Inspiration
466 million people worldwide are deaf, yet most everyday conversations still assume everyone can hear. We watched simple interactions like ordering coffee or asking for directions become frustrating barriers. Interpreters aren't always available. Text-based apps kill the flow of natural conversation. We wanted something that just works, put it on and talk.
What it does
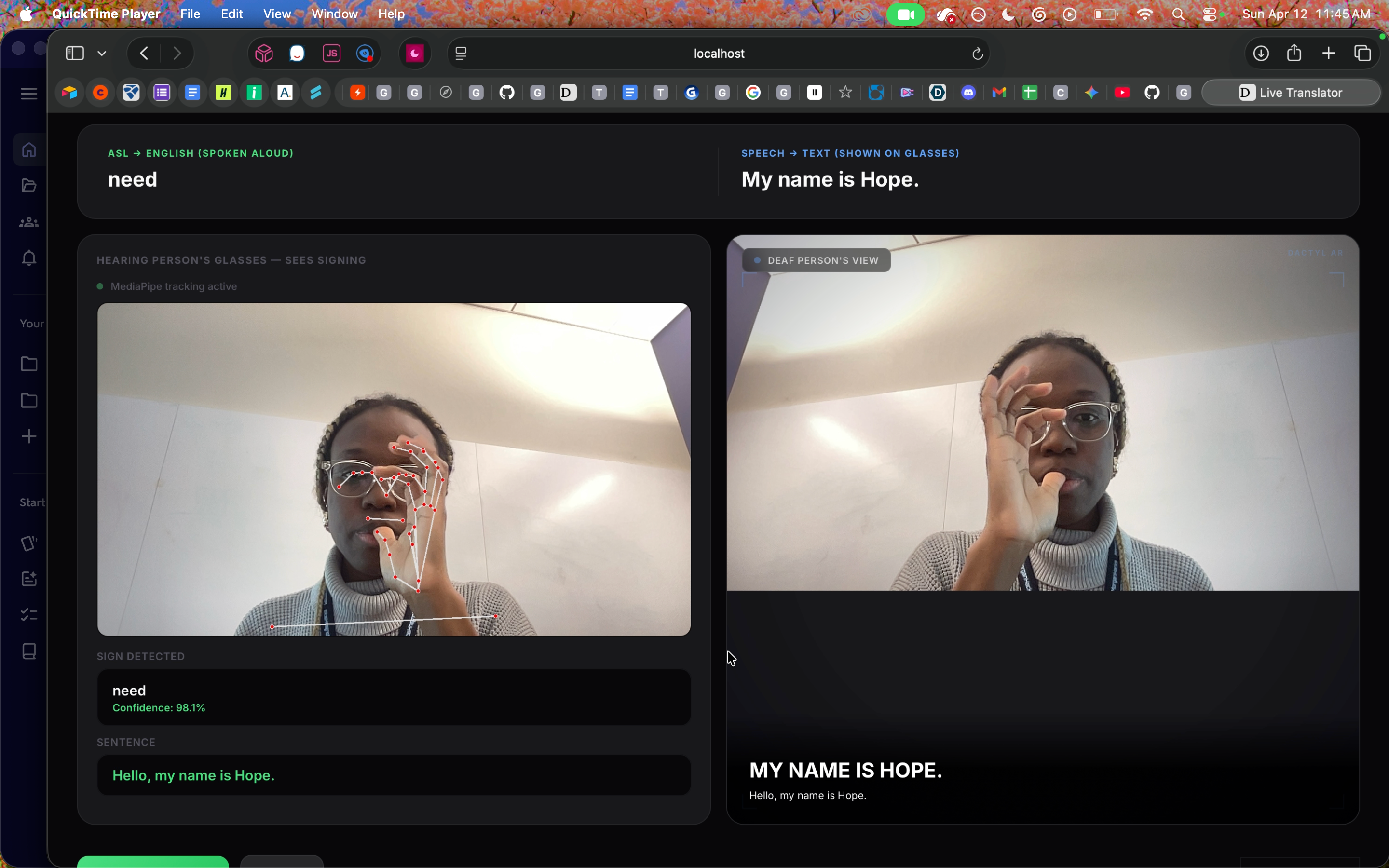
Dactyl is the first real-time bidirectional ASL translation glasses. A deaf person signs, and the hearing person hears it spoken aloud. The hearing person speaks, and the deaf person reads live captions. Two-way, real-time, no interpreter.
How we built it
- Custom dataset: we recorded over 400 videos of ASL signs ourselves, then extracted keypoint sequences to train our model from scratch.
- MediaPipe Holistic tracks 543 keypoints across hands, face, and body every frame.
- A custom LSTM neural network classifies signs from temporal sequences at 99% accuracy.
- Groq (Llama 3.3 70B) converts ASL gloss into natural English sentences in ~50ms.
- Edge TTS speaks the translation aloud using a neural voice, with pre-cached audio for <10ms playback
- OpenAI Whisper runs locally for speech-to-text so no internet required and no API costs.
- Flask + SocketIO ties everything together in a real-time web app streamed to the glasses display
- We optimized aggressively: sliding window prediction at 15 frames instead of 30, Groq over Claude for 10 times faster inference, and pre-cached TTS so playback is nearly instant.
Challenges we ran into
- Building our own dataset: we recorded and labeled 400+ sign videos ourselves. Hours of filming, re-filming, and cleaning data before we could even start training.
- Sign ambiguity: similar hand shapes mean different things depending on motion and facial expression. We moved from single-frame classification to temporal sequence analysis to capture the full arc of a sign.
- Camera juggling: macOS kept defaulting to the FaceTime camera instead of our external webcams.
- Latency budget: every millisecond matters in conversation so we had to rethink our pipeline multiple times, replacing cloud calls with local models and adding caching layers to keep the loop under one second.
- Threading on macOS: MediaPipe, OpenCV, and audio playback all fighting for resources on the same machine. Getting them to coexist without segfaults required careful lock management and daemon threads.
Accomplishments that we're proud of
- Built a working bidirectional ASL translation glasses prototype from concept to demo.
- Collected and labeled our own dataset of 400+ sign videos from scratch
- Achieved high sign classification accuracy with a custom LSTM model
- End-to-end latency under one second, fast enough for natural conversation
- Fully local speech-to-text pipeline so no cloud dependency orAPI costs for transcription
What we learned
- The hardest part of accessibility tech is making it feel natural enough that people forget it's there
- Local models (Whisper, LSTM) can match or beat cloud APIs when latency matters more than vocabulary size
- Generating Text to speech at startup instead of on-demand cut our response time by 90%
What's next for DACTYL
- Expand vocabulary
- On-device deployment: port the pipeline to smart glasses hardware so it runs without a laptop
- Fingerspelling support: recognize letter-by-letter spelling for names, places, and words outside the trained vocabulary
- Multi-language support: extend beyond ASL to BSL, LSF, and other sign languages
- Community data collection: open-source the training pipeline so the hearing-impaired community can contribute signs and improve accuracy






Log in or sign up for Devpost to join the conversation.