-
-
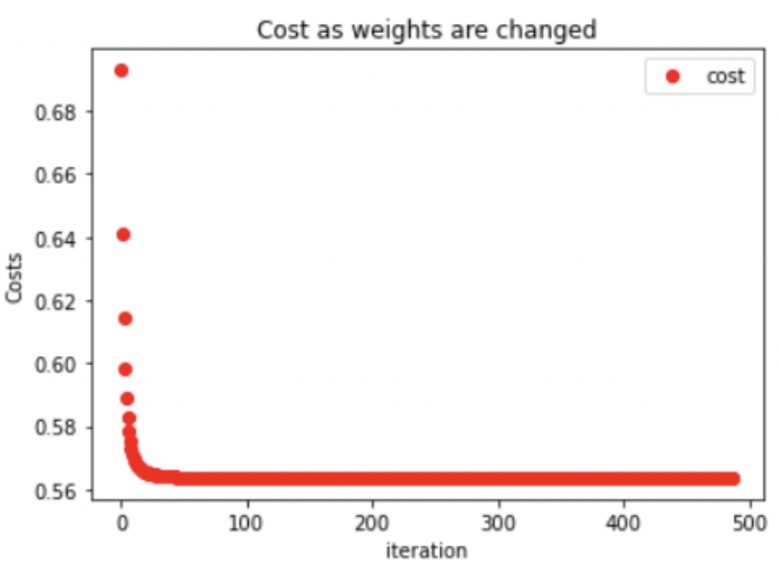
Cost Trend for Binomial Logistic Regression
-
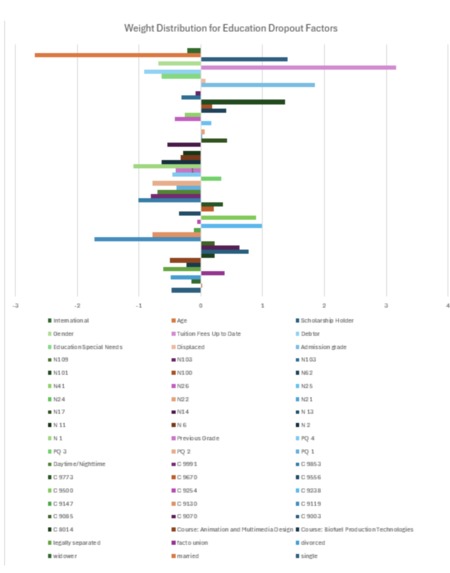
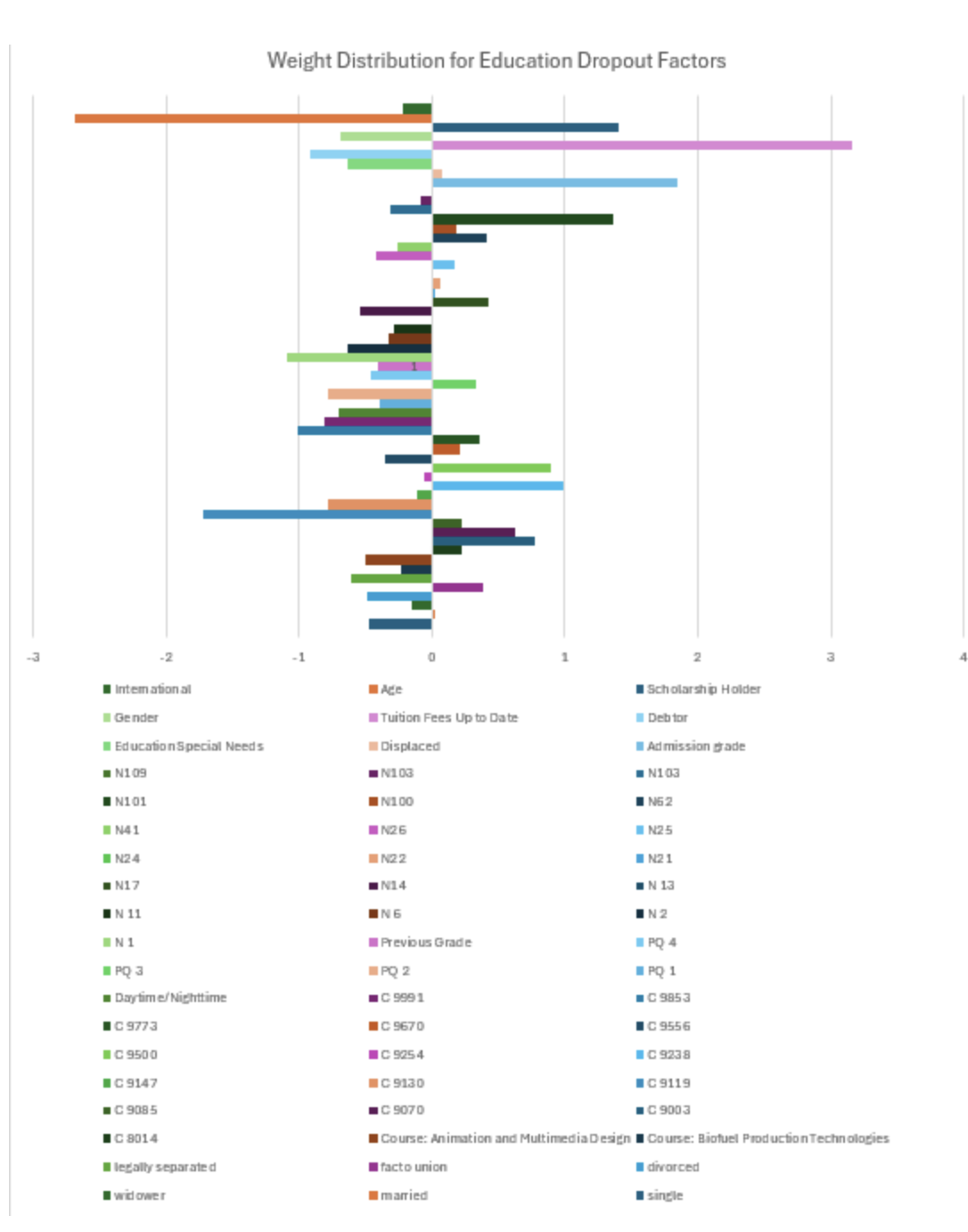
Weight Distribution for Education Dropout Factors
-
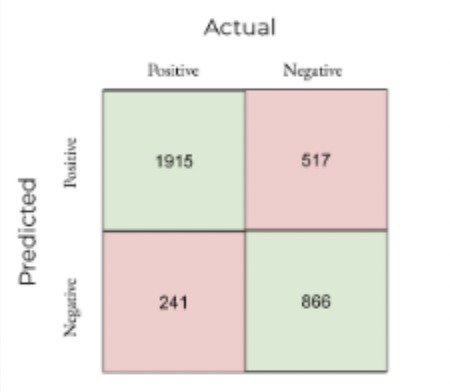
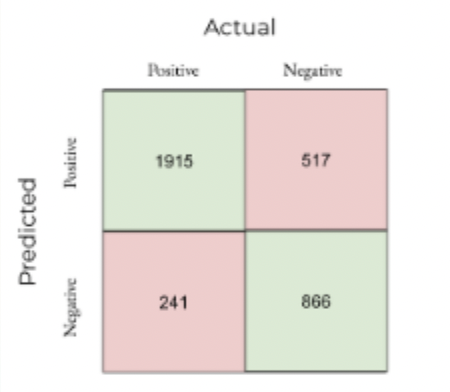
Confusion Matrix for Binomial Logistic Regression
Inspiration
As freshmen students at the University of Maryland, we understand the struggle of striking the right balance and not succumbing to the pressure that comes with college. We created Imparsonator to analyze different factors that can play into possible dropout reasons. We are empathetic to struggles that we often see from our classmates, and we wanted to expand past our vision to analyze more diverse data on reasons why college students drop off.
What it does
By providing analytical details through our logistic regression model which helps identify communities in danger of dropping out and an NLP prompting model based on GPT which queries our SQL database, Imparsonator can provide relevant information on the trends of college dropouts.
How we built it
NLP model: 1) SQLite 2) GPT (OpenAI) 3) Dotenv
Other ML models: 1) Logistic regression (multimodal + bimodal) 3) sklearn, mathplot.lib, & numpy 2) CSV
Parsonator's website: 1) HTML 2) Bootstrap API 3) Python API 4) Javascript/CSS
Challenges we ran into
Challenges included analyzing our dataset which had unnecessary information not relevant to our result and being able to convert to different extensions for different uses. In addition, we often switched between multimodal and bimodal models due to cost and efficiency. Finally, adding both the NLP model and logistic regression into a usable website
Accomplishments that we're proud of
We are proud of our successful implementation of an NLP model that utilizes prompting to give us any information related to our database. We are also proud of the flexibility Imparsonator has to adapt to different datasets as well as our several different models that are used to analyze our database.
What we learned
We learned that data processing can vary depending on what type of ML model is used as well as how the conversion of data for certain APIs. In addition, we learned different prompt techniques for the best result in both SQL and GPT.
What's next for Imparsonator
1) Implementation of OpenAI: We hope to have better categorization of our data to accomplish smoother prompting and opportunity for more predictive analysis. 2) Machine learning: We wish to implement the KNN (K cluster nearest neighbor) for the multimodal regression of the data which will allow us to make college student predictions on students not 3) Website development: Finally, we would like to increase the usability of the user experience by adding more features including the ability to analyze other datasets and give better visuals that directly relate to the user's prompting.
Built With
- bootstrap
- dotenv
- gpt
- html
- logistic
- machine-learning
- python
- sqlite


Log in or sign up for Devpost to join the conversation.