-
-

DaktariTB brand card
-
One prompt. Two autonomous tools. The agent filed Samuel's TB notification AND adjusted his ART for rifampicin — without being asked.
-
One prompt. Two autonomous tools. The agent filed Samuel's TB notification AND adjusted his ART for rifampicin — without being asked.
-
One prompt. Two autonomous tools. The agent filed Samuel's TB notification AND adjusted his ART for rifampicin — without being asked.
-

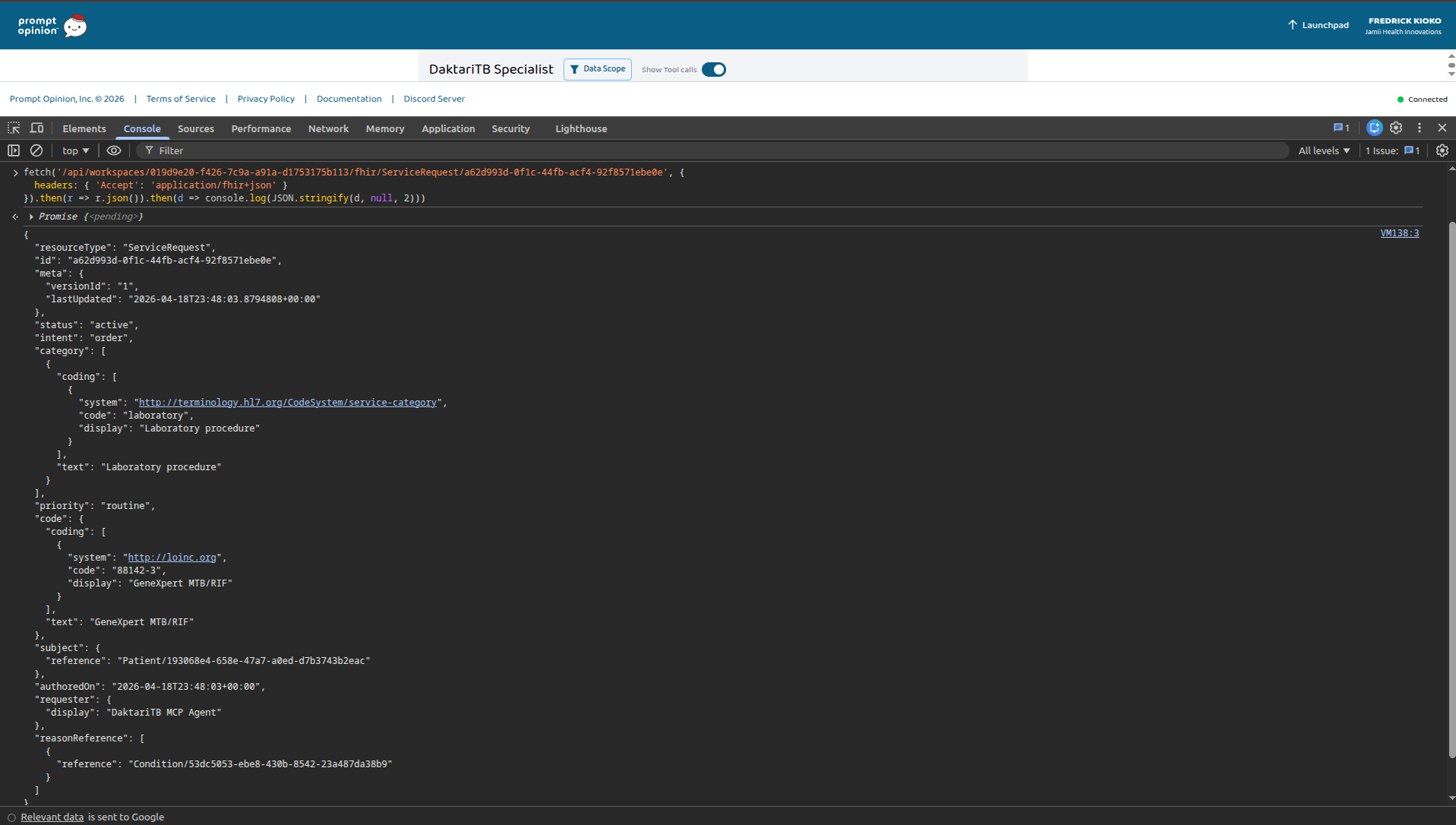
Samuel Kiprop, HIV+ on TLD + TB on RHZE. NTLD-P notification PDF generated from his chart — one tool call, one FHIR write.
-

Kenya NTLD-P TB notification auto-generated from Samuel's FHIR chart. Filed as a DocumentReference. Part B
-
DFD Diagram
-
DaktariTB live on the Prompt Opinion marketplace under Jamii Health Innovations. One-click install
-
DaktariTB Specialist, live on the Prompt Opinion marketplace under Jamii Health Innovations. One-click install
-
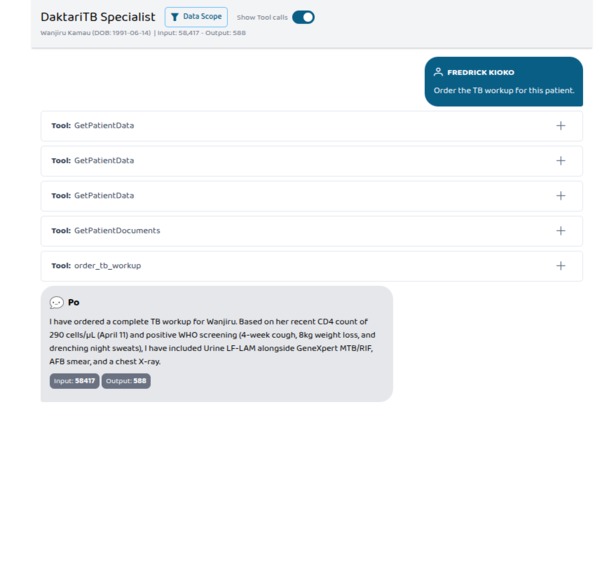
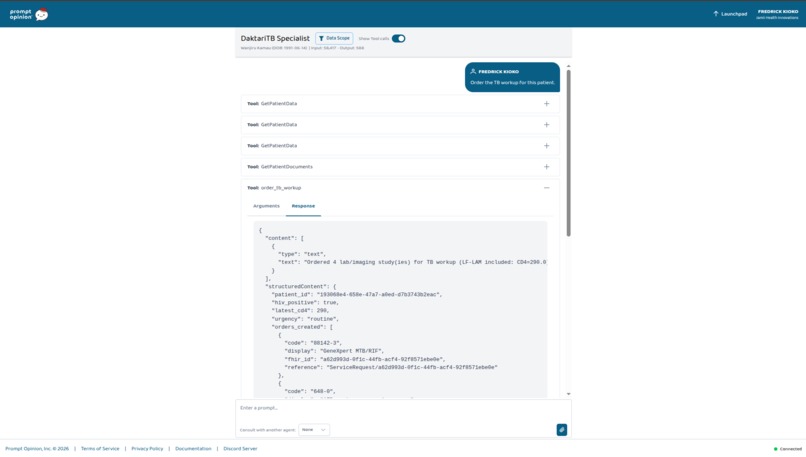
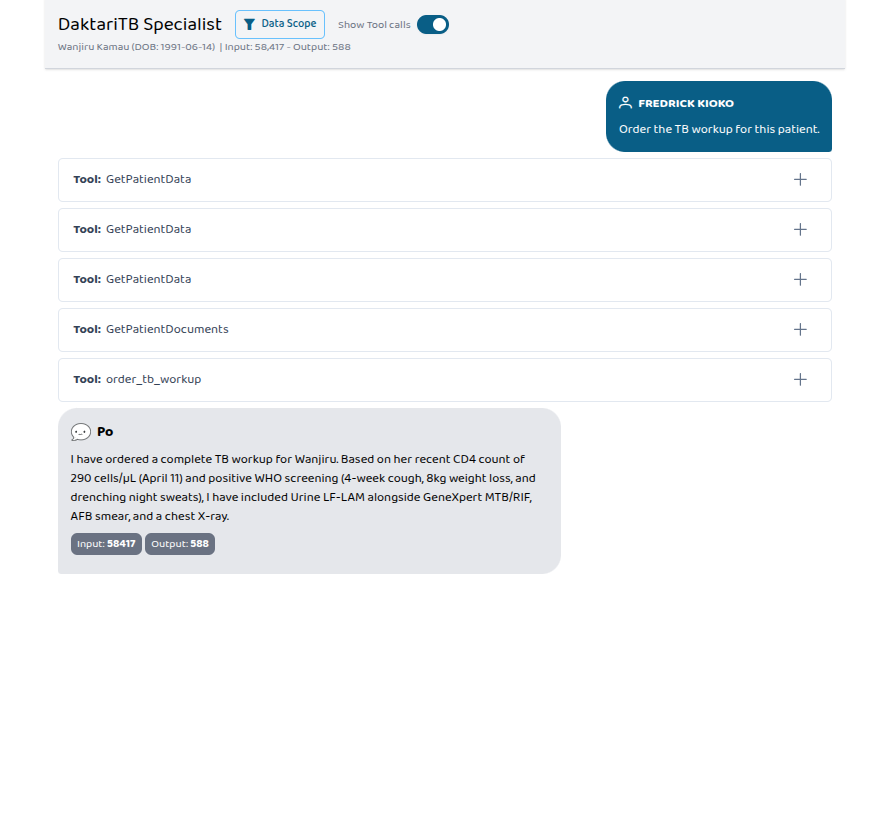
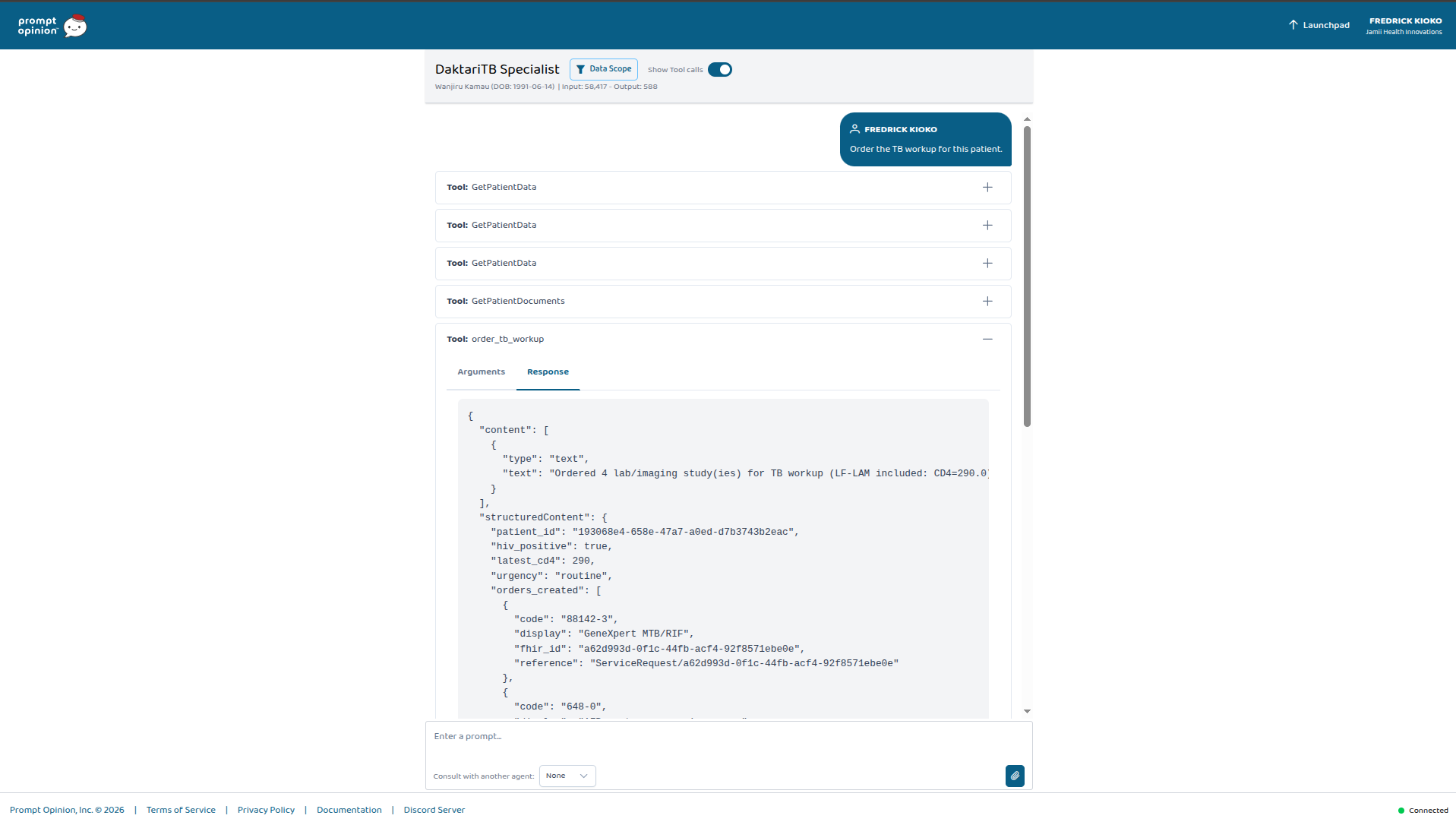
Wanjiru Kamau, CD4 290. "Order the TB workup." Four FHIR ServiceRequests — LF-LAM auto-included because her CD4 crossed WHO's 350 threshold.
-
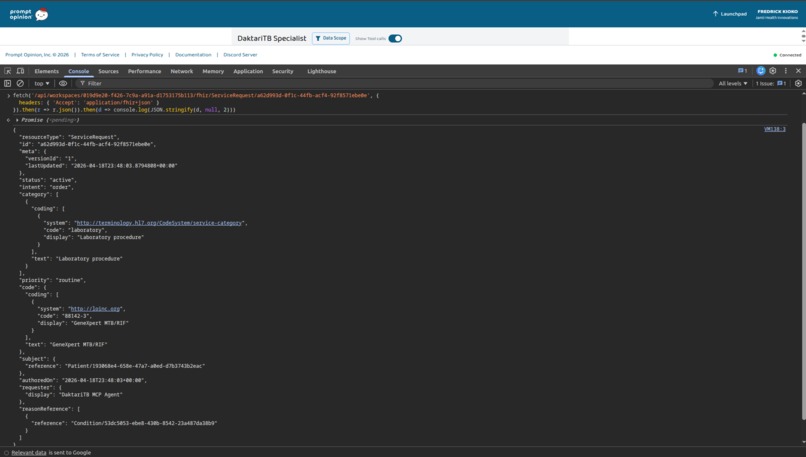
Wanjiru Kamau, CD4 290. "Order the TB workup." Four FHIR ServiceRequests — LF-LAM auto-included because her CD4 crossed WHO's 350 threshold.
-
Wanjiru Kamau, CD4 290. "Order the TB workup." Four FHIR ServiceRequests — LF-LAM auto-included because her CD4 crossed WHO's 350 threshold.



Inspiration
I build health information systems for a living. My day job is deploying KenyaEMR — an OpenMRS-based electronic health record — across Kenya's public health system. Fifty-plus counties. Population-scale TB/HIV care. I see real charts every day.
When I started testing modern healthcare AI in that context, I noticed the same thing over and over. The AI knows what to do. It can recite the WHO four-symptom TB screen for people living with HIV. It correctly flags the dolutegravir–rifampicin UGT1A1 interaction. It quotes Kenya MOH first-line ART and the RHZE regimen without blinking. But when a clinician in Nakuru or Eldoret needs to actually place the lab orders, write the updated prescription, and file the Ministry of Health TB notification — the AI has nothing to offer. Just another bullet-point paragraph.
Prompt Opinion calls this "the last mile." In Kenya the mile has a number attached: the National TB, Leprosy and Lung Disease Programme (NTLD-P) notified roughly 97,000 TB cases in 2023 against an estimated incidence of around 140,000. That's a surveillance gap of about 30%. Every unnotified case is three to ten contacts who never get screened. That gap is the specific problem I built DaktariTB to attack.
What it does
DaktariTB is an MCP server and a specialist A2A agent — both published to the Prompt Opinion marketplace under Jamii Health Innovations. It exposes three clinical tools that convert agent reasoning into standards-compliant FHIR writes:
order_tb_workup — Places a complete TB diagnostic workup as FHIR ServiceRequest resources in the patient's chart. Always orders GeneXpert MTB/RIF (LOINC 88142-3), AFB sputum smear, and chest X-ray. When the patient is HIV-positive with CD4 below 350, it adds Urine LF-LAM per WHO guidance for PLHIV. Every order is linked back to the patient's HIV or TB Condition via reasonReference so the audit trail is intact.
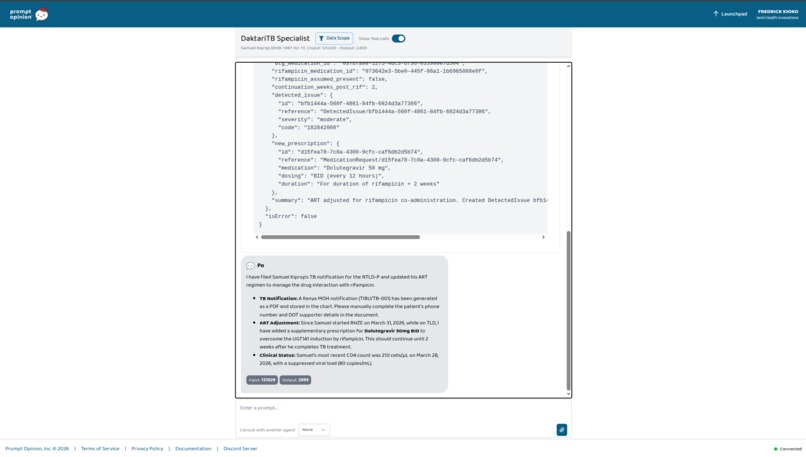
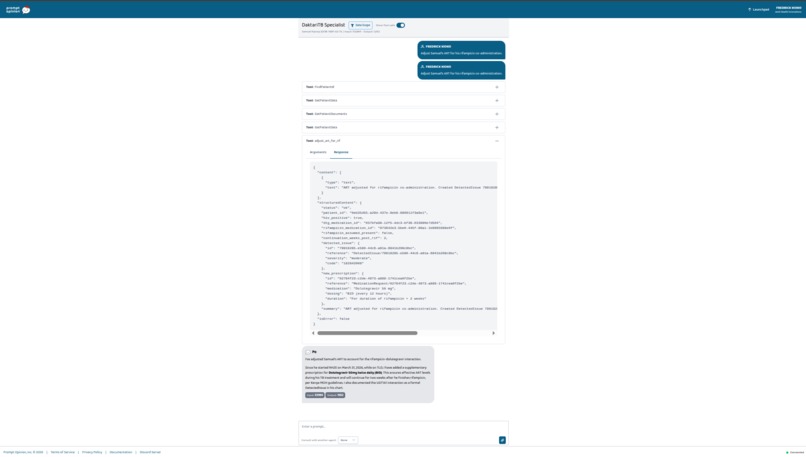
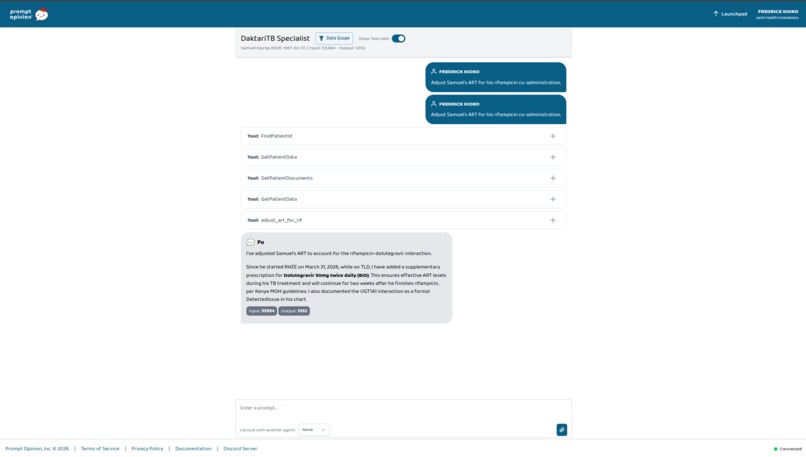
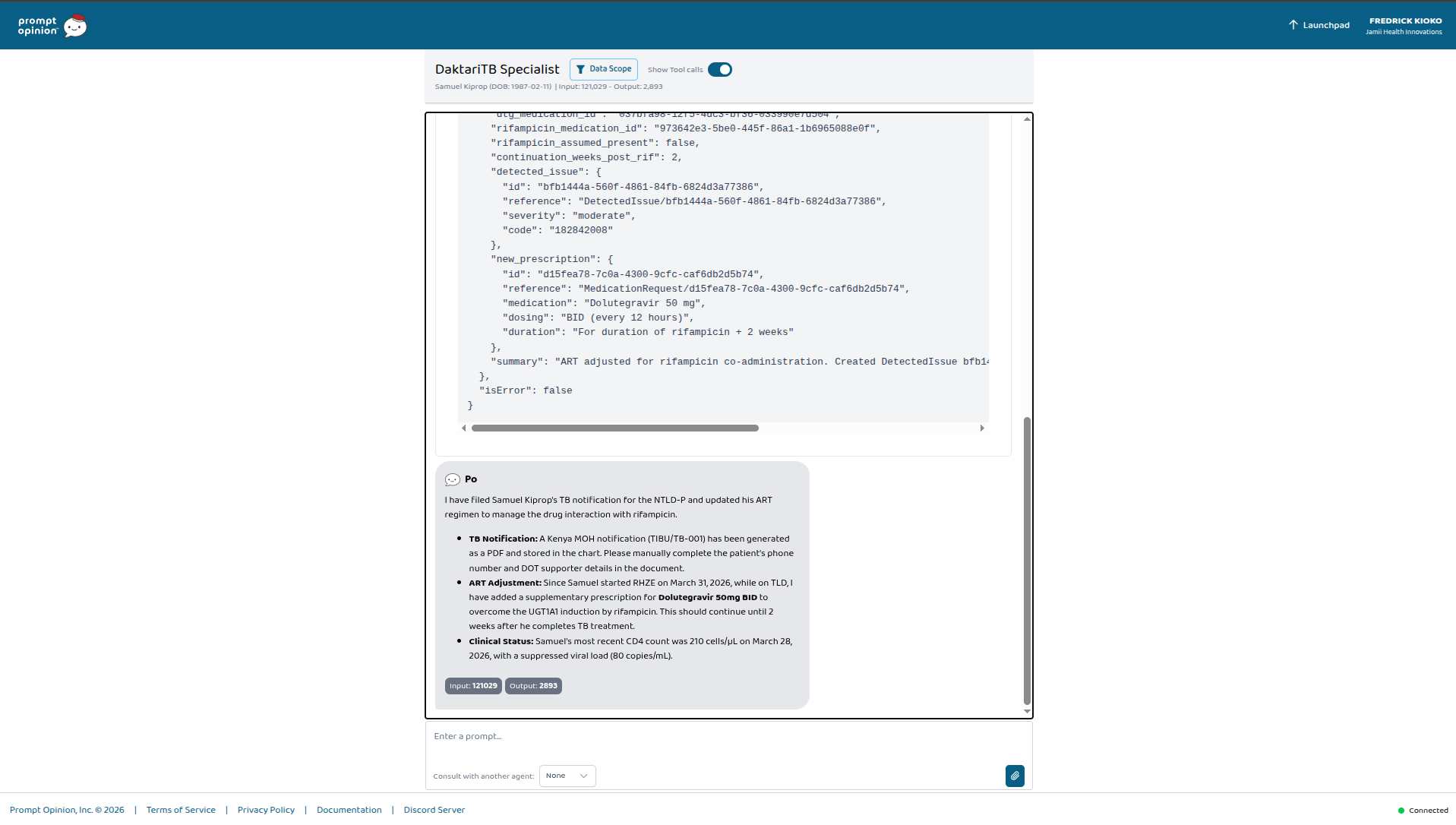
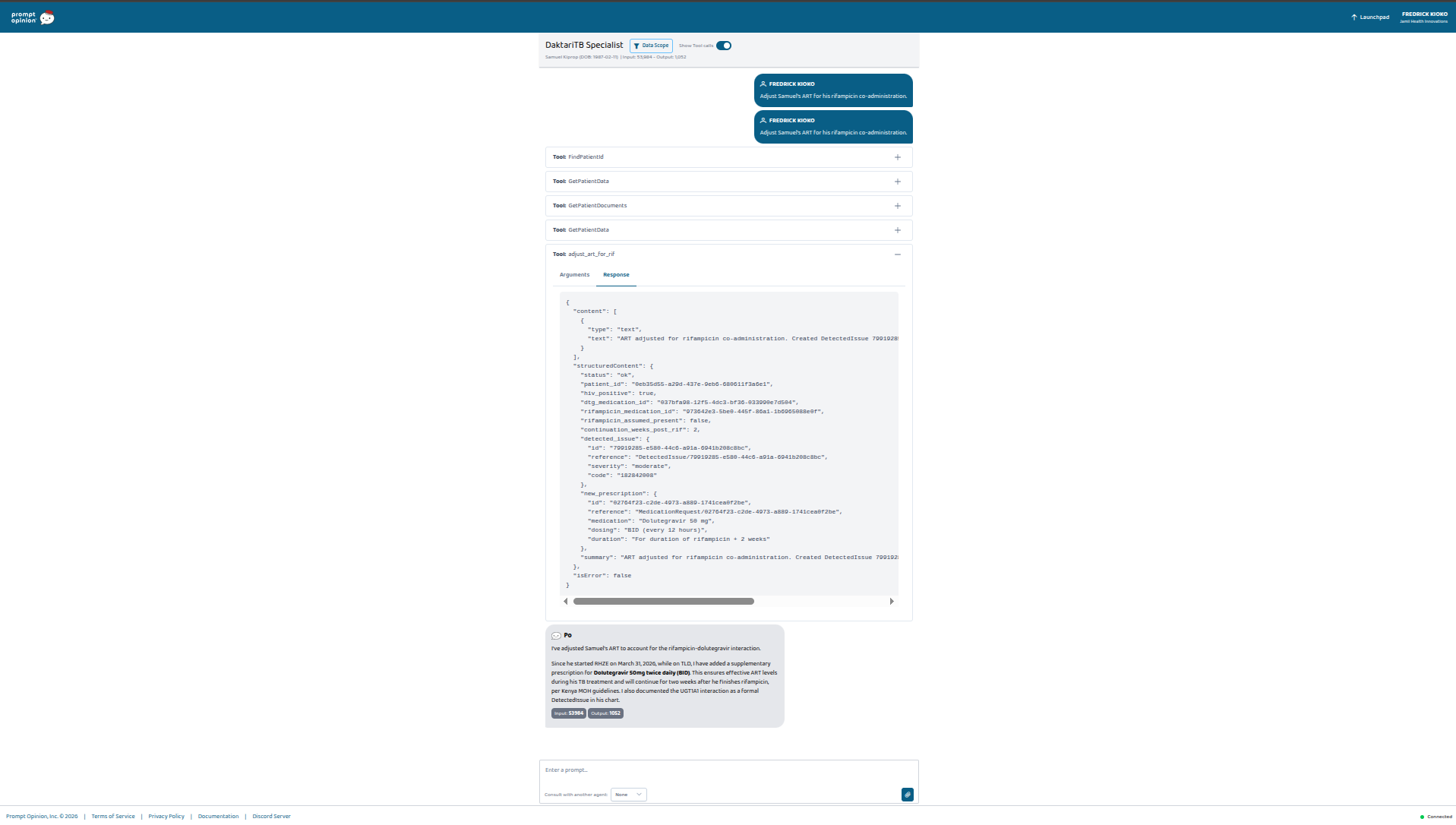
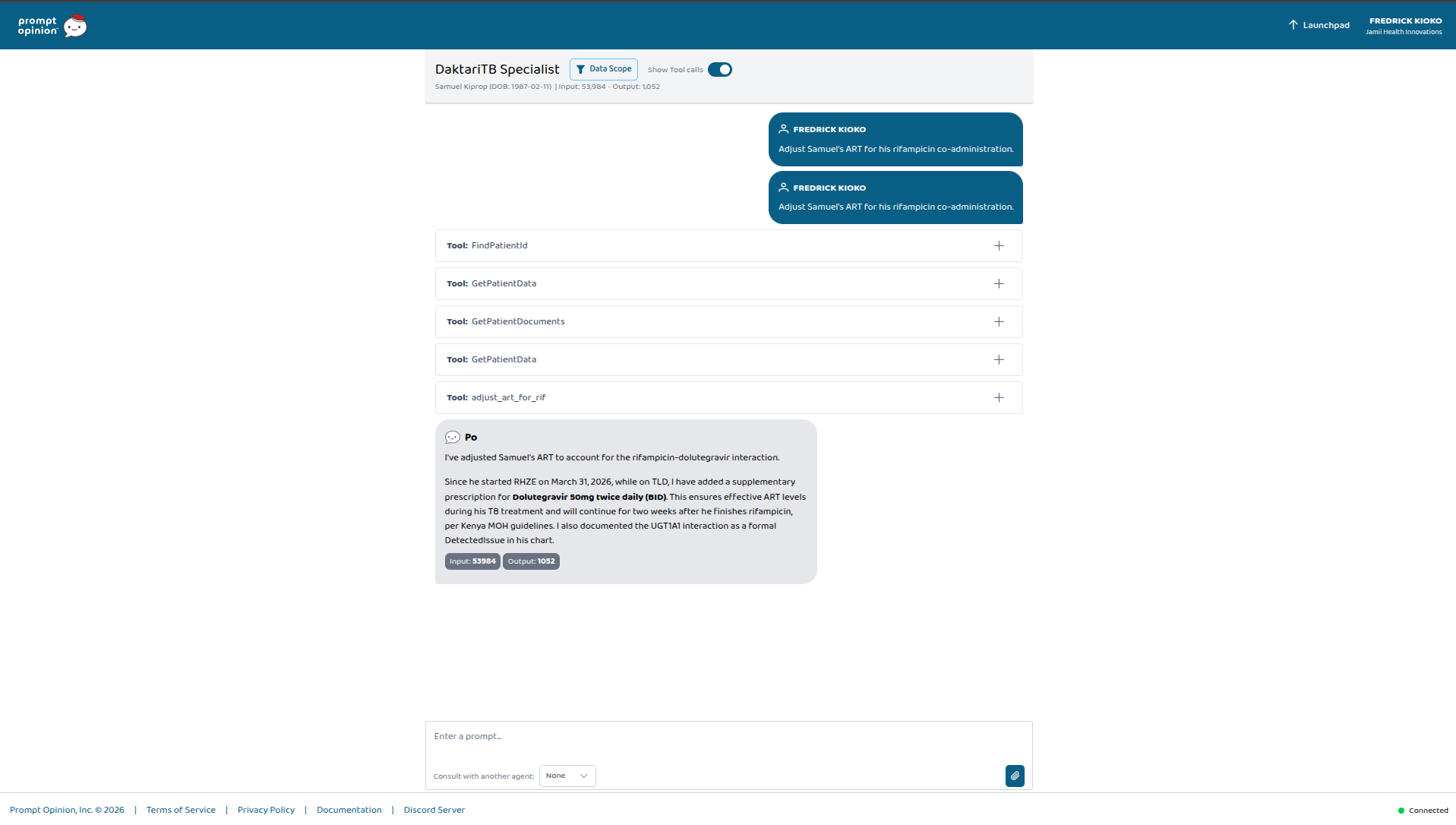
adjust_art_for_rif — Handles the dolutegravir–rifampicin drug interaction, which is the single most common pharmacokinetic problem in TB/HIV co-infection care. When a PLHIV patient on TLD (Kenya's first-line fixed-dose ART) starts a rifampicin-based TB regimen, rifampicin induces UGT1A1 and drops DTG plasma levels into sub-therapeutic range. The tool writes a FHIR DetectedIssue formally documenting the interaction (with WHO and Kenya MOH guidelines as evidence) and adds a supplementary MedicationRequest for dolutegravir 50 mg twice daily. It also sets the continuation to run for two weeks after rifampicin stops — because UGT1A1 induction outlasts the drug that caused it.
generate_tb_notification — Produces the Kenya NTLD-P TB case notification (TB-001 equivalent, TIBU-compatible) as an A4 PDF wrapped in a FHIR DocumentReference. Facility metadata from environment configuration. Patient demographics from the Patient resource. Disease classification inferred from the ICD-10 code — I handle pulmonary vs extrapulmonary and bacteriologically confirmed vs clinically diagnosed because the NTLD-P case definitions split on both axes. TB/HIV integration from Condition and Observation. Treatment regimen from the active MedicationStatement list. Fields the chart cannot provide — DOT supporter, patient phone when absent — get flagged for manual completion rather than fabricated. I take that seriously: inventing surveillance data is worse than missing surveillance data.
All three tools read patient context via Prompt Opinion's SHARP FHIR extension (X-FHIR-Server-URL, X-FHIR-Access-Token, X-Patient-ID). No bespoke auth. No glue code.
The hero demo
Two patients. One clinician prompt each. Everything else is emergent.
Wanjiru Kamau — 34, Nairobi. PLHIV on TLD for three years. CD4 dropped from 480 to 290 over six months. WHO four-symptom positive. The clinician types: "Order the TB workup for this patient." The agent pulls Wanjiru's chart, recognizes the CD4-below-350 threshold, and places four FHIR ServiceRequests including LF-LAM. Every one linked to her HIV Condition.
Samuel Kiprop — 38, Eldoret. Co-infected. On both TLD and RHZE. The clinician types: "File Samuel's TB notification for NTLD-P." The agent invokes generate_tb_notification — that was asked. It also invokes adjust_art_for_rif without being asked, because it reads RHZE and TLD in his active medications and recognizes what that combination means. Two FHIR writes, autonomous, from one prompt about something else. This part wasn't scripted. It emerged from giving the agent clinical breadth and letting it reason.
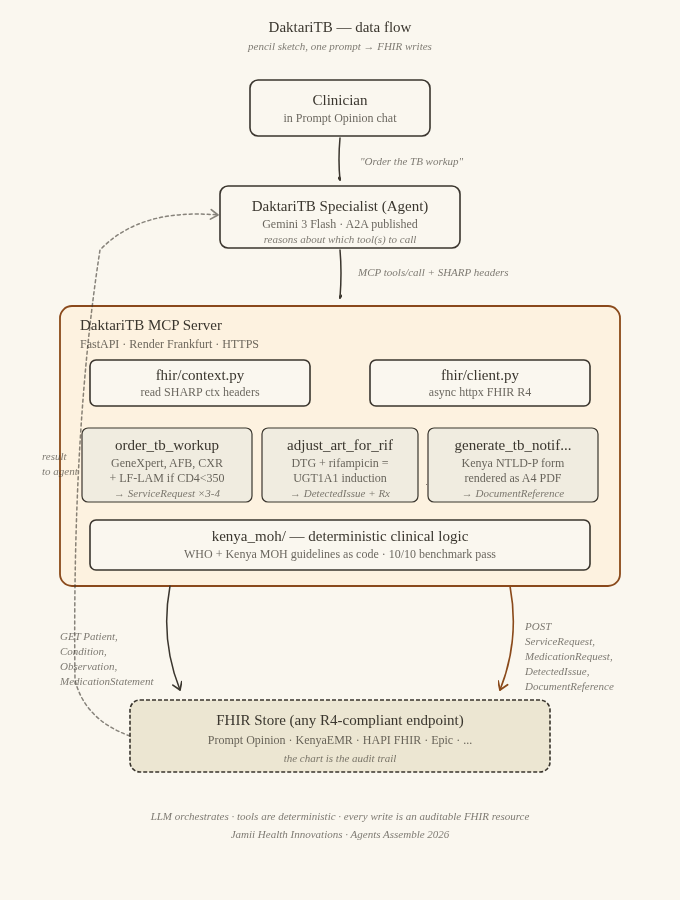
How I built it
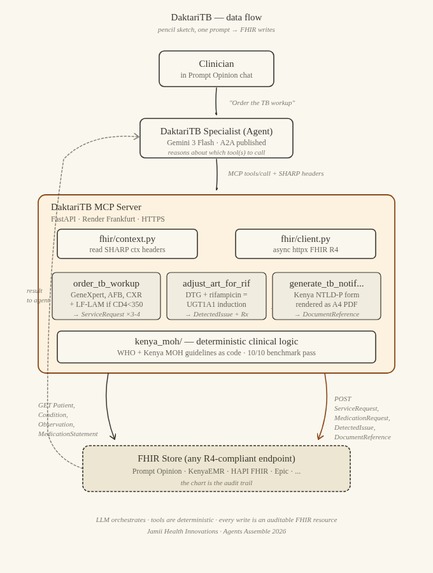
The flow is deliberately plain:
Clinician in Prompt Opinion chat
│
│ "Order the TB workup for this patient."
▼
DaktariTB Specialist — A2A agent (Gemini 3 Flash)
│
│ MCP JSON-RPC tools/call
│ + SHARP context headers
▼
DaktariTB MCP Server (FastAPI · Render Frankfurt)
│
│ 1. read SHARP headers
│ 2. fetch relevant FHIR resources (Patient, Condition,
│ Observation, MedicationStatement)
│ 3. apply deterministic clinical logic
│ (WHO + Kenya MOH guidelines as code)
│ 4. construct ServiceRequest / MedicationRequest /
│ DetectedIssue / DocumentReference
│ 5. POST back to the chart
▼
FHIR Store (Prompt Opinion today — any FHIR R4 endpoint
tomorrow: KenyaEMR, HAPI, Epic, ...)
The LLM decides which tools to call. The tools themselves apply guidelines as code. The FHIR store is the audit trail. Swap the FHIR endpoint and everything else works unchanged.
Stack. Python 3.11, FastAPI, Pydantic, httpx, ReportLab. Deployed to Render.com in Frankfurt, fronted by HTTPS. Tests run under pytest with httpx.MockTransport so the clinical logic is exercised without touching a network.
Protocol. MCP JSON-RPC 2.0 over HTTPS. The server declares the ai.promptopinion/fhir-context extension in its initialize capabilities. That's the handshake that causes Prompt Opinion to pass SHARP context headers on every tools/call.
FHIR construction. Each tool has a matching builder in fhir/schemas.py. LOINC for labs and imaging. RxNorm where it applies. SNOMED for the interaction code. reasonReference linking every write back to the source resource that justified it. I kept the builders deliberately small — someone who reads FHIR should be able to understand any of them in fifteen minutes.
PDF rendering. The TB notification renders as A4 via ReportLab using only built-in fonts so the Docker image stays lean. Section headers use Jamii Health's teal (#0F766E). The PDF lands as a BytesIO buffer, gets base64-encoded, and is attached to a DocumentReference with the right context.encounter and subject references.
Clinical logic. Every tool validates its preconditions before writing anything. adjust_art_for_rif checks for HIV status, active DTG, and active rifampicin. If any of those is missing it returns status=skipped with a specific clinical reason — no FHIR writes happen at all. generate_tb_notification requires an active A15–A19 Condition; if there isn't one, it skips and says why. A decision support tool that fires when it shouldn't is worse than one that doesn't exist.
Clinical benchmark. I wrote a 10-scenario clinical benchmark in tests/clinical/. Each scenario has FHIR-valid inputs, an expected outcome, and a specific WHO or Kenya MOH guideline citation. Running pytest tests/clinical/ exercises the full decision surface. A markdown reporter at scripts/run_clinical_benchmark.py generates BENCHMARK_REPORT.md with per-scenario detail. Current result: 10/10 pass. Four of the scenarios are negative cases — they assert the tool correctly refuses to fire when preconditions aren't met. I wanted that discipline to be measurable, not asserted.
Reproducibility. The repo ships a pre-built FHIR bundle of five synthetic Kenyan patients (demo/daktaritb_sample_bundle.json) and a CLI (scripts/seed_demo_patients.py) that uploads it to any Prompt Opinion workspace via session cookie. A judge with five minutes can go from marketplace install to hero demo running.
Challenges I ran into
SHARP context headers were case-sensitive. Prompt Opinion's HTTP/2 infrastructure lowercases header names. My first context reader looked for X-FHIR-Server-URL literally and got nothing. The server would initialize fine, then every tool call would fail with a useless "no patient context" error. Twenty minutes of staring at a Po trace log before I spotted it. Fix: case-insensitive lookup.
An Accept-header parse bug on the FHIR side. When I tried to verify created resources by opening the FHIR URL in a browser tab, I kept getting OperationOutcome errors. Turned out Chrome sends Accept: text/html,...;q=0.9 by default, and Po's FHIR server was parsing the q=0.9 as a FHIR version specifier. Workaround: fetch from the browser console with an explicit Accept: application/fhir+json header. Not my bug to fix, but a landmine worth documenting for anyone who follows this path.
Two different success shapes. order_tb_workup returns success implicitly — empty errors list means success. The newer two tools return status: "ok" explicitly. My first benchmark assumed one shape everywhere, so four tests failed even though the tools were correct. I had a choice: change the tool contracts (and invalidate the demos and screenshots I'd already produced) or normalize the benchmark assertions. I normalized the benchmark. Benchmarks should adapt to the system they measure; the other direction produces liar's tests.
Render cold-starts. Free-tier Render spins down after fifteen minutes idle, so the first request after a quiet period takes thirty to fifty seconds. That's a catastrophic failure mode for a live demo. I documented a warm-up curl to /healthz as the first step of every demo script. Judges should never see that cold start.
The "TB-001" name lies. Kenya moved from paper TB-001 registers to TIBU, an electronic case-based system, in 2011. "TB-001" still circulates as shorthand for the notification schema even though the paper form is retired. I built the PDF layout from the field set documented in the NTLD-P Operational Manual and the 2023 Annual Report, and labelled the output honestly: "TB-001 equivalent; TIBU-compatible." Pretending I'd reproduced a current official form would be worse than saying what I actually did.
Accomplishments I'm proud of
Three write-capable MCP tools published under Jamii Health Innovations on the Prompt Opinion marketplace. Most submissions in this hackathon expose read-only tools. DaktariTB writes ServiceRequest, MedicationRequest, DetectedIssue, and DocumentReference resources — every one of them auditable back to source data.
10/10 on the clinical benchmark with a guideline citation behind every expected outcome. Four of those scenarios are negative cases that test discrimination. I haven't seen another submission with a reproducible benchmark like this.
Emergent multi-tool coordination. The Samuel Kiprop demo wasn't scripted. The agent decided on its own that "file the notification" implied checking for interactions. Designing for that — rather than hard-coding the coordination — feels like the right shape for this category of tool.
Real African clinical context. I went out of my way to use NTLD-P terminology, TLD naming, KMFL facility codes, and Kenya Data Protection Act (2019) framing. Not generic "healthcare AI." Kenya's TB/HIV co-infection workflow specifically.
Judge-reproducible. Five minutes from marketplace install to hero demo running in a judge's own workspace, via the seed script.
Full clinical decision coverage in the fixtures. The five-patient bundle includes PLHIV with TB, PLHIV without TB, HIV-negative TB, the co-infection case, and a pre-ART HIV case. Every discrimination path in every tool has a matching patient.
What I learned
Clinical correctness is a benchmark, not a claim. Most healthcare AI demos assert correctness in their README and move on. I wrote the benchmark specifically because asserting correctness felt dishonest without something that exercised it. The benchmark pushed me to write scenarios I would otherwise have skipped — specifically the four negative cases, where the correct behavior is refusal. Those are the tests I'd want a clinician to see first.
MCP tools are best kept deterministic. The temptation was to let the tool itself call another LLM to "interpret" clinical data. I resisted it. The LLM orchestrates — the tool applies guidelines as code. The reason is regulatory: every drug dose DaktariTB writes is the dose the Kenya MOH guideline actually specifies, which is auditable, reviewable, and reproducible. If I'd let an LLM choose the dose, that's a whole different conversation with a hospital's clinical governance committee.
Honest data gaps beat fabricated completeness. When a chart doesn't have a DOT supporter or a patient phone, the notification PDF flags the missing field. It does not invent one. This is a small thing in code terms and a huge thing in health-IT-maturity terms. Real clinical data is messy. Good tools make the mess visible.
The pattern generalizes beyond Kenya. I started with Kenya because that's the system I know. But the same shape — clinical reasoning at the top, deterministic FHIR writes at the bottom, mandatory national surveillance form in the middle — fits India's NIKSHAY, South Africa's ETR.Net, Vietnam's VITIMES, the Philippines' ITIS. It fits HIV registries, cancer registries, COVID reporting. DaktariTB is one instance. The template has much more to give.
What's next for DaktariTB
Real EHR deployment. DaktariTB already works against any FHIR R4-compliant endpoint. The next step is pointing it at a KenyaEMR (OpenMRS-based) instance in one Kenyan county as a standalone MCP consumer, with Prompt Opinion becoming one of several possible agent layers on top of it. Production traffic, real charts, a TB coordinator who signs off on what gets notified. That's where this needs to live.
Contact tracing. A find_tb_contacts tool that reads an index case's FamilyMemberHistory and RelatedPerson resources, produces a risk-ranked contact list (under-5 children and immunocompromised contacts rated high), and writes a FHIR Task per contact for community health worker follow-up. This is the biggest unsolved gap in sub-Saharan TB surveillance — three to ten contacts per case, only a fraction currently screened.
Direct TIBU submission. DaktariTB currently produces a TIBU-compatible payload as a DocumentReference. The next step is a direct submission path — either via the NTLD-P API when it ships, or via a structured CSV export into the existing manual workflow.
MDR-TB escalation. When GeneXpert MTB/RIF returns RIF resistance detected, the workflow forks: second-line DST, a DR-TB notification variant, and drug-specific monitoring requirements. Kenya's DR-TB burden is rising and the workflow is materially different from drug-susceptible TB.
Pediatric dosing. All three tools currently assume adult dosing. Pediatric TB workup, pediatric TB/HIV co-treatment, and pediatric DR-TB are active problems and the regimens are materially different.
Orchestrator composition. Prompt Opinion's Orchestrator pattern lets multiple specialist agents collaborate on one clinician request. DaktariTB Specialist paired with an Orchestrator could fire a new-TB-diagnosis workflow that runs notification, contact tracing, and DOT supporter onboarding in parallel — each with its own deterministic FHIR actions at the bottom.
DaktariTB is a focused first step, not an endpoint. The repository is Apache 2.0. It's built to be forked, extended, and deployed in any FHIR-enabled clinical environment — Kenya or anywhere else that needs clinical AI that actually does the paperwork.


Log in or sign up for Devpost to join the conversation.