-
-
Semantic Graph
-
Spider Graph
-
Spider Graph
-
Focus Screen

Daki Life — A Living Knowledge Graph for Your Mind
Inspiration
Journaling works — but nobody does it consistently. It requires carving out dedicated time, staring at a blank page, and knowing what to say. Most people give up before the habit forms. And even when they don't, their thoughts pile up in a flat list they never return to.
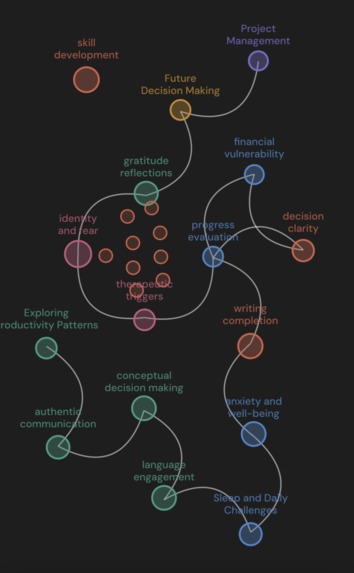
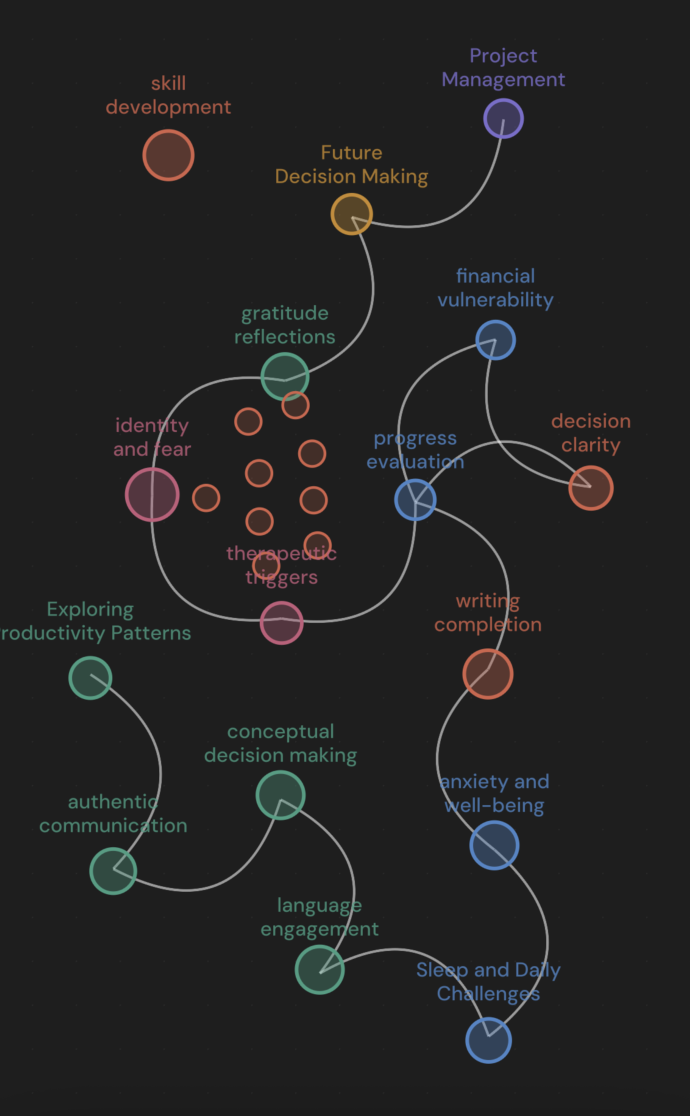
Daki Life turns the time you're already spending into a journaling habit. Run a Pomodoro, work, and when the timer ends, write one short note about what was on your mind. Thirty seconds. No blank page, no pressure. Over a session, those notes stop being a list and start becoming a map. Your thoughts self-organize into clusters — Health, Creativity, Relationships — with sub-topics nested inside. Thoughts that don't fit float as outliers instead of getting forced into a box. The map rebuilds in real time, so by the time you're done working, you can see exactly how your mind was moving.
Your ideas don't disappear anymore. They find each other.
What It Does
Daki Life is a focus journal that builds a living semantic knowledge graph from your reflection notes.
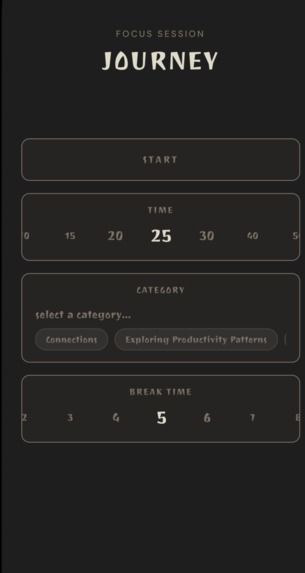
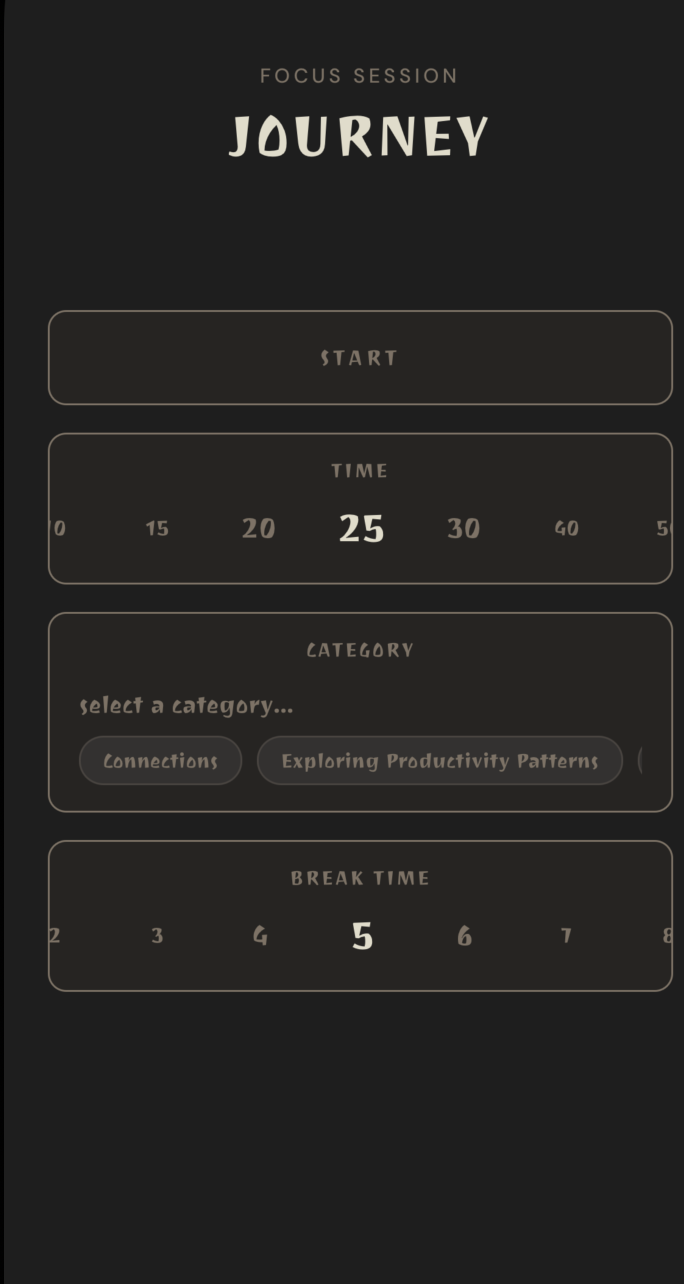
- Focus — Pomodoro-style timer with structured reflection prompts at the end of each work block.
- Graph — Semantic Knowledge Graph — Interactive graph that automatically maps your notes into clustered life themes like Health, Creativity, and Relationships.
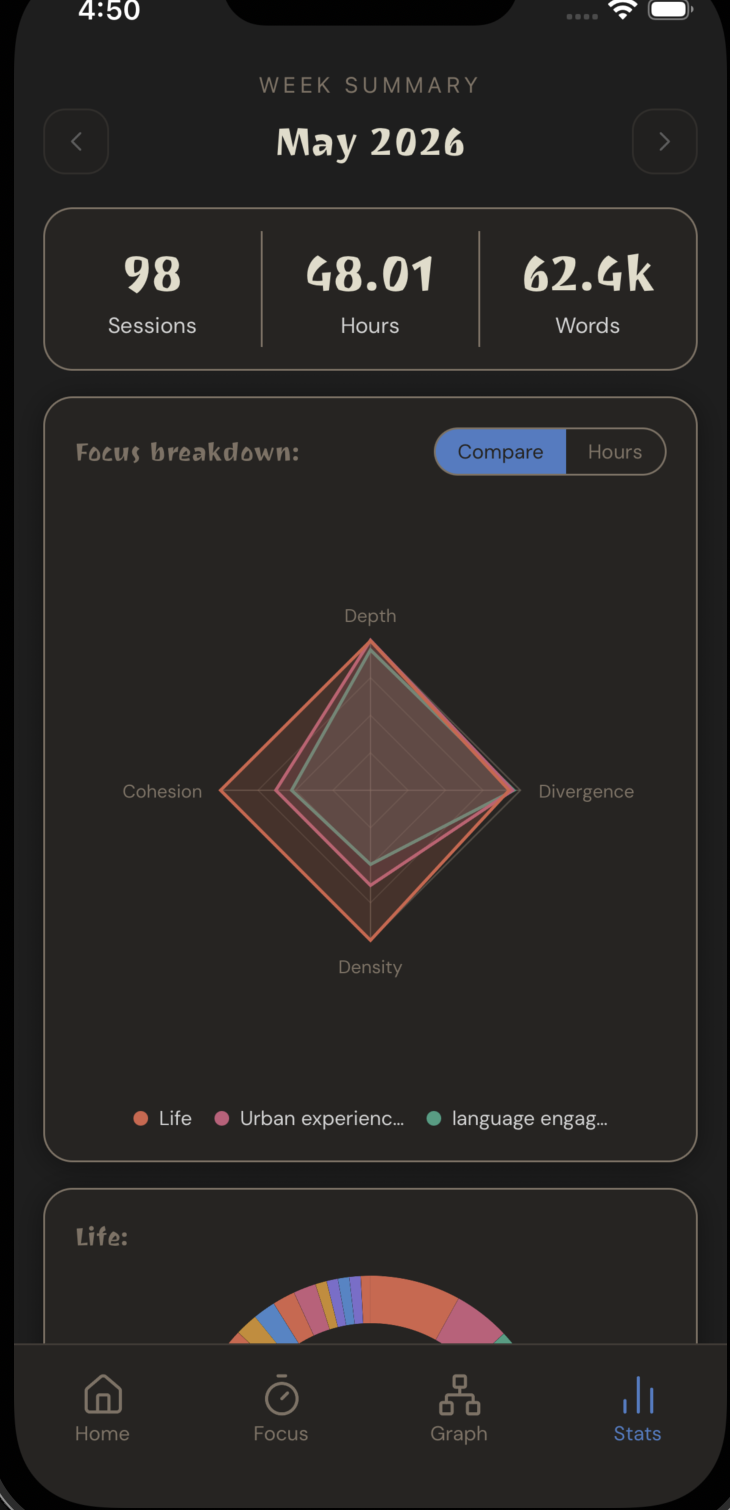
- Home — At-a-glance stats: sessions logged, top clusters by volume, and where your mental energy is actually going.
You don't just see what you wrote. You see who you are becoming.
Social Impact & Value
Daki Life sits at the intersection of mental wellness, equitable access, and personal development.
- Therapy costs $150–$300/hour. Daki Life surfaces emotional and cognitive patterns for free — giving users a form of structured self-reflection previously only available to those who could afford support.
- Self-awareness is a learned skill — and most people never get the tools to develop it. Seeing that 80% of your notes cluster around Work Stress and almost nothing lives in Relationships is a moment of clarity no to-do app can offer.
- Burnout is invisible until it isn't. The graph shows neglected life areas before they become crises.
This is especially meaningful for students navigating identity formation, academic pressure, and emotional overload — often without support structures.
The AI Pipeline
This is where the data science lives. The graph isn't a feature — it is the product.
ClusterNode Object
The core of the backend operating on the ClusterNode object for the semantic journal graph
| Field | Type | Description |
|---|---|---|
id |
str |
Unique UUID for the ClusterNode |
parent_id |
Optional[str] |
ClusterNode parent (for traversing backwards) |
depth |
int |
Depth level of the ClusterNode |
note_ids |
list[str] |
All note IDs within the ClusterNode |
children |
list[ClusterNode] |
Children ClusterNodes (for traversing forwards) |
coordinates_2d |
dict[str, dict] |
2D coordinates for each note within the ClusterNode |
semantic_centroid |
Optional[np.ndarray] |
Each note's text content is given a 1536-dimensional vector; the semantic centroid is the average of all these vectors |
label |
Optional[str] |
All note texts undergo TF-IDF keyword extraction, producing a raw keyword list, which is then passed to a GPT-4o-mini API call to generate a label |
Embedding
Notes are embedded at write-time via text-embedding-3-small (1536 dimensions) and stored in Supabase + pgvector. No retrieval-time re-embedding — every note already lives in semantic space.
UMAP — Dimensionality Reduction
We run UMAP in two separate passes:
- 1536D → 8D for density-aware clustering, preserving local neighbourhood structure
- 1536D → 2D for graph layout (
min_dist=0.1), so semantically similar notes appear physically close
UMAP is preferred over t-SNE because it preserves global structure — clusters that are semantically related stay near each other in 2D, not just internally tight.
HDBSCAN — Recursive Hierarchical Clustering
HDBSCAN runs recursively on the 8D output to produce a multi-depth cluster tree:
Root ("Life") ├── Health │ ├── Running │ └── Sleep ├── Creativity └── Relationships └── Deep Connection
min_cluster_size adapts by depth:
depth 0 (root): max(10, floor(n / 16))→ 5–8 broad life themesdepth 1+: 3→ tight sub-topic groups
Outlier notes (label -1) are never force-assigned to the nearest cluster — they surface as standalone nodes. Every thought counts.
C-TF-IDF — Discriminative Label Extraction
Each cluster is treated as a single document. C-TF-IDF surfaces words that are specific to a cluster — high within it, rare across siblings:
$$score(term, cluster) = tf(term, cluster) \times idf(term, all\ clusters)$$
$$where\ tf = 1 + \ln(count)$$ $$idf = \ln\left(\frac{1 + m}{1 + df}\right) + 1$$
Top-10 n-grams per cluster are passed to GPT-4o-mini for final 1–3 word human-readable labels like "Creative Blocks" or "Deep Connection" — no user input required.
Identity Persistence — Jaccard Matching
On every rebuild, new clusters are matched to old DB records via Jaccard similarity on note membership:
$$J(A, B) = \frac{|A \cap B|}{|A \cup B|}, \quad \text{match if } J > 0.5$$
Labels are reused when the cluster's semantic centroid hasn't drifted — keeping your graph stable as new notes arrive. The full rebuild runs in under 3 seconds for ~250 notes.
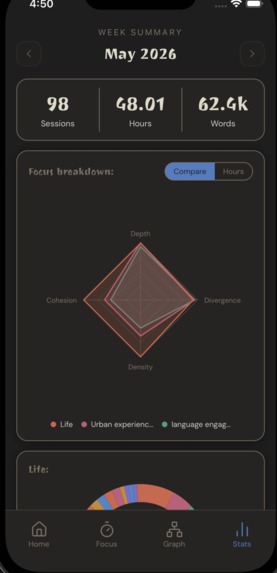
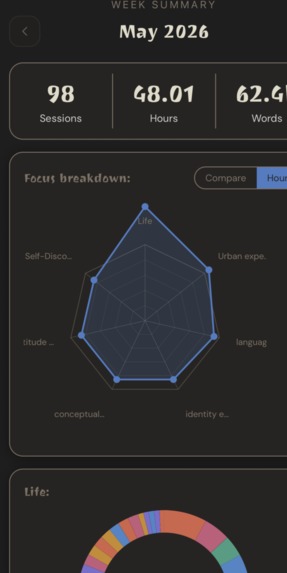
Cluster Metrics
Four scores are computed per cluster and min-max normalized across the full tree so they're always comparable regardless of corpus size.
Taxonomic Complexity — how much a cluster has structurally fractured into specific sub-thoughts. Instead of counting raw depth, it measures how deeply nested and populated the subtree is:
$$\text{TC} = \sum_{i \,\in\, \text{sub-clusters}} \bigl(\text{depth}_i \times \log(\text{note_count}_i)\bigr)$$
Information Density — vocabulary richness weighted by term specificity:
$$ID = \frac{U}{\sqrt{T}} \times \frac{1}{K} \sum_{k=1}^{K} w_k$$
where U = unique token types with non-zero TF-IDF weight, T = total raw word count, and w_1 through w_K are the top K TF-IDF scores (K = 8).
Semantic Cohesion — the mean cosine similarity of all note embeddings to the cluster centroid. High scores mean notes are tightly focused around a single idea:
$$Cohesion = \frac{1}{N} \sum_{i=1}^{N} \frac{v_i \cdot c}{|v_i| |c|}$$
Semantic Divergence — how distinct a cluster's thinking is from your overall baseline. Cosine distance between the cluster centroid c and the global centroid c_global (the average of every note in your database):
$$Divergence = 1 - \frac{c \cdot c_{global}}{|c| |c_{global}|}$$
A high divergence score signals niche interests or exploratory ideas far from your average thought.
All four scores are normalized to [0, 1]:
$$x_{norm} = \frac{x - min}{max - min}$$
Data Science Quality
| Pipeline Stage | Method | Why |
|---|---|---|
| Embedding | text-embedding-3-small | State-of-the-art; stored once at write-time |
| Dim reduction | UMAP (two-pass) | Preserves global manifold structure; faster than t-SNE |
| Clustering | HDBSCAN (recursive) | Noise-robust; no need to pre-specify k |
| Label extraction | C-TF-IDF + GPT-4o-mini | Discriminative, not just frequent |
| Edge weights | Cosine similarity via L2-normalized dot product | Efficient and numerically stable |
Data is never sold, never shared, and never used to train models. All embeddings and notes are scoped per-user via Supabase Row Level Security.
Clarity & Communication
The product is designed around one principle: insight should feel effortless.
- Semantically similar notes appear physically close on screen — no legend needed
- Cluster circle radius scales with note count:
r = max(9, min(30, 7 + 1.8√|notes|))— larger clusters look bigger - Outlier nodes float freely rather than being hidden
- The home dashboard surfaces your top clusters and streaks without overwhelming detail
You don't need to understand UMAP to feel what it shows you.
Innovation
Most AI journaling tools use LLMs as a chat interface — you ask, it answers. Daki Life inverts this: the AI observes, and you discover.
What's novel:
- Recursive semantic clustering applied to personal reflection — not documents or codebases, but lived experience
- Jaccard-based cluster identity persistence so insights feel stable, not chaotic, as your corpus grows
- Outlier preservation — treating noise as signal, not garbage
The graph isn't a visualization of your notes. It's a model of your cognition.
Tech Stack
| Layer | Tech |
|---|---|
| Mobile | React Native (Expo), TypeScript, Expo Router |
| Graph rendering | react-native-svg, D3 force simulation |
| Gestures | React Native Gesture Handler v2, Reanimated |
| API | Node.js, Express, TypeScript |
| ML sidecar | Python, FastAPI |
| ML libraries | umap-learn, hdbscan, scikit-learn |
| LLM | OpenAI GPT-4o-mini (labels), text-embedding-3-small (embeddings) |
| Database | Supabase (Postgres + pgvector + Auth + Realtime) |
What's Next
- Mood and energy tagging to correlate emotional states with semantic clusters over time
- Weekly reflection digests — an AI-generated summary of how your thinking has shifted in 7 days
- Accessibility-first redesign for users with ADHD and anxiety who struggle with open-ended journaling
Built for the AI For Good Hackathon in partnership with ACM-W. Because understanding yourself is one of the most meaningful things AI can help with.
Built With
- expo.io
- javascript
- openai
- python
- react-native
- supabase
- typescript


Log in or sign up for Devpost to join the conversation.