-
-

Home Page
-
Audio Interface
-

Triple Ensemble Network Scheme
-

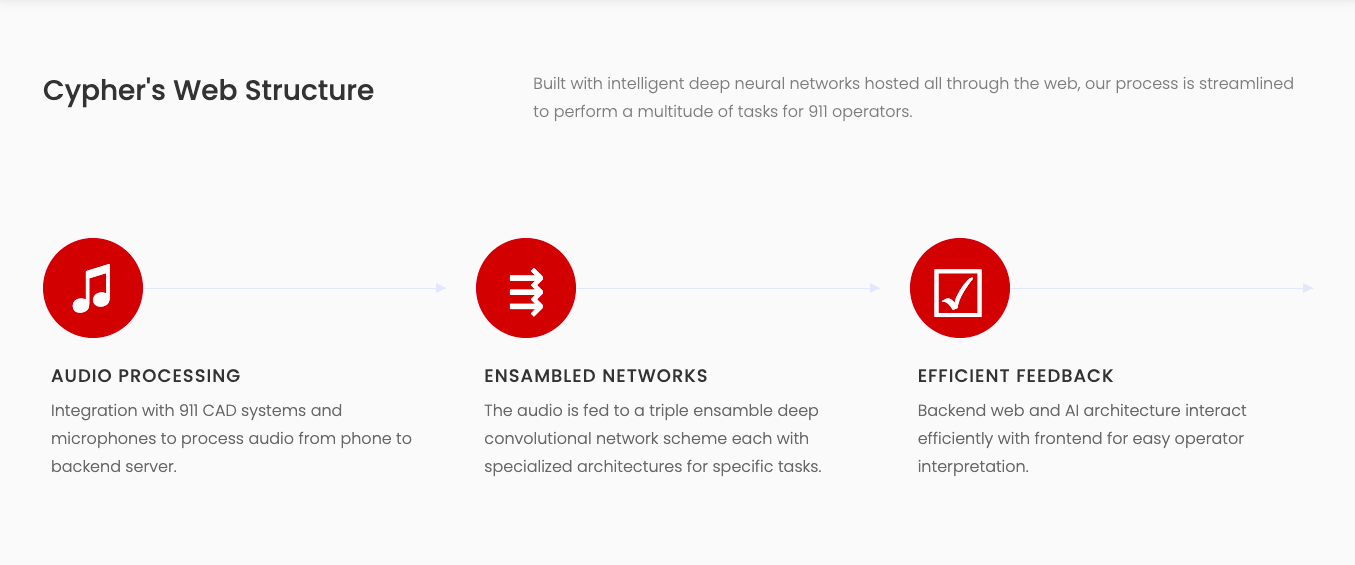
Cypher's Web Structure
-

Audio Classification Documentation
-

Audio Enhancement and Reconstruction Documentation

App Demo Only Video (No Voiceover): https://youtu.be/SjQM5Dkm7GE
Inspiration
Influenced by the difficulties that 911 dispatchers face on a daily basis with the growing prevalence of crime nationwide, our team has reflected on how we can assist these dispatchers to increase their efficiency and improve the resources they have at their disposal while they are communicating with distressed callers. Failed 911 responses are most notable in domestic violence cases, especially because domestic violence victims are an underrepresented group with few advocacy groups.
The importance of addressing this issue was brought to light to our team due to the rising problem of domestic violence in the United States. In 2020 alone, 10 million Americans experienced some form of domestic abuse, and many of these victims are isolated from support agencies. Often victims of domestic violence feel trapped by their abusers because their partners restrict and control them, making it impossible for them to seek significant help from the police or other protection services. Thus, many victims try to secretly call the police while using coded words and masked phrases. The infamous example is where victims repeatedly say “Can I order a pizza” in order to get the attention of the dispatcher. However, it is often very difficult to distinguish between prank calls and legitimate requests as over 70% of 911 calls are either accidental or prank calls, meaning victims don’t receive the help they need. The anxious and frightened tone conveyed by victims is confusing for dispatchers who have to multi-task and deal with many other operations at once.
In researching more about the 911 dispatcher process, we found that often in calls there are many cues provided through background audio such as faint gunshots, screaming, or glass breaking that the caller may not be able to convey due to their situation and that the dispatcher may not be able to notice because of how many tasks they have. Therefore, these cues go unnoticed, preventing an effective response. Even more concerning is situations where the caller audio is either faint, muffled, or poorly connected, which prevents proper communication. If audio could be enhanced and cleaned, this would significantly improve communication. These are fundamental problems with audio communication that can influence life or death situations.
Thus, we took a unique approach from the common hackathon project. Instead of creating an application meant for general use, we developed an application specifically for city governments. Assisting 911 operators has a very large impact on reducing domestic violence and can positively influence a critical part of our government. Since governments often utilize outside developers to build applications, we believe our website fills a normally unoccupied niche, and projects like this should be encouraged in the hackathon community.
Thus, we developed Cypher, an application that uses AI to streamline 911 calls for dispatchers to process and analyze audio.
What it does
Cypher is a unique progressive web application that assists 911 operators to perform their tasks more effectively by using audio processing neural networks. We specifically aim to solve 3 critical issues 911 operators face. Our dispatcher page has an interface where the 911 operator will play the caller audio. 911 operators use CAD, or Computer Aided Dispatch systems, which essentially take in the caller audio and play it to the dispatcher along with other information such as location. After researching, we have developed our model and server so that they can easily be integrated with a CAD system. We would work with governments to install our models into their systems so that any incoming audio would be processed by our neural networks.
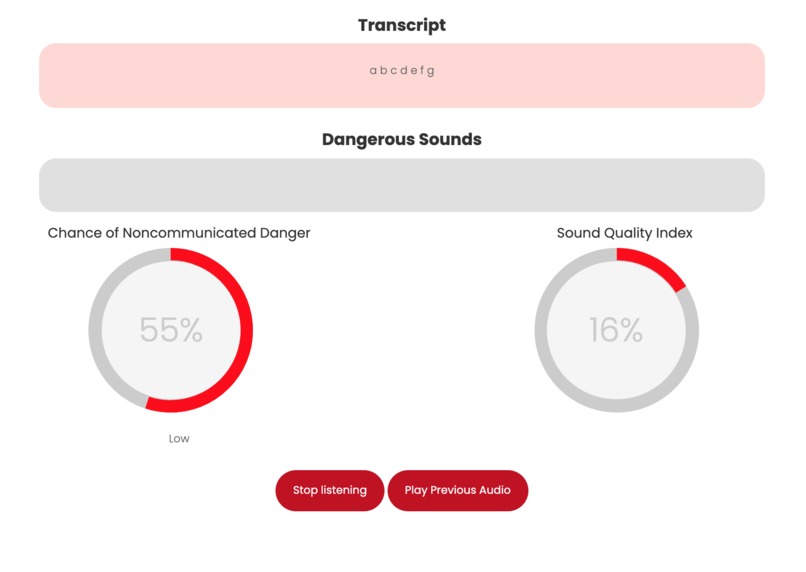
To identify and decode non-communicated cues victims use to communicate with 911 operators, we use deep convolutional neural networks for audio classification. We train our model on a tone detection dataset to identify anxious and frightened tones. On the interface, we display a danger rating percentage as well as a result of whether the caller is in immediate danger or not. Our neural network inputs the audio from the microphone, processes it, and then passes it to the model for an output. This allows 911 operators to exactly determine whether or not the caller is in immediate danger, helping them decide how to respond to and communicate with the caller. This would especially help domestic violence victims who can’t verbally communicate their distress.
Moreover, we detect dangerous sounds that may be faint or unnoticed by the dispatcher. This uses the same CNN architecture as the last model but is trained on an ImageNet style dataset for sound and fine-tuned on a separate dataset of dangerous sounds. The model can identify sounds such as gunshots, breaking glass, screaming, and more. The inputted audio from the microphone is passed to the model, and the model displays any dangerous sounds as soon as they are detected, and it works most effectively when the sounds are muffled or not directly heard by the operator.
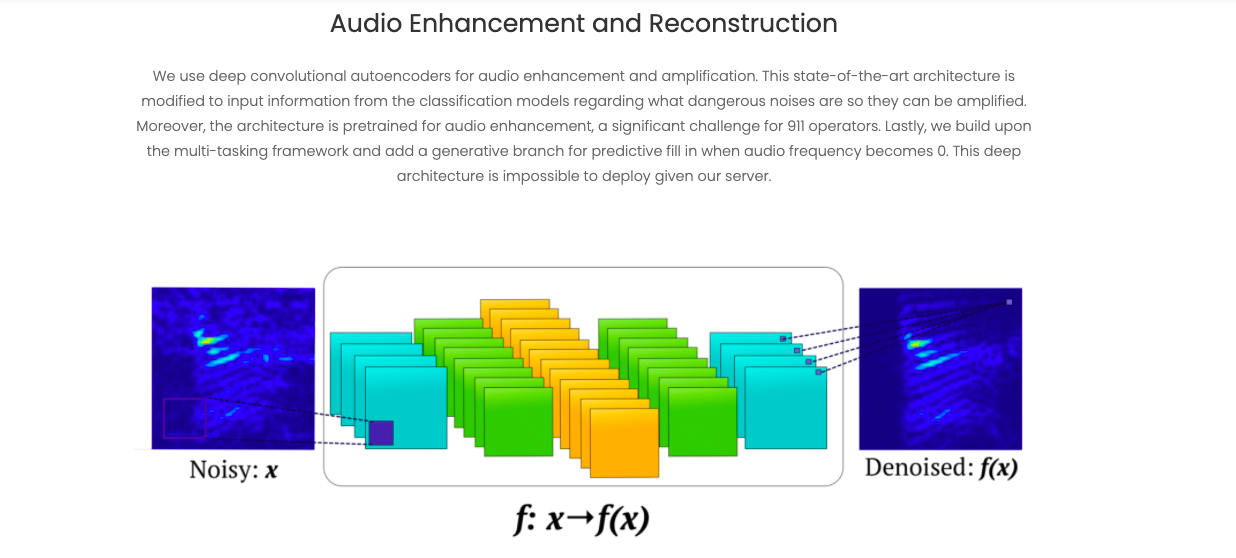
Finally, we use a denoising autoencoder to enhance any faint or choppy audio. Often when communicating with callers, their connection is poor and the audio quality is low, and without it being enhanced, dispatchers cannot properly help callers. Our algorithm inputs the audio and first assesses the audio quality on an index percentage. Every 5 seconds of audio is clipped and processed through the model. The model reconstructs a clean version for all audio samples, and if the index for that sample is below 25%, we display a button allowing the operator to listen to the enhanced version of the audio.
The Tech

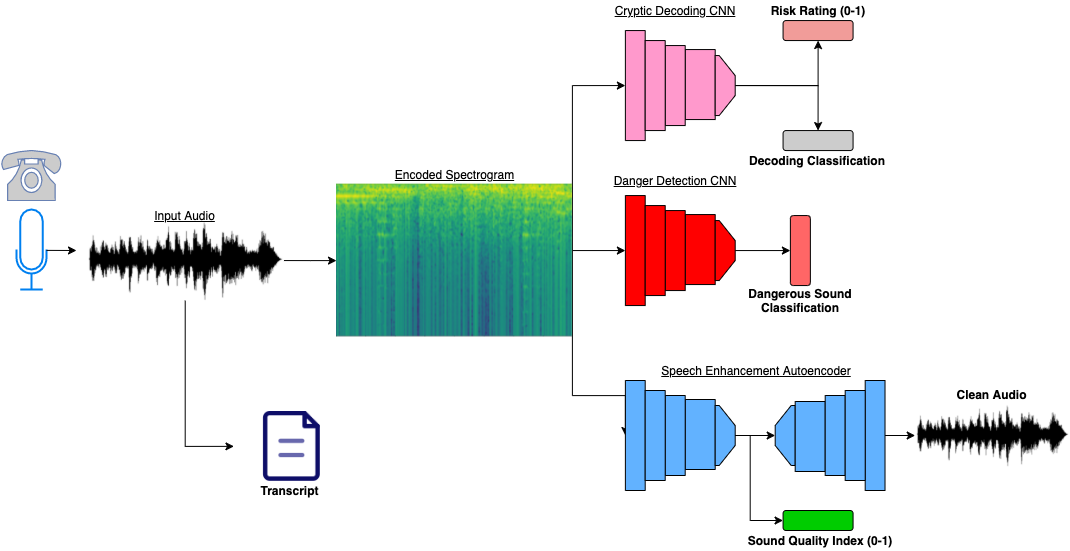
Our AI architecture involves a triple ensemble of neural networks. Two of the networks are classification CNNs which output numerical predictions, and the third network is an audio denoising autoencoder that inputs noisy samples and predicts clean ones.
Our web architecture begins by processing the inputted audio from the microphone into an encoded spectrogram representation. The audio files are saved as .mp3 files from the microphone and then processed using Keras and NumPy into encoded representations. Each representation is then passed to each of the 3 networks. Our scheme uses warm-started data, which means the data comes in separate pieces, so we have to clip each file after 5 seconds to process it.
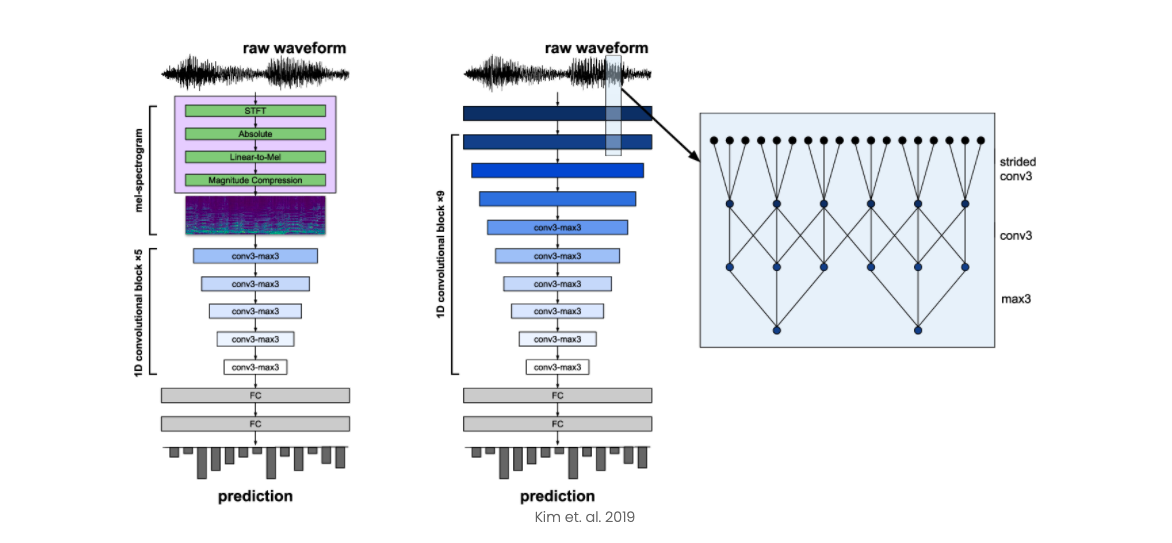
The first networks are standard audio convolutional neural networks. The encoded representations have the features extracted using a state-of-the-art network called VGGish inspired by the popular VGG architecture. We replace the final layers for each network so we can receive the predictions for each dataset. For the CNN which decodes non-communicated messages from domestic abuse victims, we have two final layers of outputs: a rating from 0-1 as well as a prediction on how serious that danger is, such as if it was immediate. The second network which detects dangerous sounds simply outputs a 5-class danger rating, including gunshots, breaking glass, screaming, and or none. The first network is pre-trained on a tone detection dataset and fine-tuned on a 911 transcript dataset so that the model can learn representations specific to 911 calls. The second network is pre-trained on an ImageNet style dataset of thousands of different sounds. We then fine-tune this network on a dangerous sound dataset which includes the 5 classes of dangerous sounds. These networks are trained with the audio files as inputs and the classifications as the labels.
The third network is different because it is an autoencoder that outputs a clean audio file. An autoencoder works by inputting an audio sample, downsampling the sample into the latent representation, learning efficient representations of that data in the bottleneck, and then reconstructing it into an audio sample that is the same size as the one that was inputted. The downsampling process is done by the encoder module, and the upsampling process is done by the decoder module. For our autoencoder, we add a separate branch from the bottleneck (where the encoder and decoder connect) that predicts the sound quality of the audio sample. We used an average pooling layer followed by a single dense layer to assess the audio quality. Our autoencoder is a state-of-the-art denoising autoencoder that is trained on a large-scale dataset of noisy (which means unclean) and clean audio files. To train this network, the noisy samples are used as inputs, and the model learns how to remove the noise from a sample and enhance the quality of that audio sample. Regardless of the audio quality, all samples are reconstructed into an enhanced version.
All of these networks were built using Keras and Tensorflow implementations and trained using an NVIDIA K80 GPU.
How we built it
After numerous hours of wireframing, conceptualizing key features, and outlining tasks, we divided the challenge amongst ourselves by assigning Ishaan to developing the UI/UX, Adithya to working on data processing and frontend, Ayaan to developing our audio classifiers and autoencoders, and Viraaj to building the backend framework for our networks.
We coded the entire app in 4 languages/frameworks: HTML, CSS, Javascript, and Python(Python3 /iPython). We deployed part of our models with Flask as our backend framework and built our models with Tensorflow and Keras. We used Linde Cloud and Google Cloud Platform for training our algorithm. We used Google Cloud and PythonAnywhere for our backend. We hosted our website through Netlify and Github.
We collected data for our networks using open-source datasets of tone detection datasets, dangerous sound datasets, and 911 transcript datasets. We used state-of-the-art audio classification network architectures from researchers at Google and other institutions. Our audio enhancement algorithm was pre-trained on a large-scale noisy audio dataset. However, since we don’t have access to a cloud GPU, we were unable to entirely deploy our network ensemble.
Challenges we ran into
The primary challenge that we ran into was developing our ensemble of networks. Since each of these networks required a separate dataset and needed to be slightly adjusted to meet our needs, training these models was also a huge challenge because audio files are large in size. While we were not able to fully deploy our full models, as they are too large to deploy on free and available servers, we have developed a plan to integrate them with 911 CAD systems if possible.
In addition, many of these technologies were brand-new to us. We have not used advanced AI/ML on this level in the past, and learning how to develop these models was a giant hurdle we needed to overcome. In addition, we spend hours learning how to use new frameworks such as Google Cloud Platform and Linode Cloud for training our large models.
Accomplishments we are proud of
We are incredibly proud of how our team found a distinctive yet viable solution to improving 911 responses and assisting domestic violence victims. We are proud that we were able to develop some of our most advanced models so far. We are extremely proud of developing a solution that hasn't been implemented in this setting. Most importantly, we were able to achieve our goals for the weekend by completely finishing our app, which we are very happy with.
What we learned
Our team found it incredibly fulfilling to use our AI knowledge in a way that could effectively assist 911 operators in responding to 911 calls from vulnerable victims, such as domestic abuse victims. We are proud that we were able to raise awareness about and address a serious issue about domestic violence through an innovative solution that aims to protect victims. Seeing how we could use our software engineering skills to impact people’s daily lives and bring attention to a serious issue in our society was the highlight of our weekend.
From a software perspective, developing audio processing neural networks was our main focus this weekend. We learned how to effectively build audio-based CNNs and autoencoders as well as how to pre-process audio files into numerical encodings. We learned how to use great frameworks for ML such as Google Cloud Platform and Linode Cloud. We grew our web development skills and polished our data skills.
What is next for Cypher
We believe that our application would be best implemented on a city government level in partnership with 911 operators and domestic abuse organizations. We specifically want to decrease domestic violence, which has increased during the pandemic, so working with organizations would be our next step. 911 operators and government officials currently do not have a way to effectively respond to domestic violence victims and other special 911 scenarios, but with our solution, they can more properly address these life or death cases. We have already developed a plan which could integrate our AI models with 911 CAD systems that process caller location, information, and audio through the call. As the audio comes in over the phone, it would be immediately sent to our web system through the CAD operator systems and before it is played to the operator, it would enhance the audio and show the important predictions on their screen.
In terms of our application, we would love to deploy our models on the web and streamline the process of training our models and performing repeated inference with warm-started data. Given that our current situation prevents us from buying a web server capable of running all those processes at once, we look forward to acquiring a web server that can process high-level computation. Lastly, we would like to refine our algorithms to be more accurate and train with other datasets.










Log in or sign up for Devpost to join the conversation.