-
-
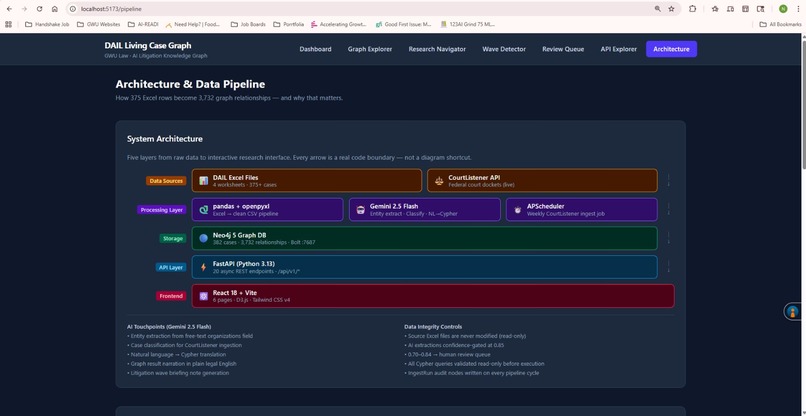
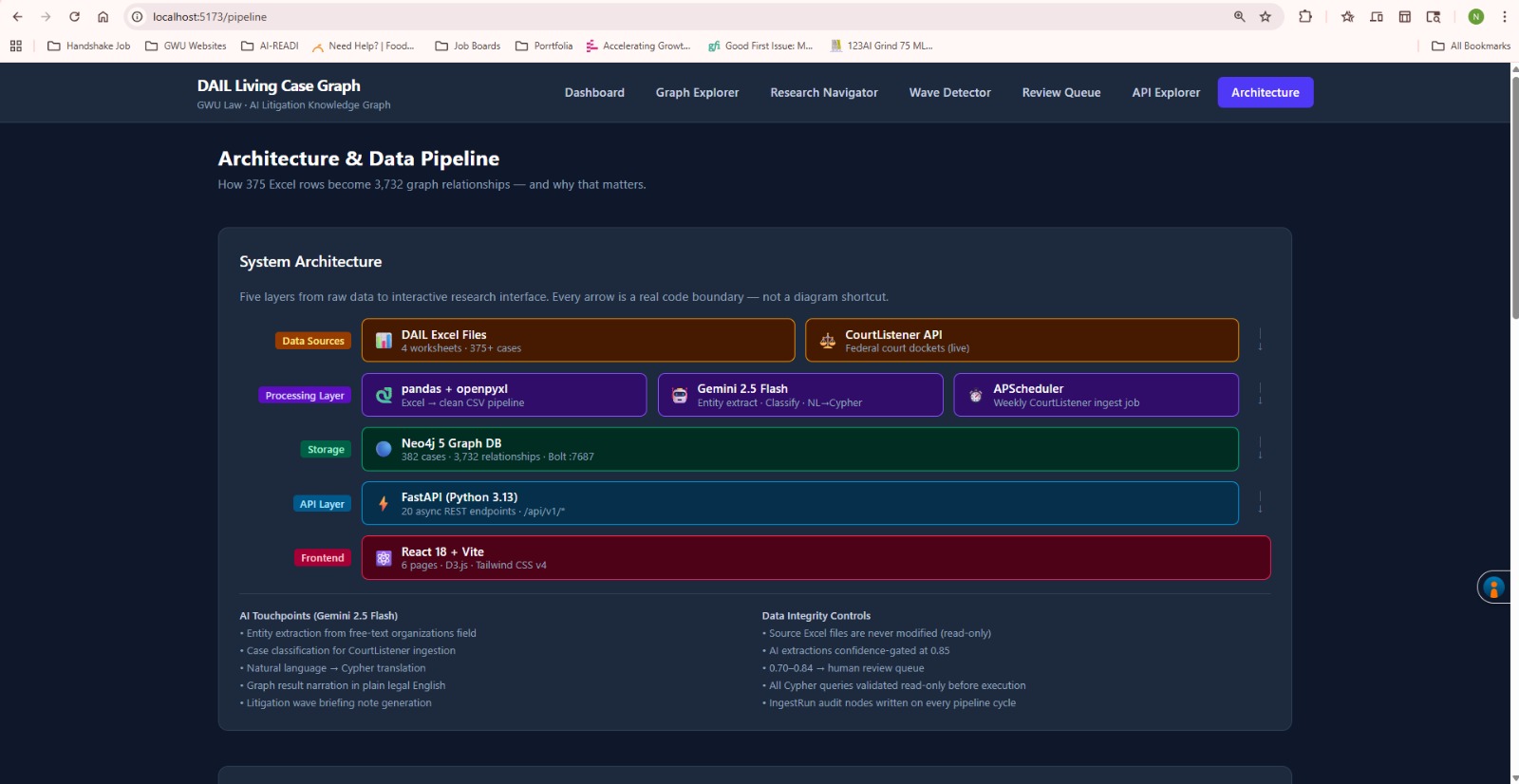
Architecture & Data Pipeline
-
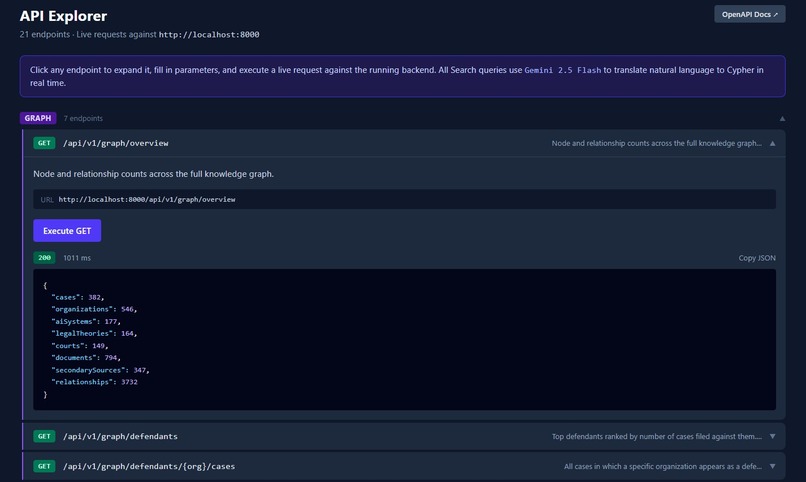
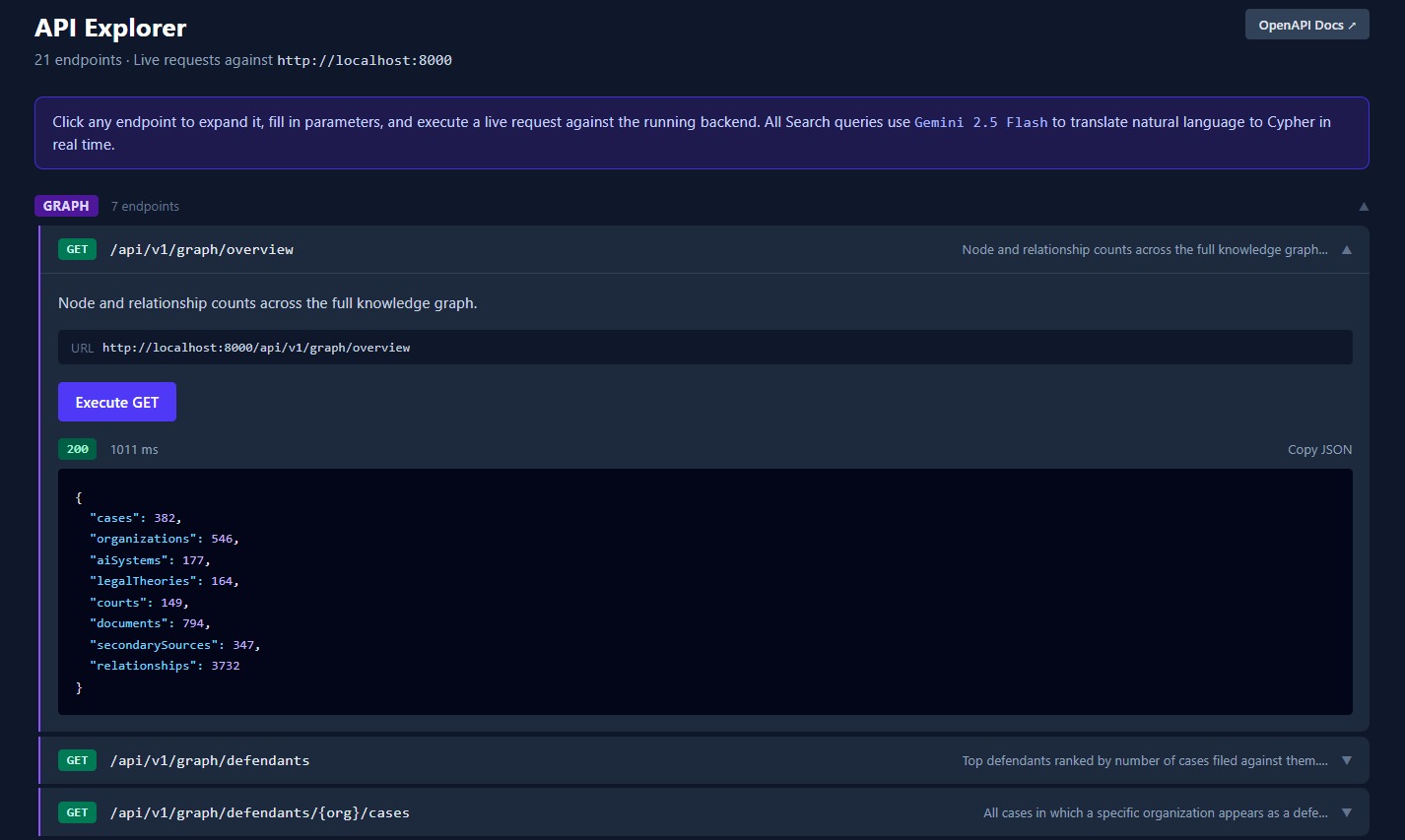
API Explorer
-
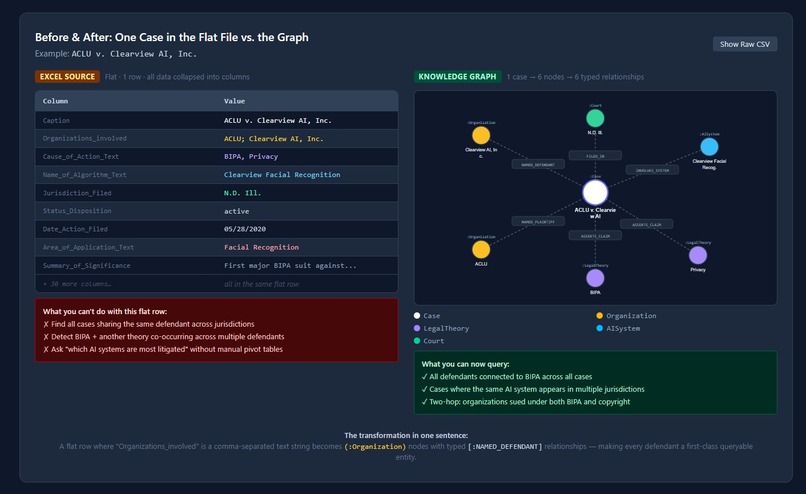
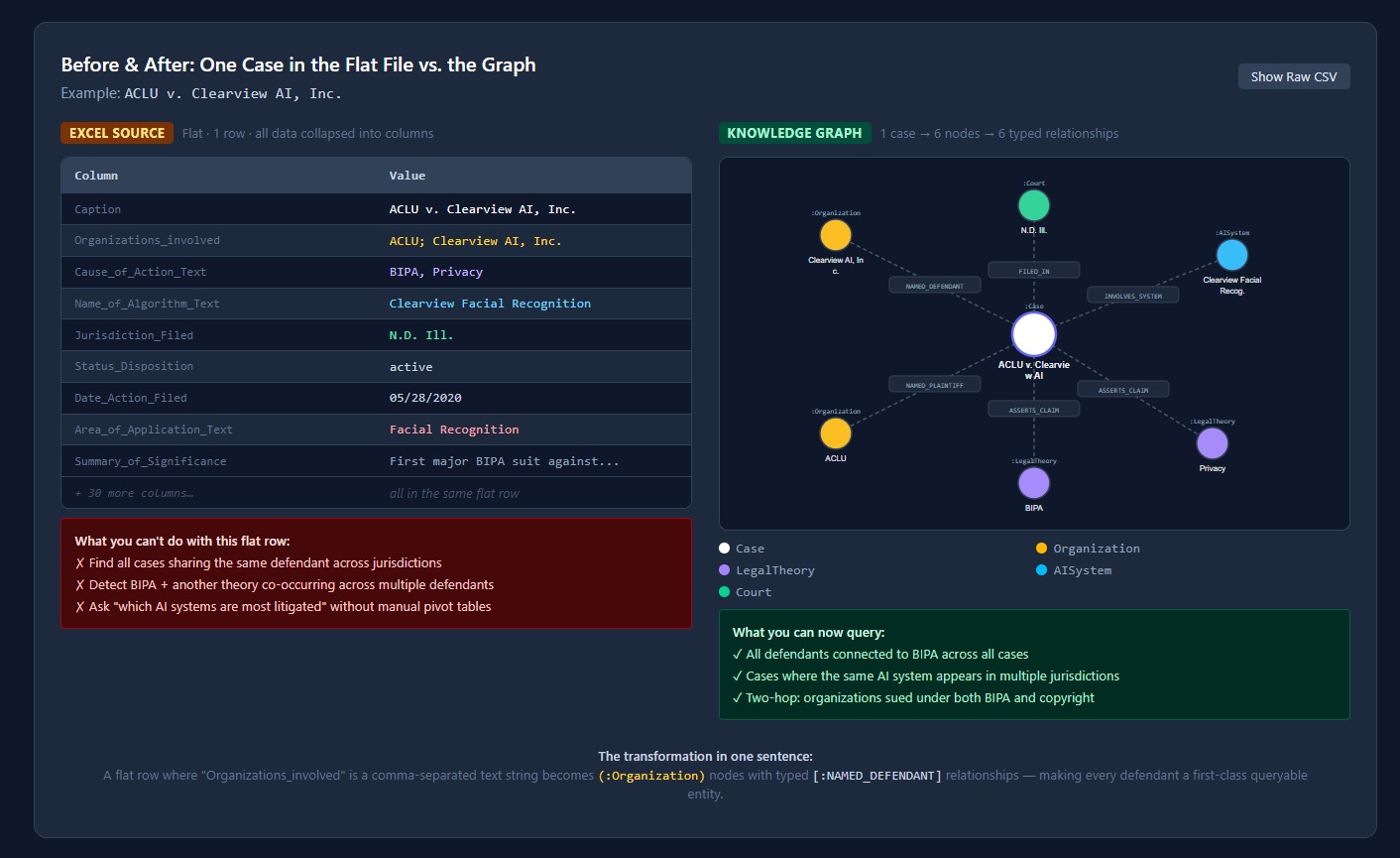
Before & After: One Case in the Flat File vs. the Graph
-
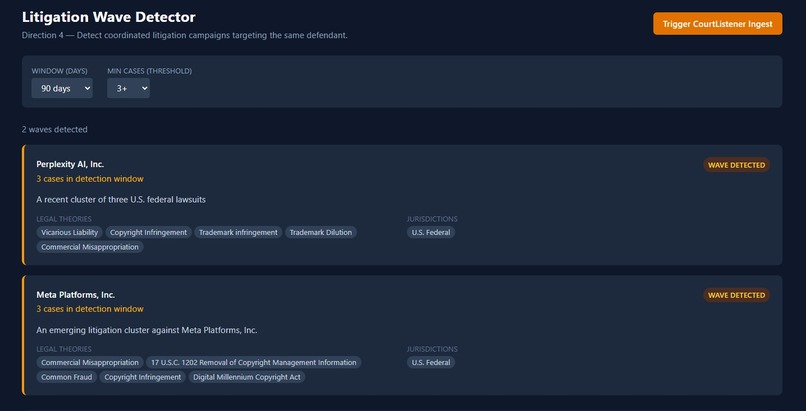
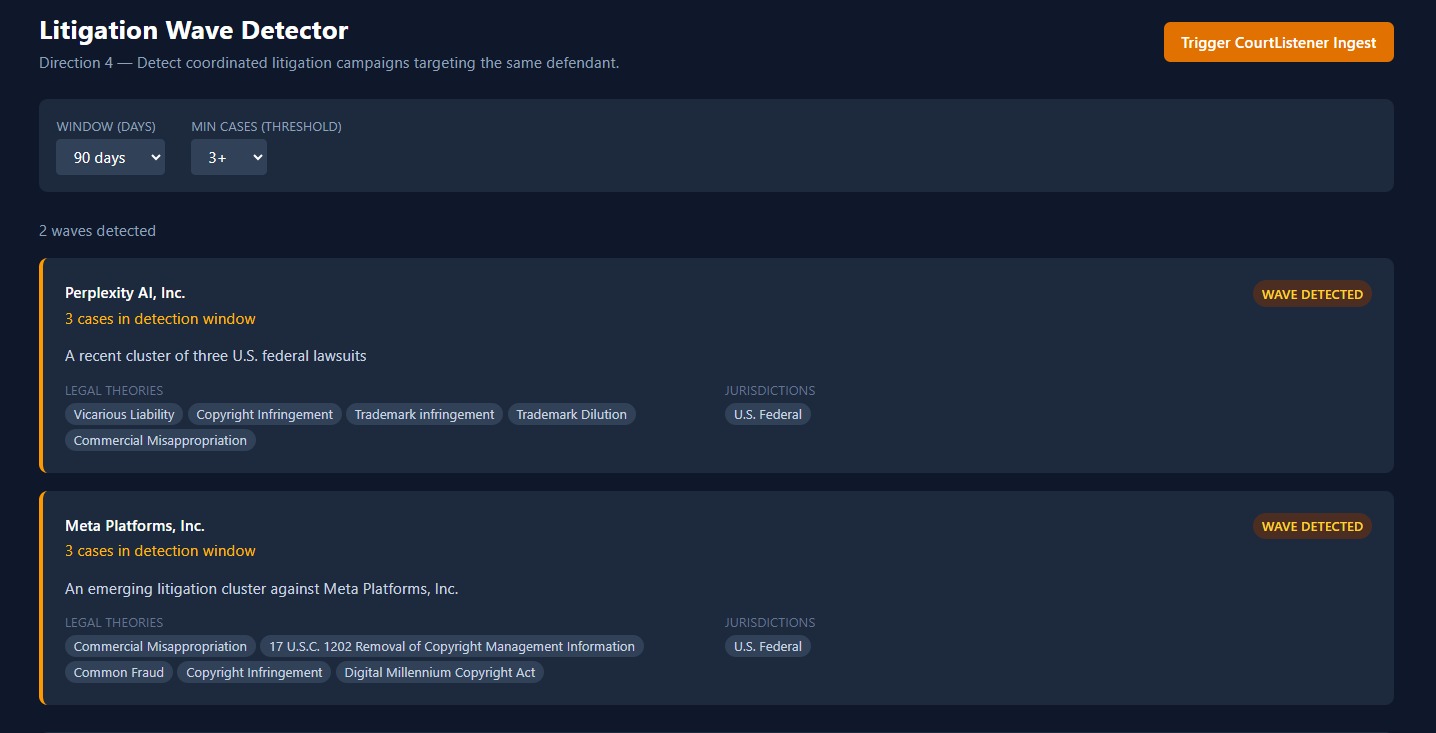
Litigation Wave Detector
-
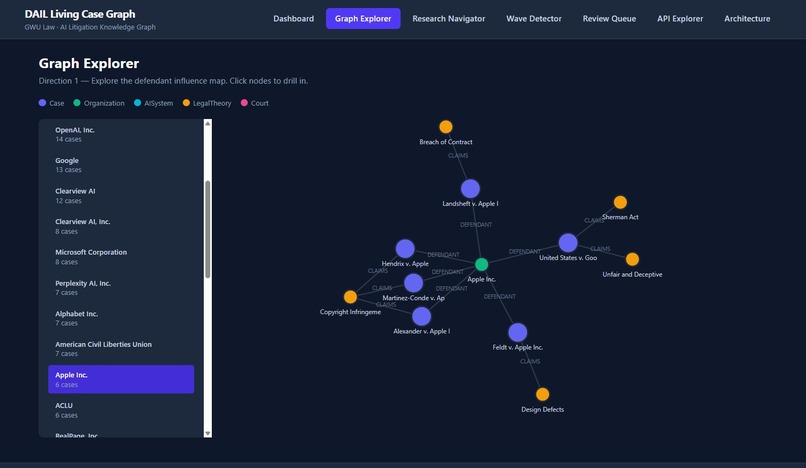
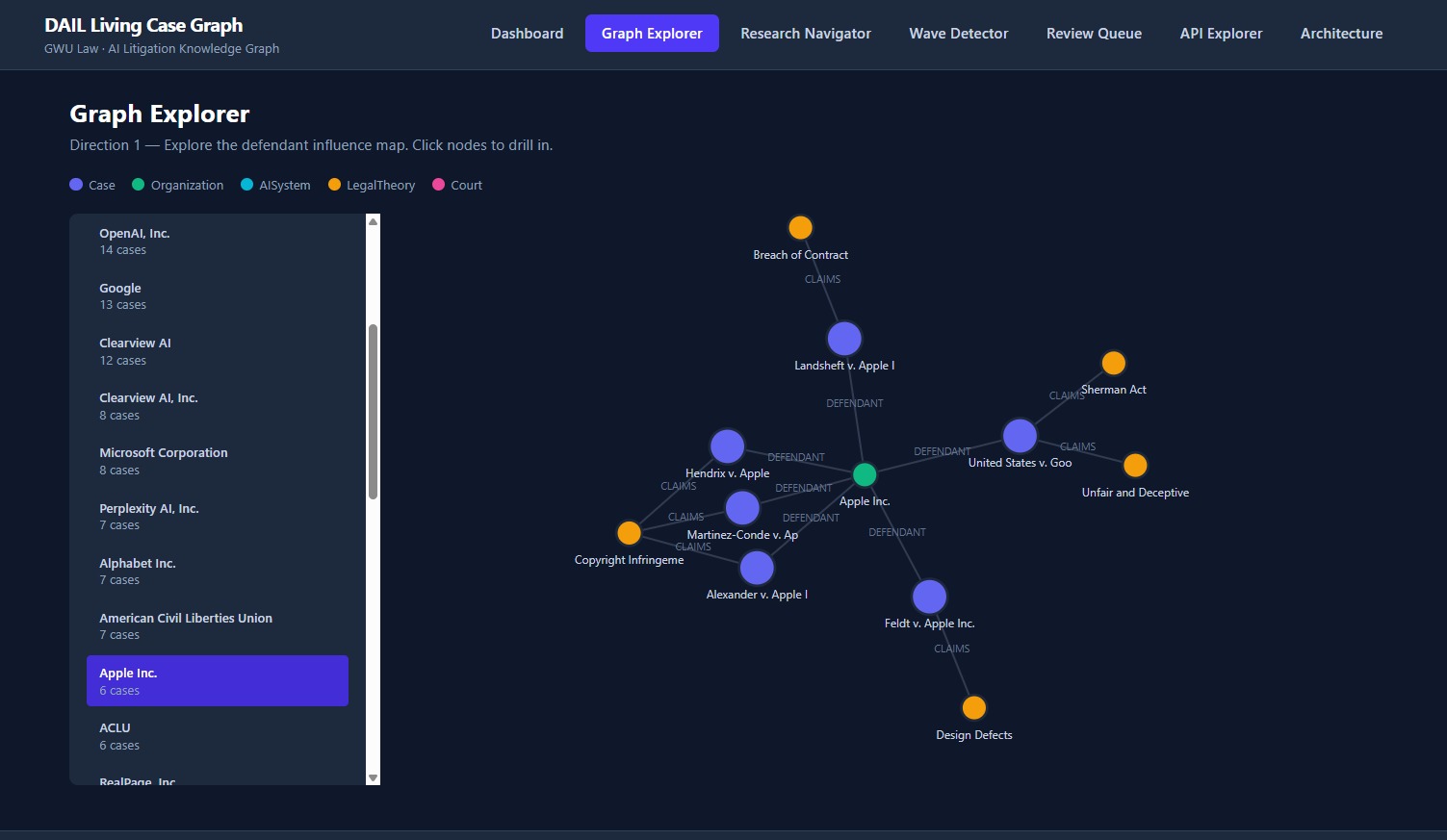
Graph Explorer
-
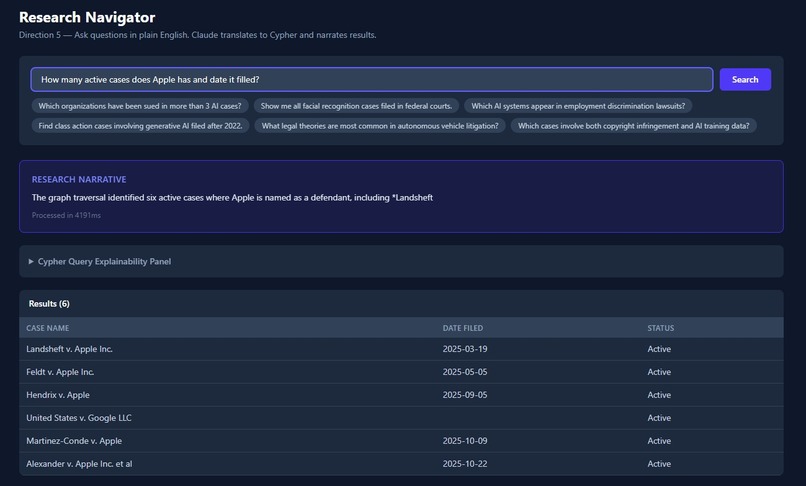
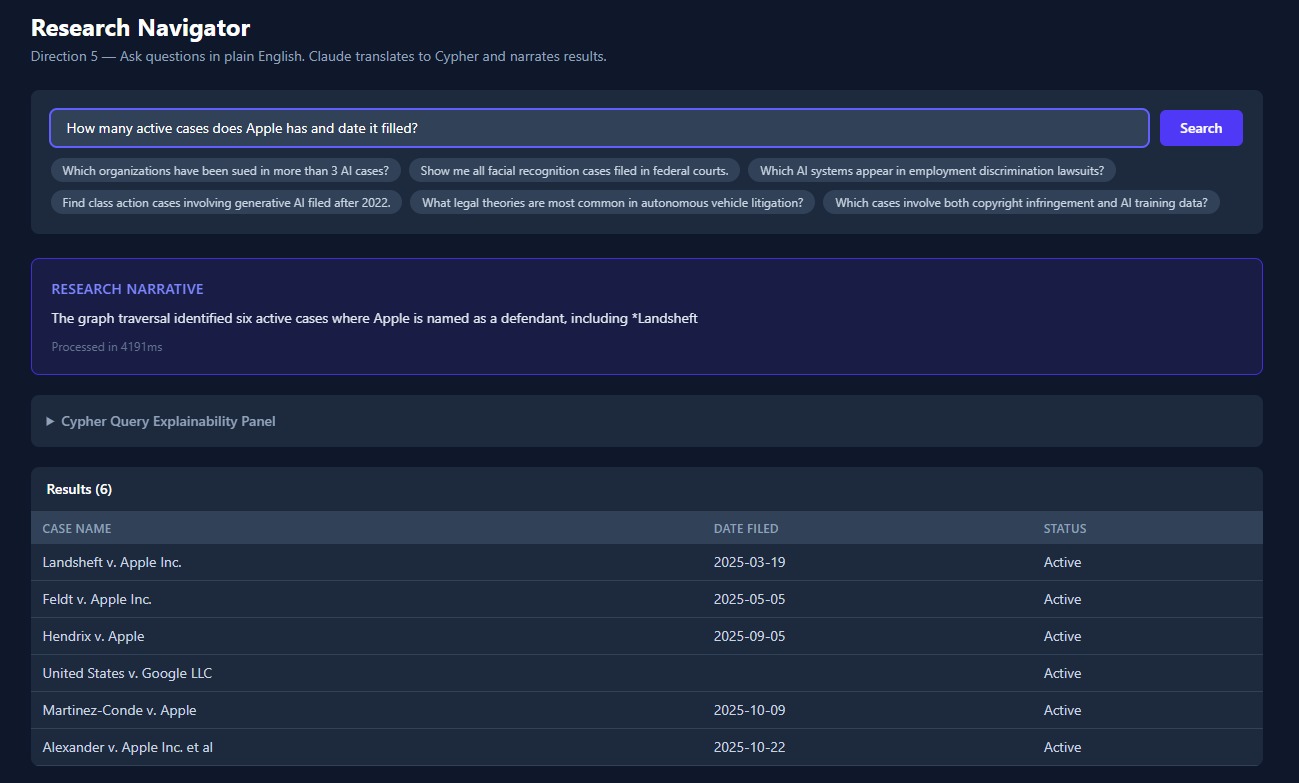
Research Navigator
Inspiration
GW Law's Database of AI Litigation is doing genuinely important work — cataloging every lawsuit where AI is at the center of the dispute. Facial recognition bias, algorithmic decision-making gone wrong, privacy violations — it's all in there. But it lived in Excel. Four workbooks, hundreds of rows, no relationships between anything.
The moment we saw the problem statement, the question felt obvious: what if each organization, each legal theory, each AI system wasn't just text in a cell — but an actual node you could traverse, query, and connect? That's when the graph idea clicked.
What it does
The DAIL Living Case Graph transforms GW Law's flat spreadsheet into a living, queryable knowledge graph with a full API layer and interactive research interface.
Here's what you can actually do with it:
Graph Explorer — An interactive D3.js force graph that maps defendant influence networks. Search any organization, click any node, explore the case neighborhood around it.
Research Navigator — Ask a natural language question like "Which organizations face the most BIPA claims in Illinois?" and get back a Cypher query, raw results, and a plain-English narrative. The query is shown to you in full — no black box.
Wave Detector — Automatically surfaces coordinated litigation campaigns by detecting clusters of cases against the same defendant within a configurable time window. Adjust the window and threshold, and it re-runs instantly.
Review Queue — Every AI-extracted entity goes through a confidence gate. High confidence gets written to the graph automatically. Anything in the middle range sits in a human review queue — approve or reject before it touches the database.
Dashboard — Animated live stats, top defendants with active/inactive breakdowns, AI system categories, and a filing trend chart from 2016 to present.
API Explorer — A live REST console built into the app. All 20 endpoints, executable directly in the browser without Postman or curl.
How we built it
Five layers, all real code:
Data Sources — GW Law's Excel workbooks (read-only, never modified) and a live CourtListener federal court API feed.
Processing — Python with pandas and openpyxl normalizes and cleans the raw data. Gemini 2.5 Flash handles entity extraction from free-text fields. APScheduler runs a weekly ingestion job from CourtListener to keep the graph current.
Storage — Neo4j 5 graph database running in Docker. Every case, organization, court, legal theory, and AI system is a typed node. Every connection between them is a typed relationship.
API Layer — FastAPI on Python 3.13. 20 async REST endpoints under /api/v1/, fully documented and interactive via the built-in API Explorer.
Frontend — React 18 with Vite, Tailwind CSS v4, D3.js for the force graph, and React Router v6. No UI library — everything is built from scratch.
The data pipeline is idempotent — you can re-run it as many times as you need without duplicating data. A SQL export script generates a portable SQLite database plus PostgreSQL and MySQL-compatible schema and insert files. Docker Compose brings the whole stack up in one command.
Challenges we ran into
Getting the graph schema right
The hardest design decision wasn't the code — it was figuring out what the graph should actually look like. Organizations_involved in the Excel file is a semicolon-separated string that mixes plaintiffs, defendants, and third parties. Deciding how to split, type, and relate those entities without losing legal accuracy took real thought.
Cypher query generation
Natural language to Cypher is harder than natural language to SQL. Graph query patterns — especially multi-hop traversals — don't have obvious analogies in plain English. Getting the Research Navigator to generate correct, useful Cypher from freeform questions required a lot of prompt iteration.
Confidence gating in practice
Setting the right thresholds for AI extraction (auto-approve vs. human review vs. discard) involved looking at a lot of actual outputs. Too strict and the pipeline throws away good data. Too loose and low-quality extractions contaminate the graph.
Keeping AI out of places it didn't belong
The temptation in a hackathon is to throw AI at everything. We made a deliberate call early on to limit Gemini to exactly two things: entity extraction during the pipeline, and query translation in the Research Navigator. Sticking to that line actually made the system more trustworthy and easier to reason about.
Accomplishments that we're proud of
The "Before and After" transformation is genuinely striking. One flat row with 38 columns becomes six typed nodes connected by six semantic relationships. That's not a demo trick — it's the actual output of running the pipeline on real DAIL data.
The Review Queue is a real human-in-the-loop design pattern, not a checkbox. It's wired into the graph write path — no approved extraction, no graph write.
The Wave Detector works on real data. Coordinated litigation patterns that would've taken hours to find manually surface in seconds.
We built a live REST console into the product itself. If you're a judge who wants to see what's under the hood — just go to the API Explorer tab and start hitting endpoints.
What we learned
Graph databases reward good schema design more than relational databases do. In SQL, you can paper over a bad schema with joins. In Neo4j, a bad node or relationship type creates friction in every query you write forever. Getting the schema right upfront — and keeping it clean — was one of the most valuable things we did.
We also learned that responsible AI use isn't really about what AI can't do in your system — it's about being deliberate about what it should do. The confidence gating, the human review queue, the read-only query validation — none of that was hard to build. It just required thinking about it at design time instead of bolting it on later.
What's next for DAIL-Knowledge-Graph
Full CourtListener sync — The live ingestion pipeline is built and running. Hooking it up to a production CourtListener API key would keep the graph continuously updated without any manual intervention.
Expanded entity types — Plaintiff organizations, expert witnesses, and presiding judges could all become typed graph nodes, enabling new query patterns.
Similarity scoring — Cases that share defendants, legal theories, and jurisdictions could be surfaced as "related cases" with a computed similarity score, not just shared edges.
GW Law integration — The SQL export pipeline means the data can move into whatever system GW Law already runs. The graph doesn't need to replace their infrastructure — it can sit alongside it.

Log in or sign up for Devpost to join the conversation.