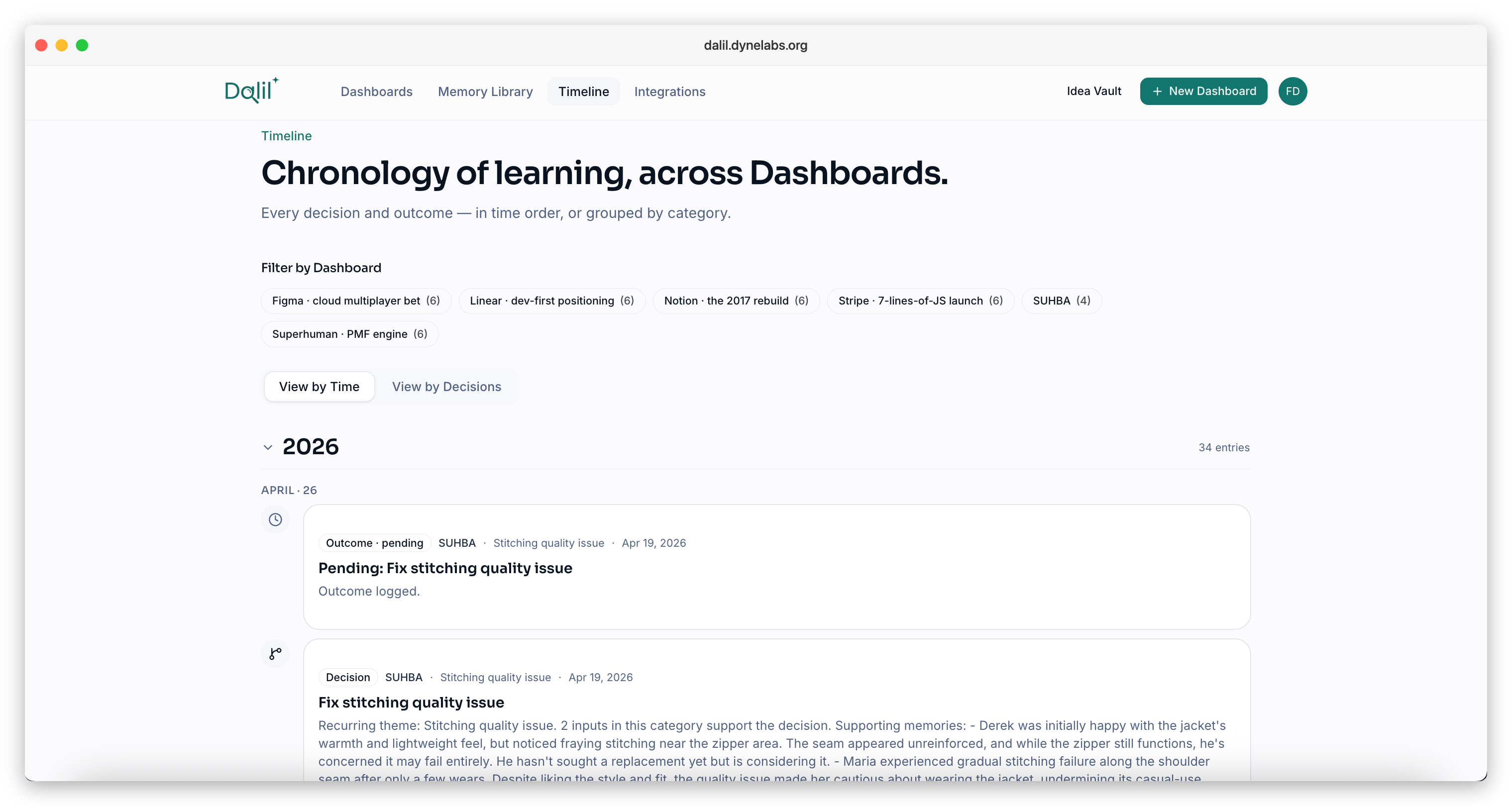
Timeline History

Inspiration
Every 0→1 team we've talked to has the same problem: the market keeps telling them things, and they keep forgetting. A customer call becomes a screenshot. A Slack thread becomes a memory. A board-deck decision becomes an unresolved "why did we bet on this?" six months later.
Inspired by Notion's 2017 rewrite, Superhuman's "40% very-disappointed" PMF engine, and Linear's engineer-first positioning — we kept noticing the same pattern: great products aren't built on better tools, they're built on better memory. The teams who won figured out how to close the loop between what the market said, what they decided because of it, and what actually happened.
We built Dalil because that loop shouldn't be a heroic feat of note-taking. It should be a product.
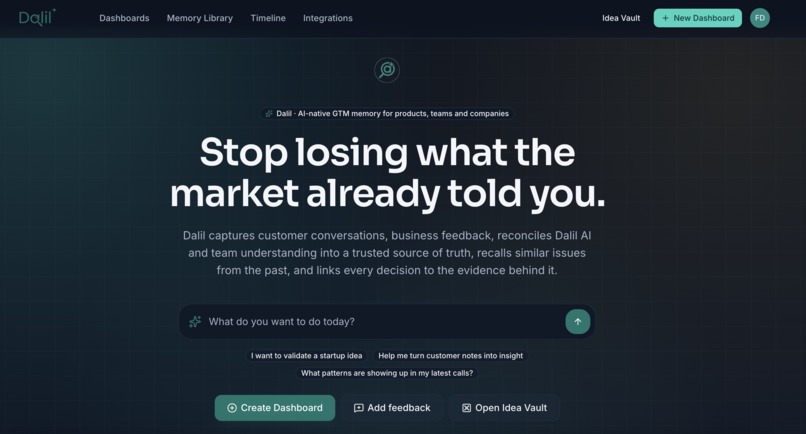
What it does
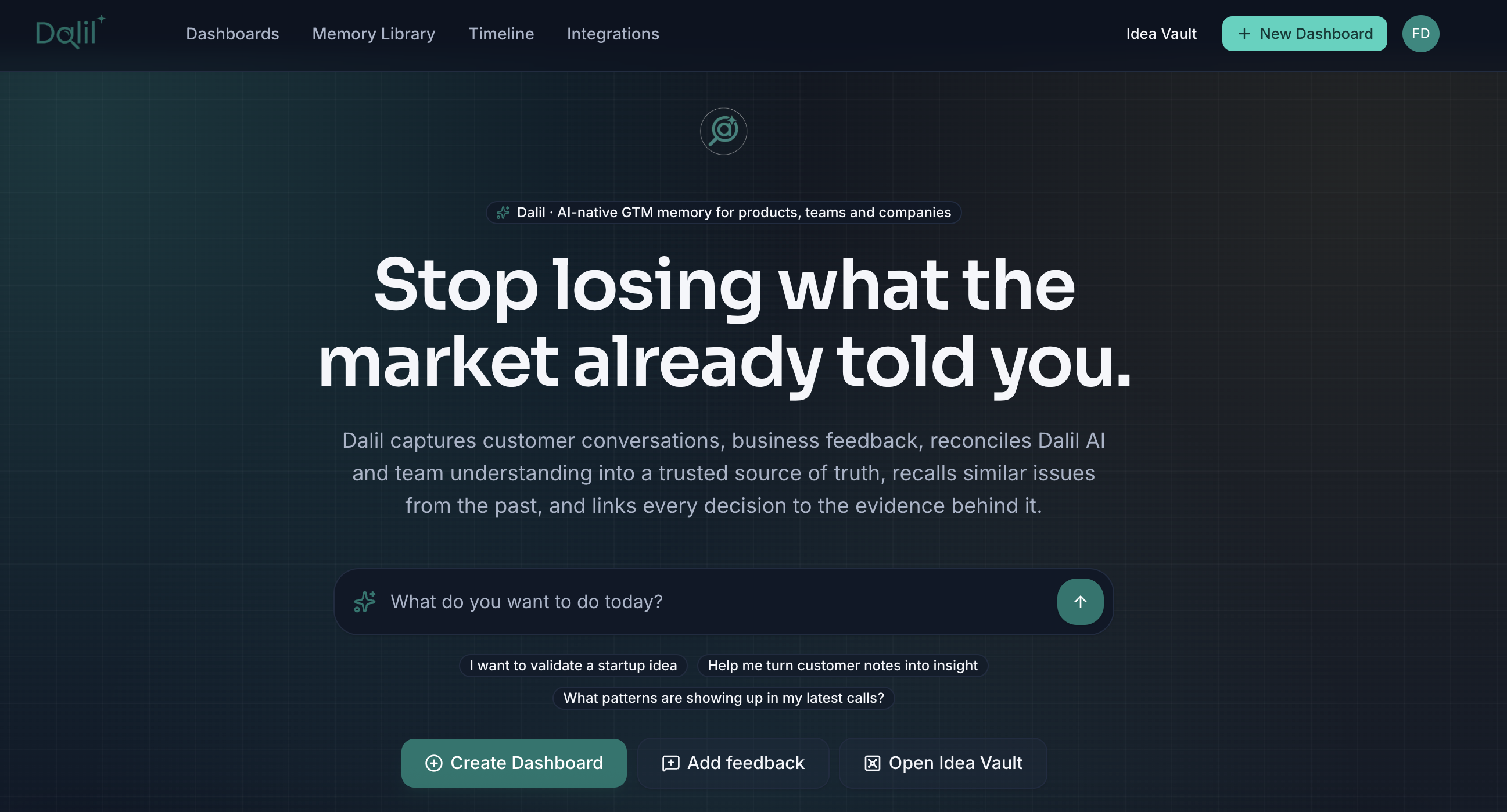
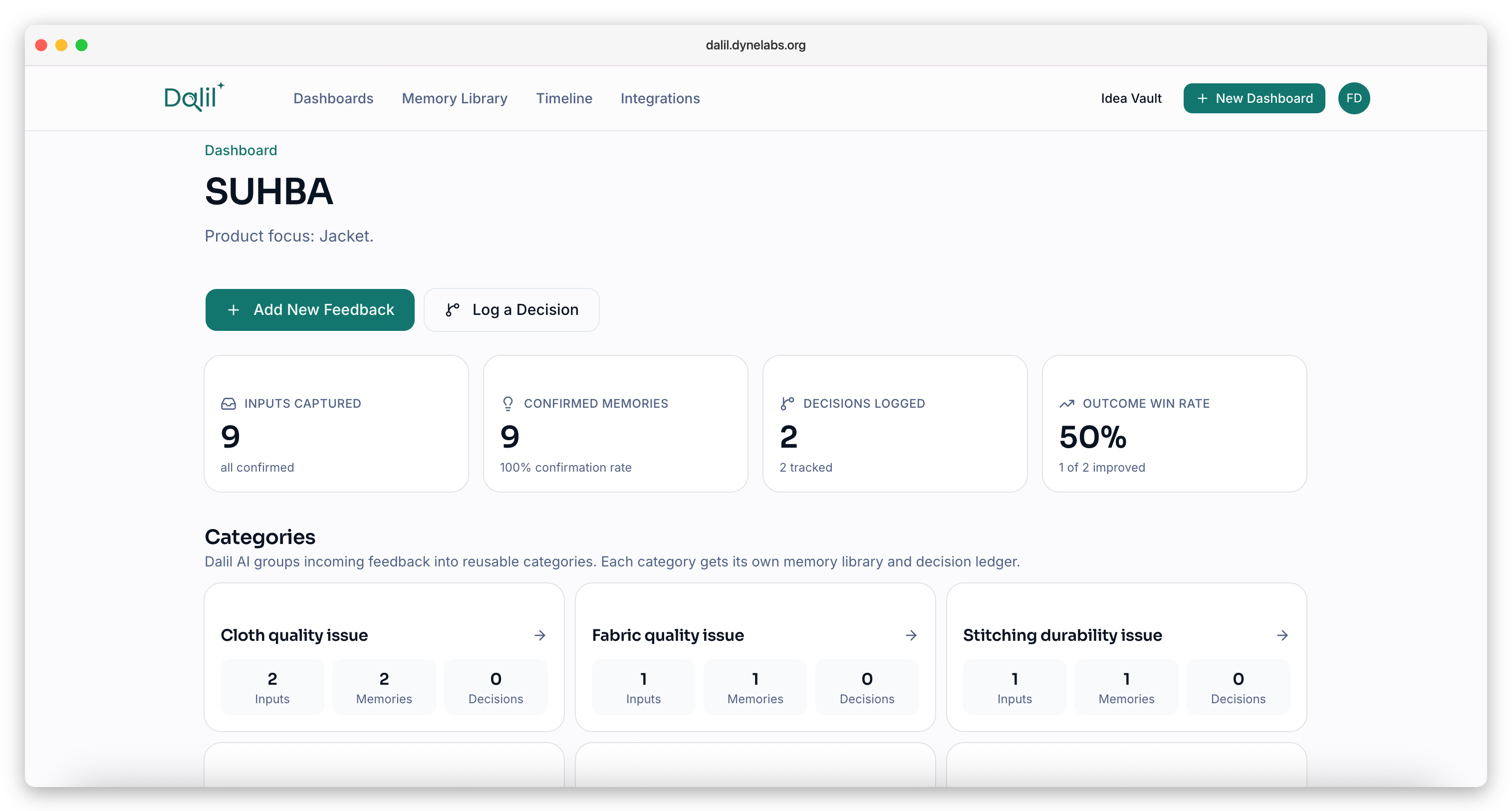
Dalil is an AI-native GTM memory and decision platform for products, teams, and companies — from solo founders to mid-sized teams running the 0→1 climb.
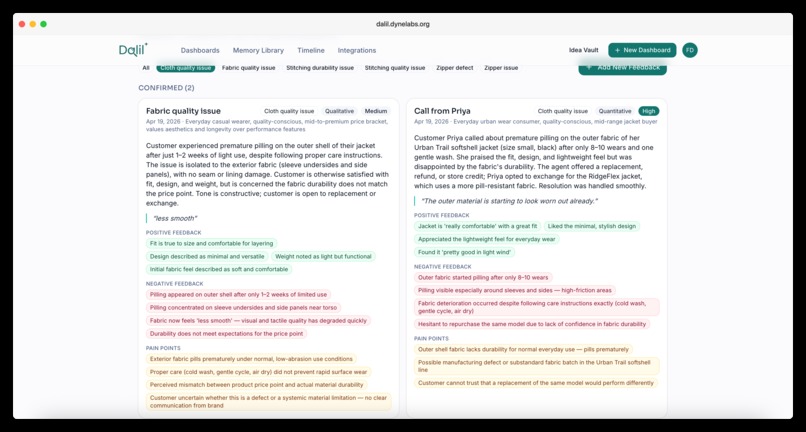
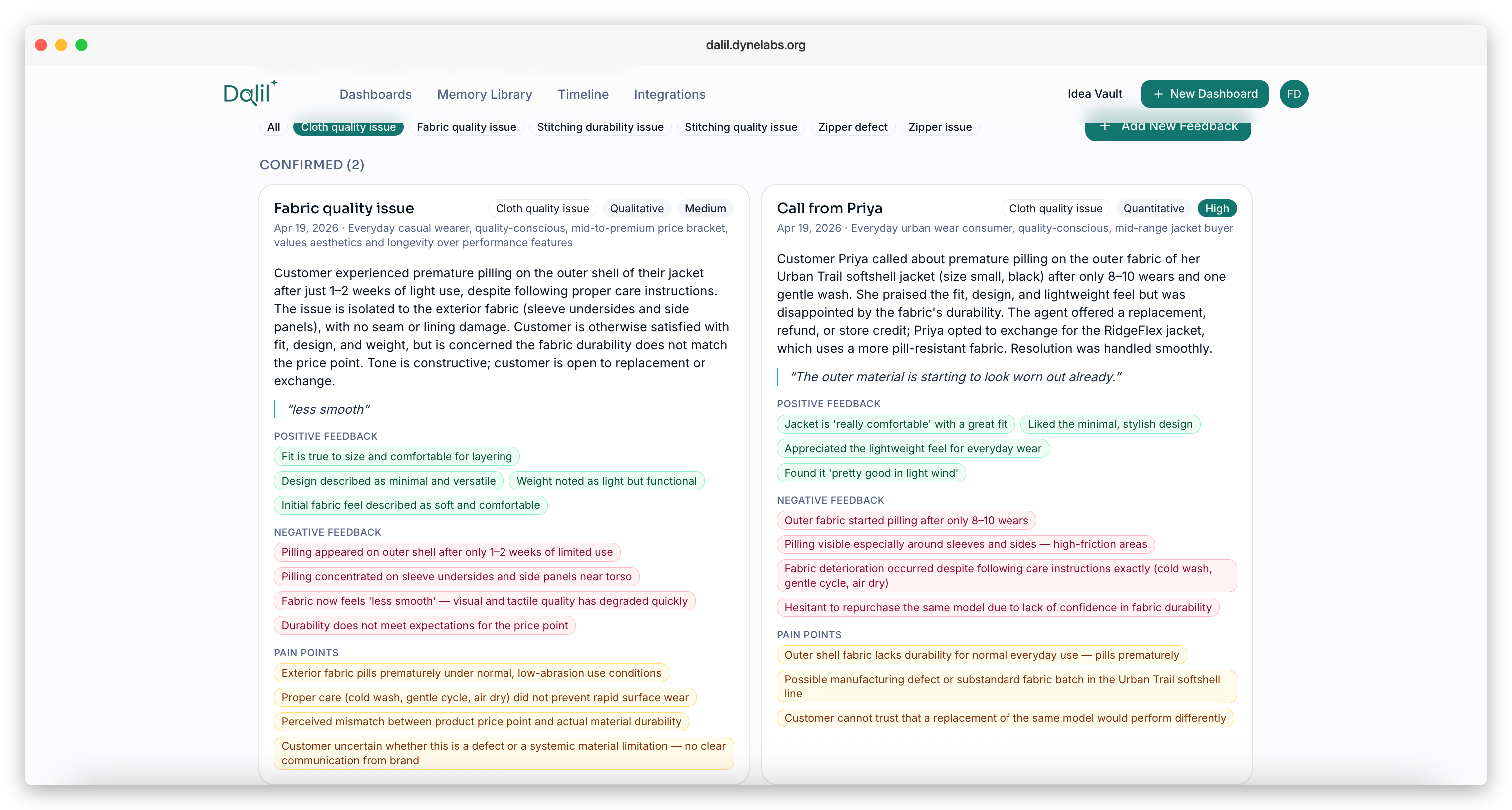
It captures messy customer feedback (call transcripts, DMs, surveys, support tickets, PDFs), turns it into structured canonical memory through Dalil AI extraction, groups it into reusable categories, surfaces recurring themes at the exact moment you're about to log a decision, and links every decision to the evidence behind it. When the real outcome lands, the learning loop closes.
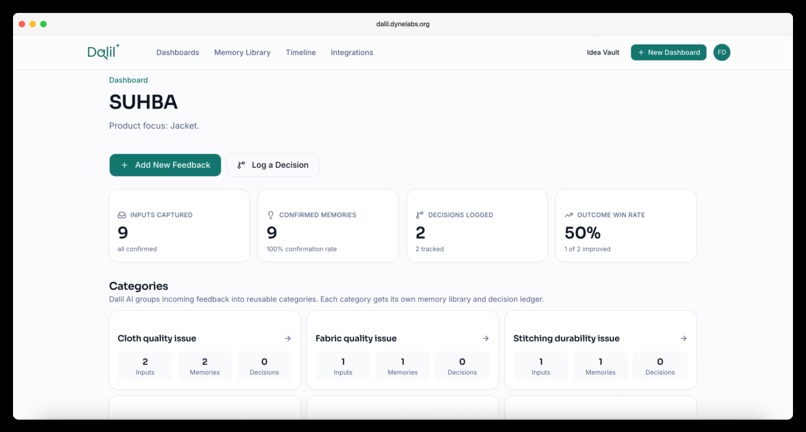
The demo walks through a real-world example — SUHBA, a modest-streetwear brand — where 11 pieces of feedback (IG DMs, QA audits, return-rate numbers) cluster into three categories (Zipper issue, Cloth quality, Stitching) and drive three evidence-backed V2 decisions with measurable expected outcomes. Dalil also ships five "what-if" workspaces based on real 0→1 moments — Notion's 2017 rebuild, Superhuman's PMF engine, Linear's dev-first bet, Stripe's 7-lines-JS launch, Figma's cloud multiplayer bet — so judges and users can explore what Dalil would have captured during those companies' own inflection points.
Key features:
- Consensus Capture. Dalil AI proposes an extraction; the team reviews and confirms. The final version is the canonical memory, never a raw AI summary.
- Similar-Issue Recall. When new feedback lands, Dalil surfaces semantically similar past memories — no vector database required.
- Decision Ledger. Log decisions with Recurring Theme auto-draft, linked evidence, and an embedded Dalil Assistant chat that refines the form in plain English ("make the expected outcome measurable").
- Timeline. Year-by-year product evolution via decisions and outcomes (the noise of individual inputs lives in the Memory Library instead).
- Stage-zero assistant. For pre-idea builders, a guided chat that sharpens audience, pain, and wedge.
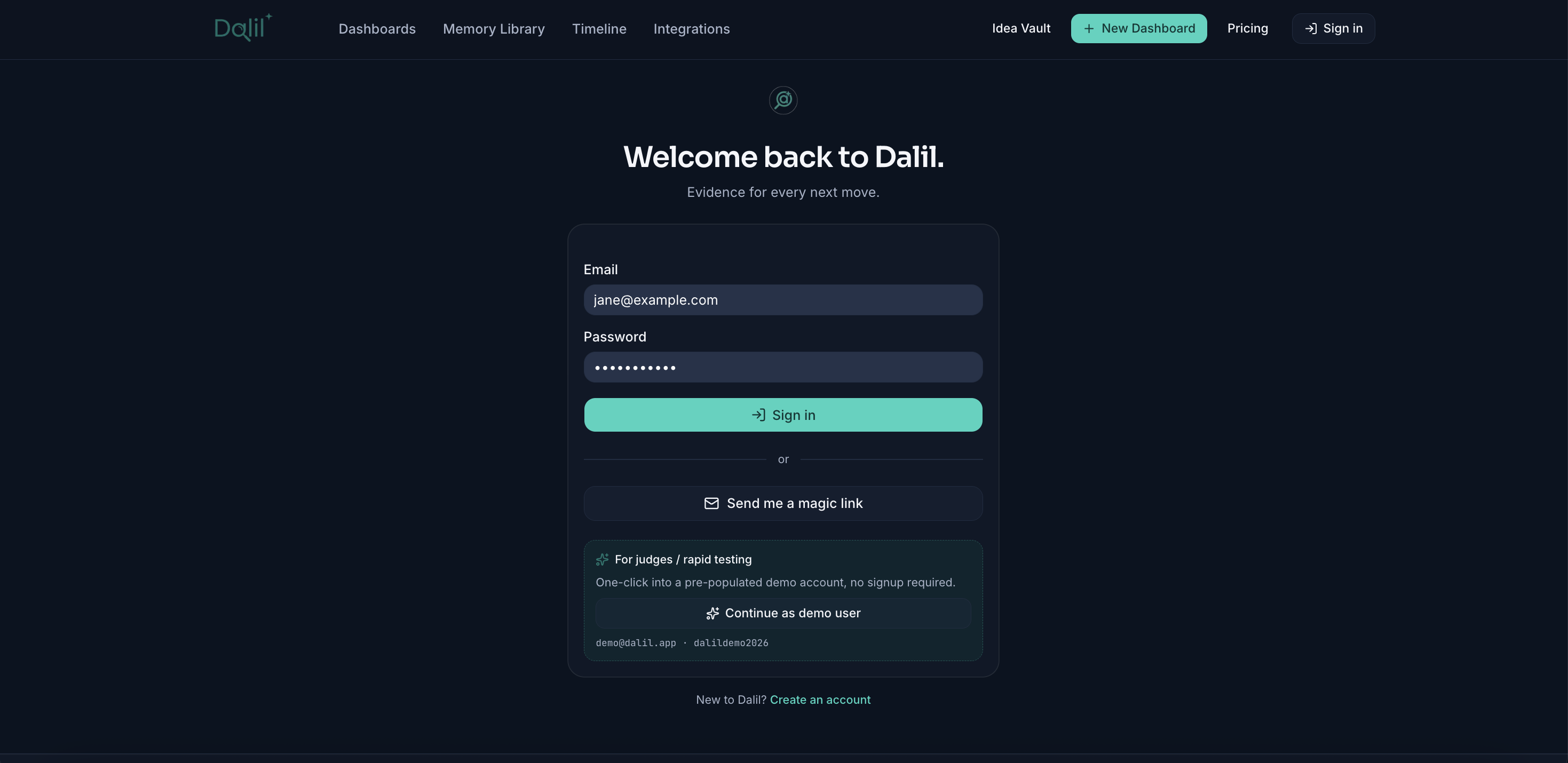
- Three real auth paths. Email + password, magic link, and a one-click demo login that self-provisions a pre-confirmed test user.
How we built it
- Stack. Next.js 16 (App Router) + TypeScript + Tailwind CSS v4 + shadcn/ui frontend; Supabase (Postgres + Auth + RLS) for data and identity; Anthropic Claude Sonnet 4.6 as the Dalil AI engine for extraction, rollup, and ranking; Stripe Checkout for the pricing page.
- AI pipeline. Every structured extraction runs through a Zod-schema-enforced wrapper around Claude. The wrapper is provider-agnostic — OpenAI and Gemini remain as fallbacks. PDF uploads flow through Anthropic's document content blocks so users can drop a file and get the same structured output. The stage-zero assistant streams via Anthropic SSE, parsed client-side into a typewriter reveal with full markdown rendering (bold, italic, lists, code, blockquotes).
- Similar-issue recall. We built this as a pure LLM ranker: at query time Claude reads the target memory and the candidate pool and returns top-N matches with calibrated similarity scores. No vector DB, no embeddings, no stale indexes.
- Auth. Supabase Auth with email + password, magic link (zero external provider setup), and a one-click demo login that admin-provisions
demo@dalil.appvia the service role — so judges and testers skip signup entirely. - Decision form with embedded assistant. Users pick a recurring theme to auto-draft, select evidence from the Memory Library, then type natural-language instructions into an embedded chat. Dalil Assistant returns a structured JSON diff that rehydrates the form in place.
- Data model.
workspaces → signals → signal_analyses → decisions → decision_evidence → outcomes, plusideasfor the stage-zero Idea Vault. Workspaces carry company-profile fields (audience, goal, preferred focus) captured during onboarding. Signals carry afeedback_type(qualitative | quantitative) and an AI-assignedcategorythat drives the Dashboard's category-box flow.
Challenges we ran into
- The embeddings rug-pull. Our first recall implementation used 1536-dim embeddings with pgvector. When we standardized on Claude for consistency and cost, we discovered Anthropic has no embeddings API — and our OpenAI key also wasn't working reliably. So we redesigned similar-issue recall around a pure LLM ranker mid-build. It ended up being better: simpler stack, no index to rebuild when a signal gets edited, and the recall quality is higher because Claude reasons about semantic overlap rather than geometric distance.
- Network blocked port 5432. The Supabase pooler was unreachable from our dev environment, so we couldn't use
psqlorsupabase db pushdirectly. We built a single "paste this into the SQL editor" flow: one SQL file that drops the public schema, reapplies every migration, and seeds the five real-world demo workspaces plus SUHBA. - Positioning mid-build. We started with "AI-native founder memory" and repositioned mid-sprint to "GTM memory for products, teams, and companies." That change rippled through the homepage, metadata, integrations copy, footer, and the API prompts. Doing that cleanly forced us to read every piece of user-facing copy we'd shipped.
- Dark mode that wasn't. Every
dark:utility was sprinkled through the codebase, but noThemeProviderwas mounted and the hero gradient was hardcoded in pure light mode. Toggling the theme changed nothing. Fixing it meant wiringnext-themesat the root, adding.darkoverrides for the gradient and grid background, and patching ~10 components with missing dark variants in a single sweep. - Scope discipline. Half of us wanted team invites, real-time collab, and a Chrome extension. We held the line: every feature had to visibly improve the before-and-after demo. The Chrome extension got mocked, team invites got cut, and the decision-form embedded assistant (which survived the cut) became the feature judges actually remember.
Accomplishments that we're proud of
- A product that demos itself. Open
/onboarding?template=suhba, walk the flow, and within 60 seconds you've seen messy IG DMs become a confirmed memory, clicked a recurring theme to auto-draft a decision, linked evidence, typed "make the expected outcome measurable" into the embedded assistant, and watched the form rewrite itself. - Five real-world demo workspaces (Notion, Superhuman, Linear, Stripe, Figma) so a judge can explore what Dalil would have captured during those companies' own 0→1 moments — instead of staring at generic personas.
- Similar-issue recall without a vector database. Cheaper to host, zero sync issues, and the ranker is smarter than cosine distance.
- Dalil Assistant embedded inside the decision form — natural-language refinements that mutate the form in place via structured JSON. The feature that survives the cut and the one that makes the product feel AI-native rather than AI-sprinkled.
- Three real auth paths with zero external provider config. Email + password, magic link, and a one-click demo login that self-provisions via the Supabase admin API.
- Polished SaaS surface end-to-end: dark mode, pricing page with Stripe Checkout, onboarding with progress + summary, typewriter-paced assistant replies with full markdown, a Recent Memories bento with a featured AI Insight card.
What we learned
- LLM-as-ranker beats embeddings for demos and early-stage apps. Simpler stack, fresher results, better semantic quality. Embeddings are the right answer at scale — they're the wrong answer when you're iterating and don't want to babysit an index.
- Real seed data is a feature. The five real-world workspaces landed harder than any UI polish. Judges understand "this is what Notion would have captured in 2017" faster than "this is what a fictional customer said at a fictional startup."
- Positioning language changes product scope. When we stopped saying "founder memory" and started saying "teams and companies," we immediately noticed places where the UX assumed a single user making every decision — and fixed them.
- Scope cuts save demos. Every feature we cut (team invites, real Chrome extension, full Slack OAuth) would have broken something in the golden path. What shipped holds together.
- Supabase middleware + server actions is the fastest path to real auth. No third-party provider required for a solid login experience.
- Claude Sonnet 4.6 is ridiculously good at structured extraction. We stopped needing two-pass validation once we tightened the system prompt.
What's next for Dalil
- Team features. Shared decisions, comments on evidence, @mentions, roles. The data model already supports
owneron every object; the UX is the next step. - Real integrations, not mocked. Slack (capture from a
#feedbackchannel via a bot), Shopify (pull reviews and refund reasons), Notion (read-only page ingest), Gong (call transcripts). That set covers ~80% of where actual GTM feedback lives. - The Weekly GTM Brief. Every Monday morning, Dalil emails you a one-page summary: top recurring themes, decisions logged, outcomes landed, one experiment to run next. The product does work for you, not the other way around.
- Browser extension. One keyboard shortcut from any webpage — a Twitter thread, a review, a support ticket — captures the highlight straight into the Memory Library.
- Organization analytics. Category-level trend lines, decision velocity, outcome win rates across Dashboards. For the leads who want to see the whole learning loop at a glance.
- Enterprise posture. SSO (Okta, Azure AD), audit logging, per-workspace RLS that isolates customer data, SOC 2 Type I within 6 months.
- Per-category dashboards. Each category already gets its own memory library and decision ledger — the next step is category-specific themes and a "compare across categories" view so teams can see which area of the product is churning the most decisions.




Log in or sign up for Devpost to join the conversation.