-
-

daisy logo
-
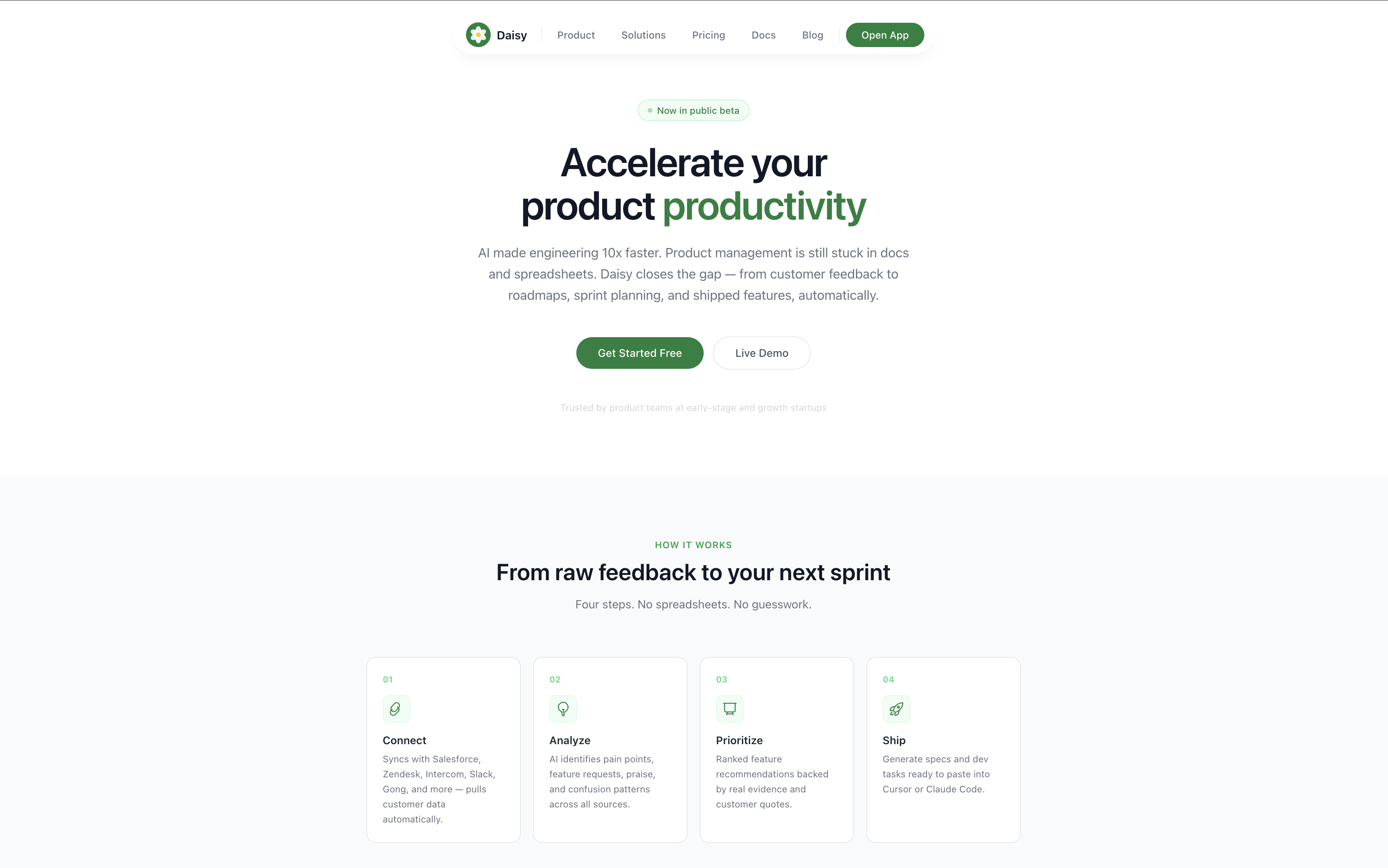
daisy lander
-
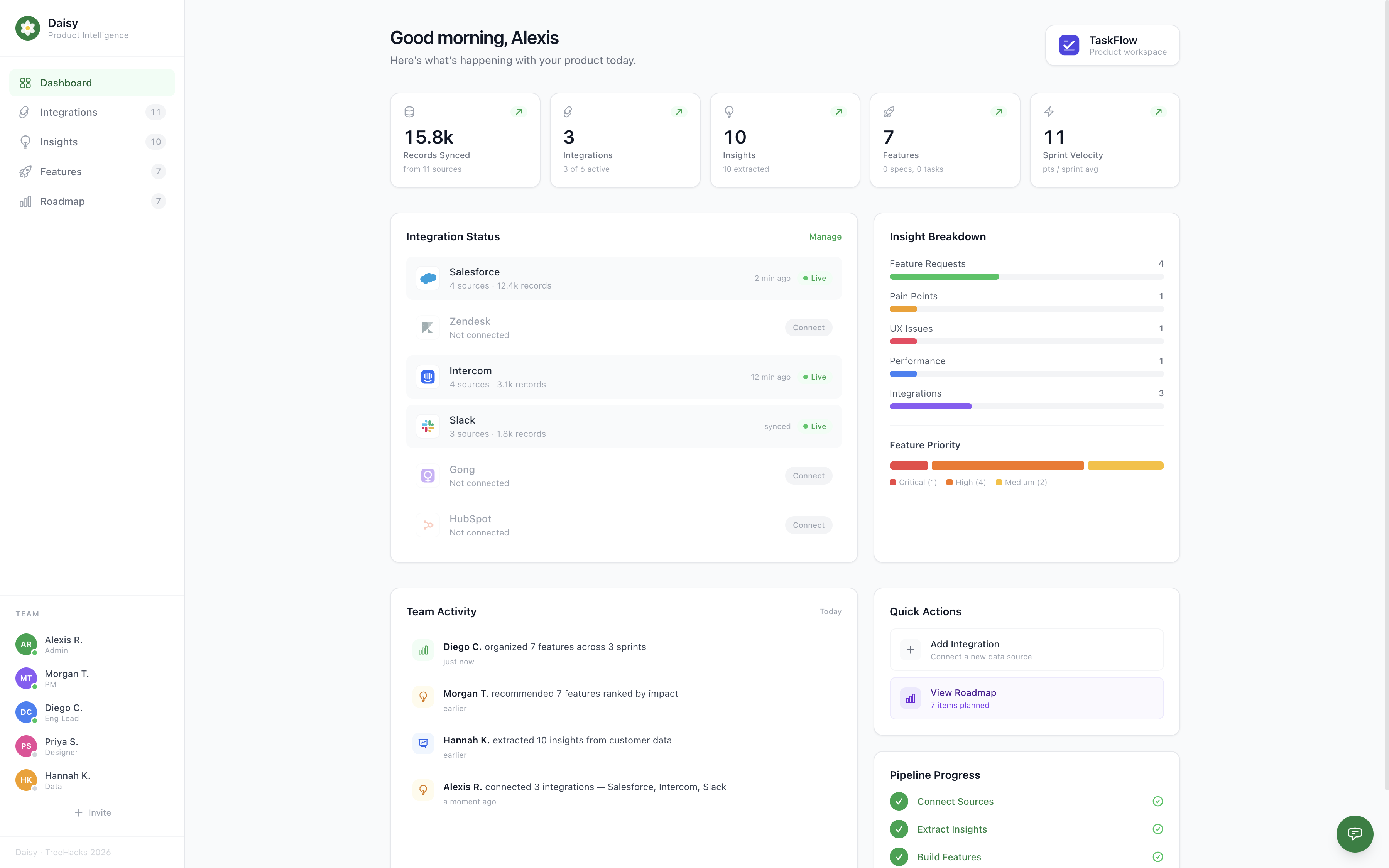
daisy dashboard
-
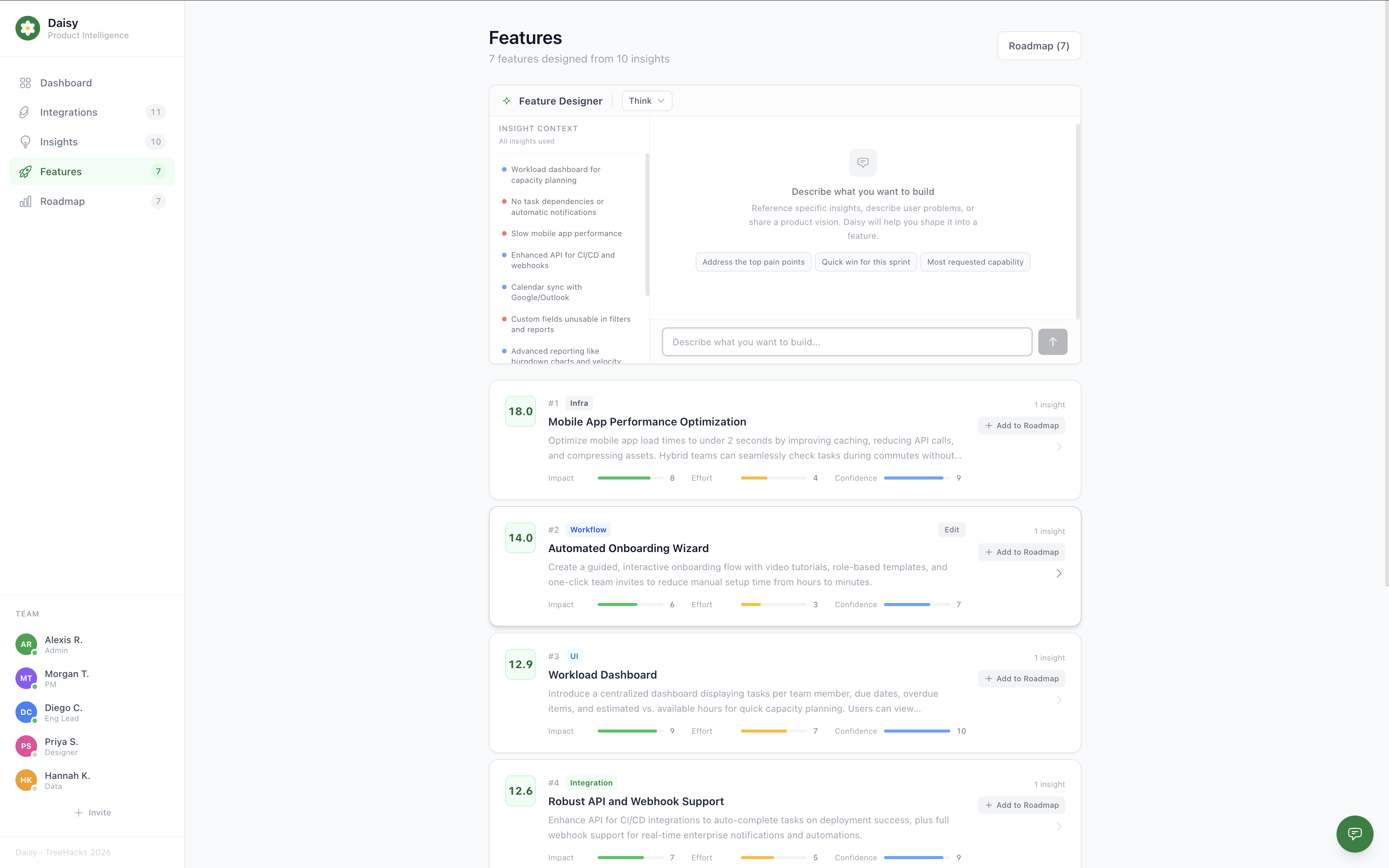
daisy feature designer
-
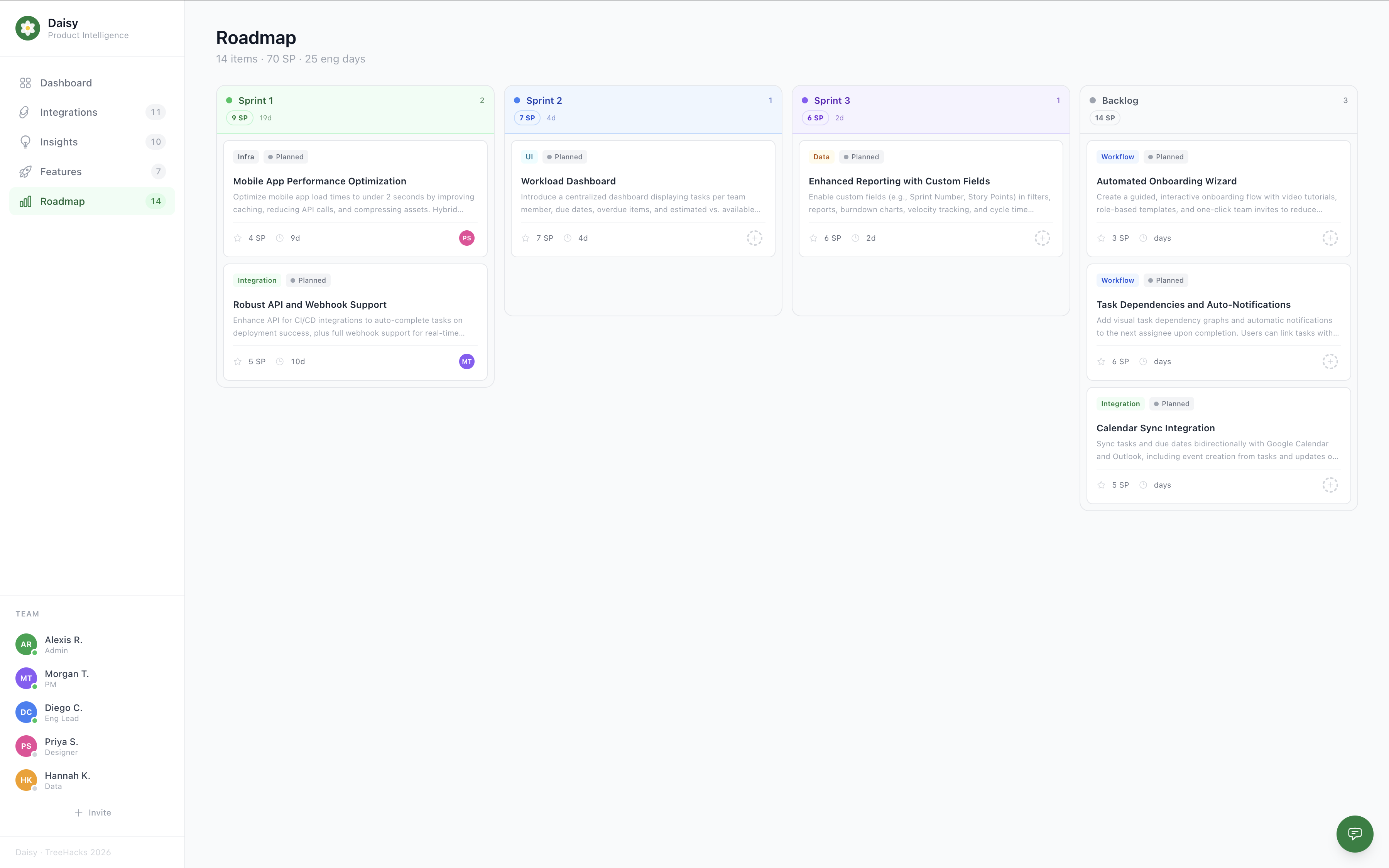
daisy roadmap builder

About Daisy
The Inspiration
Product and engineering teams often struggle with scattered feedback residing in support tickets, call notes, and transcripts. Daisy was built to centralize this data, using an AI workflow to transform raw feedback into insights, prioritized features, specs, and developer tasks while retaining the underlying rationale.
The goal was to create an AI partner—not just a summarizer—that understands the full product board (sources, insights, features, specs, tasks, roadmap) and answers questions like “what are we building and why?” using a pipeline of specialized agents.
What Daisy Does
Daisy is an AI-powered product workflow that converts customer data into an actionable roadmap.
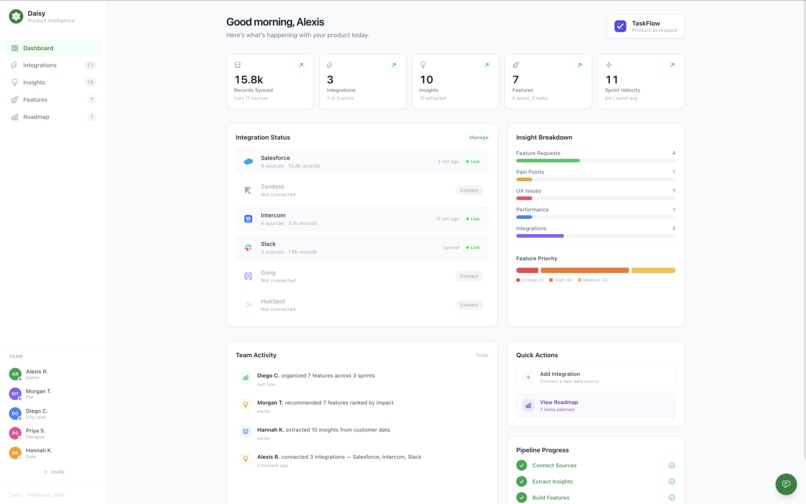
- Data Ingestion: Connects to integrations (Salesforce, Zendesk, Intercom) or accepts custom documents.
- Analyzer Agent: Extracts structured insights (pain points, requests, praise, confusion) with severity, frequency, and quotes.
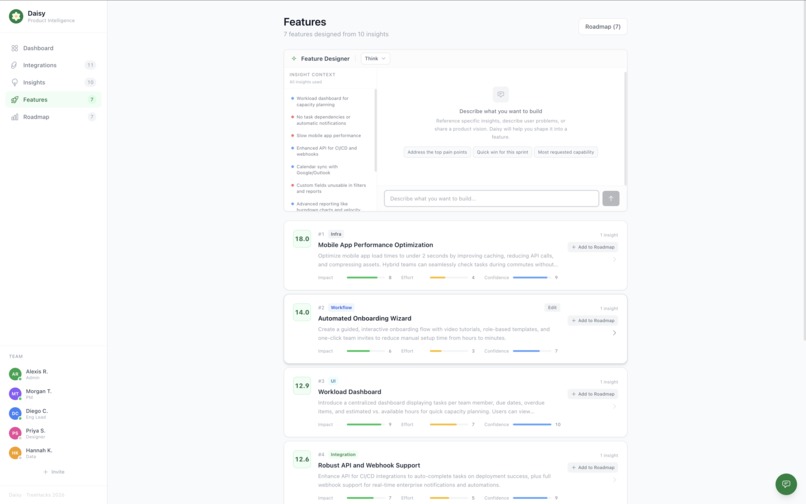
- Recommender Agent: Converts insights into prioritized feature ideas based on impact, effort, and confidence.
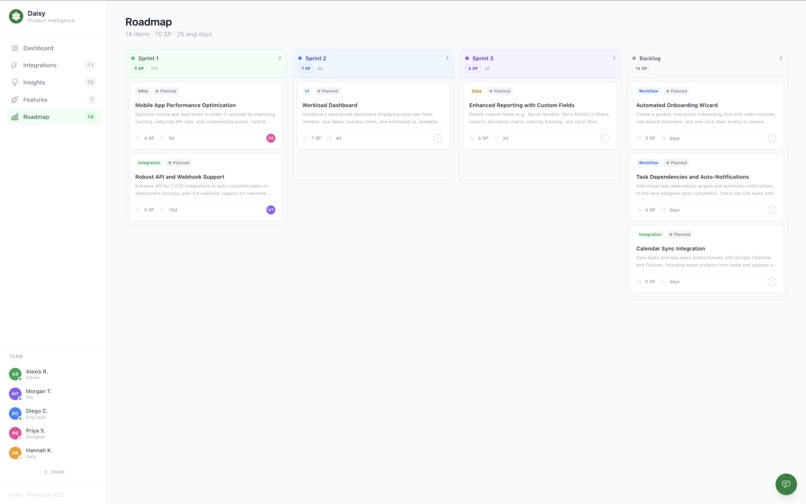
- Spec & Task Generation: Generates full specs (user stories, UI changes, data models, metrics) and breaks them into developer tasks with prompts ready for coding tools (Cursor, Claude).
- Validation Agents:
- Researcher: Provides market and competitive context.
- Critic: Analyzes potential downsides ("why not build this?").
- Risk: Assesses privacy, security, and compliance.
- Estimator: Refines story points and engineering days.
- Chatbot: Uses a hybrid retrieval system (Pinecone) to embed board entities. It retrieves relevant chunks per query to ground responses in real team data without exceeding context limits.
How We Built It
- Frontend: Next.js 14 (App Router), React, Tailwind, Framer Motion, and Zustand (with localStorage persistence).
- Agents: Dedicated LLM agents with specific system prompts and JSON outputs. An LLM adapter allows switching between OpenAI and Anthropic.
- Flow: Analyzer → Recommender → Spec/Task Writers → Validation Agents.
- Chat: Implements Pinecone for semantic retrieval. Queries generate embeddings to retrieve top-k relevant board entities (insights, features, specs) for injection into the system prompt.
- API: Next.js API routes handle analysis, recommendations, specs, tasks, and validation. Embedding routes upsert entities into Pinecone for retrieval.
Challenges We Ran Into
- Syncing Integrations: Fixed a bug where disconnecting an integration failed to remove sources by deriving "connected" status directly from source data.
- Useful Validation: Integrated validation outputs directly into the feature object and chat retrieval pipeline to ensure agents (Researcher, Critic, etc.) are active parts of the system rather than isolated tools.
- Context Limits: Shifted from full-board injection to Pinecone-based semantic search to support growing teams and large datasets.
Accomplishments We’re Proud Of
- End-to-End Pipeline: Successfully built a flow from raw feedback to developer prompts with minimal friction.
- Validation Tab: Enabled informed decision-making (Research, Critic, Risk, Estimate) directly within the product context.
- Scalable Retrieval: Implemented real semantic retrieval to allow reasoning over large boards while maintaining accuracy.
What We Learned
- Prompt Engineering: Clear JSON schemas and strict instructions are critical for chaining multiple agents.
- State Management: Deriving UI state from persisted data prevents synchronization bugs.
- RAG Implementation: Retrieval-augmented generation is essential for grounding team-specific chatbots without overwhelming context windows.
What’s Next for Daisy
- Live Integrations: Implementing OAuth for real-time syncing with CRM and support tools.
- Sharing & Export: Adding shareable links and PDF/Notion exports for stakeholders.
- New Agents: Developing agents for dependency sequencing, changelog generation, and retrospective analysis.
Built With
- anthropic
- javascript
- next.js
- openai
- pinecone
- react
- tailwind
- typescript
- zustand


Log in or sign up for Devpost to join the conversation.