-
-
Poster
CYu Later Amazon Rater
Members
- Suraj Zaveri (szaveri3)
- Naafiyan Ahmed (nahmed21)
- Carmen Yu (cyu63)
Introduction
Sentiment analysis is the use of natural language processing and text analysis to identify information about the writer’s attitude toward a certain product (positive, negative, or neutral). The paper we are implementing aims to study the relationship between Amazon product reviews and the corresponding ratings given to the products by customers. A model that understands such a correlation can yield insight into word connotations, proving to be useful to both the company as well as computational linguists.
The CYu Later Amazon Rater is an implementation of a sentiment analysis project that utilizes text from Amazon reviews in order to predict the sentiment (positive or negative) for a given review of Amazon products. This is a binary classification task (with input review text and output rating) that we chose due to our shared interests in natural language processing as well as the insight about word connotations that such a model can uncover.
Related Work
The following Stanford Paper was the main source of inspiration for our project. In this paper, the Consumer Reviews of Amazon Products dataset is used to correlate review text and product ratings (5 classes of the ratings 1-5). As part of preprocessing this data (which had 34627 different product reviews), the paper creates a simplified dictionary of words (with the threshold being 6 occurrences of the word in the reviews) as well as a 50-d glove dictionary to represent the features. Following preprocessing, 4 different models are used to perform the classification (Naive Bayes, K-nearest neighbor, Linear Support Vector Machine, and Long Short-Term Memory). The results showed that the LSTM without the Glove dictionary resulted in the highest test accuracy (71.5%), with potential explanations being that with the Glove dictionary (which is intended to be a more robust dictionary), the model overfitted to the data (85.6% train accuracy but 65.6% test accuracy).
Similar publicly available projects for sentiment analysis of Amazon reviews (a running list): https://github.com/louiefb/amazon-reviews-nlp/blob/master/Amazon%20Reviews%20NLP.ipynb https://www.kaggle.com/muonneutrino/sentiment-analysis-with-amazon-reviews
Data
The Stanford Paper mentioned above used the Consumer Reviews of Amazon Products dataset. Our project will use the UCSD Amazon Reviews and Ratings Dataset which contains the same data but formatted slightly differently. The data is stored as a JSON which will help when parsing through the data during the pre-processing phase. We will be looking at the “reviewText” and “overall” fields which contain data on the user text reviews and the actual numeric ratings respectively.
Methodology
Preprocessing:
We will use the Python JSON library to parse through the JSON data and build a list of input sentences and labels. We will also split the dataset into training and testing set.
Model:
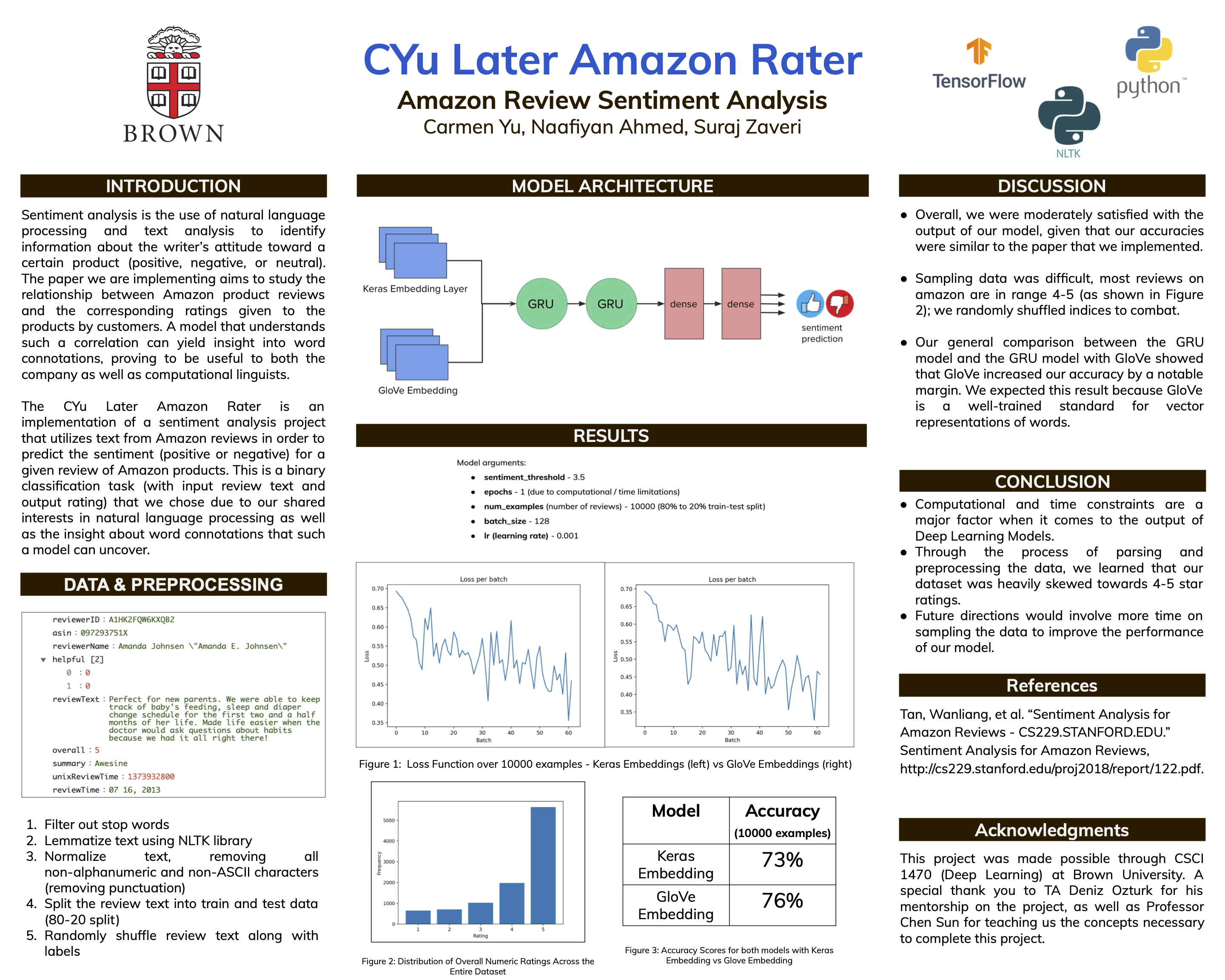
We plan on using a RNN model. The architecture of the model will be as follows:
- Initial Embedding Layer - The inputs were the tokenized review texts. We used both Keras Embeddings and GloVe Embeddings and compared the results of model
- 2 GRU Layers
- 2 Dense layers: ReLU and Sigmoid activations respectively
- Final output from the 2nd Dense layer is a single value in [0, 1] where 0 represents negative sentiment and 1 represents positive sentiment
We trained the model for 1 epoch due to computational and time constraints.
Metrics
Accuracy in this project will be measured by whether the model was able to correctly determine positive or negative sentiment. Positive sentiment is defined as a rating that is greater than a sentiment threshold and negative sentiment is defined as a rating that is less than or equal to sentiment threshold.
We compared the results of our word embeddings against the GLoVE word embeddings. We initially wanted to compare it to other embeddings but were unable to due to computational and time constraints
Ethics
What broader societal issues are relevant to your chosen problem space?
By generating and providing analysis on user data (and more specifically, underlying intentions and reactions to products), sentiment analysis can be a powerful tool for businesses to refine marketing strategies and to improve customer experience in general. Beyond the commercial realm, however, it can be broadly applied to any cause or organization that relates to public sentiment and attitude (e.g. using online comments and posts to gauge electoral outcomes for the future or gain insight on political polarization).
Due to the nature of sentiment analysis and mass data collection, it could potentially be associated with existing controversies on big data mining and privacy concerns. There are also limitations to sentiment analysis — such as detecting more subtle contextual cues like sarcasm or exaggeration — that can ultimately skew results.
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain?
Our data will be extracted from a more narrow subset of UCSD’s Amazon Product Dataset, which (as a whole) contains 142.8 million product reviews and general metadata from Amazon. While the method of data collection is fairly straightforward given that product reviews are made publicly available, one possible concern might be the timeframe of the reviews, spanning May 1996 - July 2014.
Furthermore, underlying biases may stem from:
- response bias — consumers with more extreme opinions may feel more inclined to post either overwhelming positive or overwhelmingly negative reviews. In other words, the sentiments and opinions associated with 1-star and 5-star reviews may be overrepresented compared to more neutral reviews;
- brands artificially inflating product ratings by offering consumers refunds or discounts in exchange for positive reviews.
Division of Labor
- Suraj - Preprocessing, GloVe Embedding implementation, Model Architecture Diagram
- Naafiyan - Preprocessing, Model, Train/Test, QoL features such as CLI arguments
- Carmen - Preprocessing, Visualizing Data, Model Analysis, Ethical Considerations, Presentation
Acknowledgements
This project was made possible through CSCI 1470 (Deep Learning) at Brown University. A special thank you to TA Deniz Ozturk for his mentorship on the project, as well as Professor Chen Sun for teaching us the concepts necessary to complete this project.
Documents
Built With
- glove
- keras
- matplotlib
- natural-language-processing
- numpy
- python
- tensorflow




Log in or sign up for Devpost to join the conversation.