-
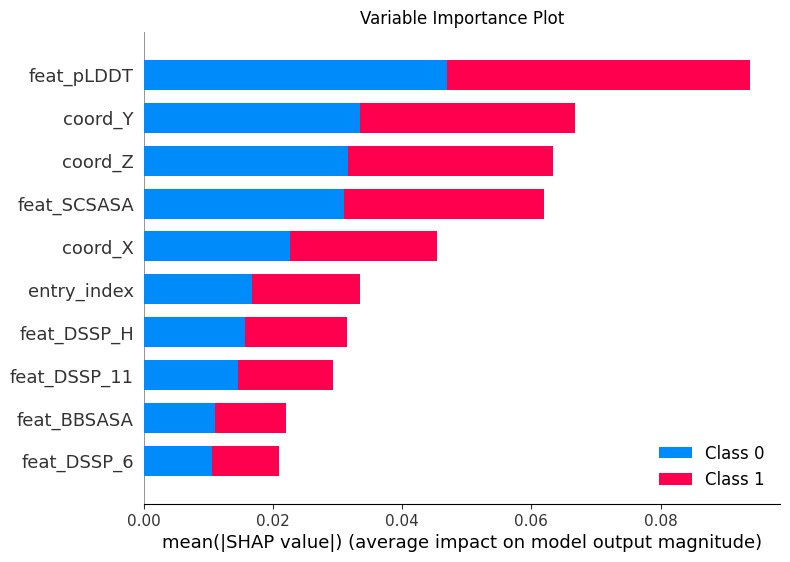
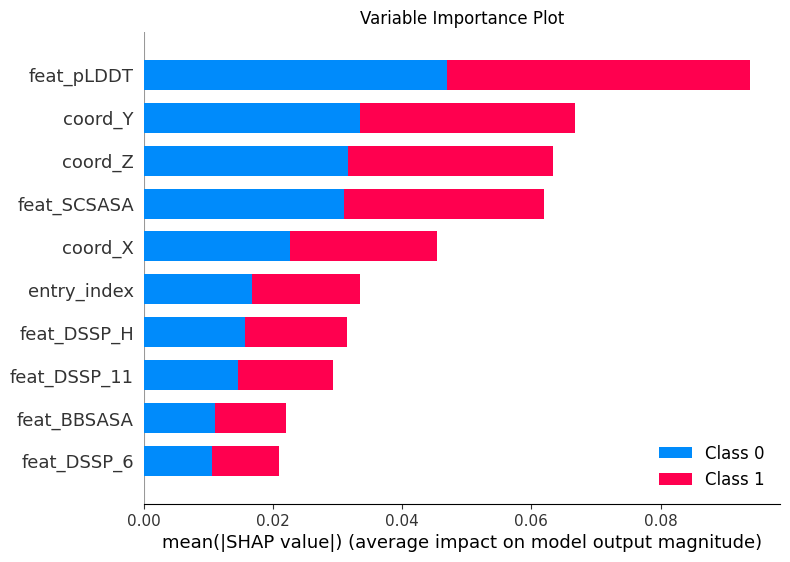
Variable Importance Plot
-
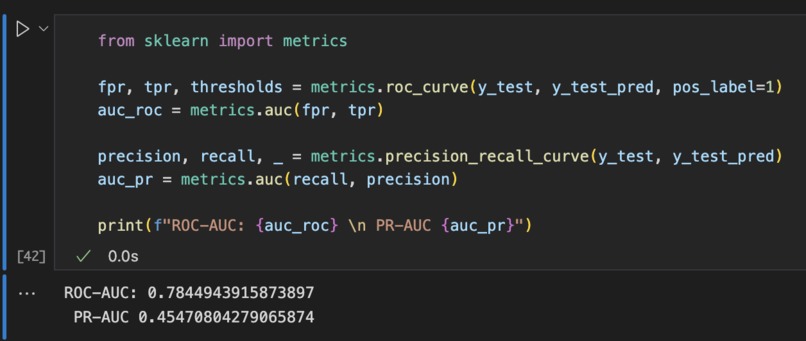
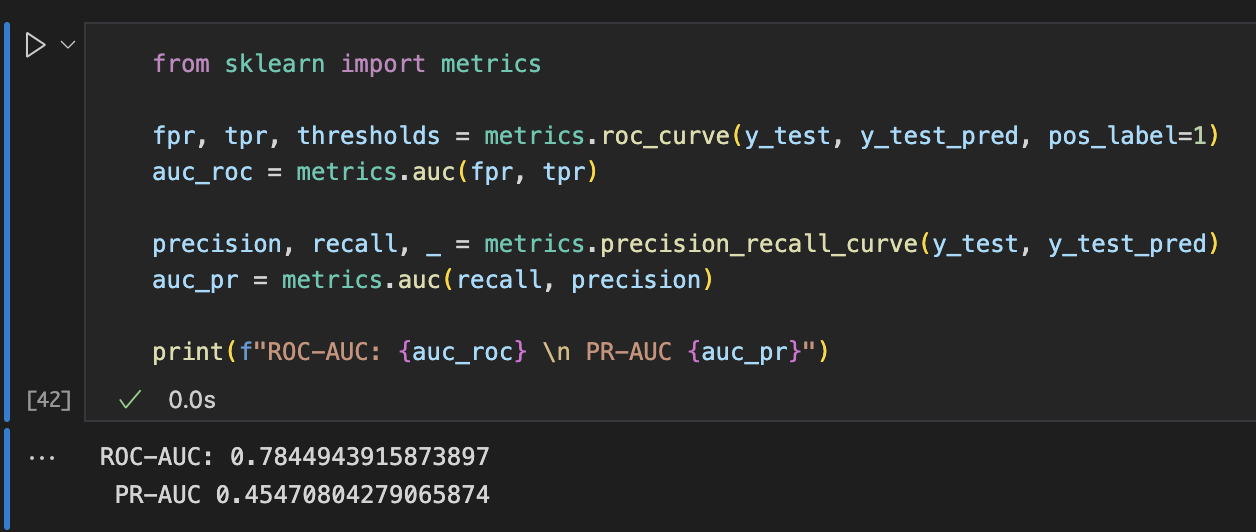
Scores
Inspiration
I joined Scotiabank's data hackathon one month ago, where we were asked to predict credit card fraud. That was my first data hackathon, which sparked my interest in machine learning. I joined the CxC data hackathon so that I could reinforce the knowledge that I have learned and explore new aspects, models and methods in machine learning.
What it does
The model predicts each protein residue as 'drug binding' or 'non-drug binding'.
How I built it
Different models such as XGboost, Logistics Regression, Random Forest, SVM, and GBT were tested before choosing a final model. Models were chosen based on the ROC-AUC and PR-AUC scores. Data normalization and cross validation was also used. SHAP is used to yield the variable importance plot.
Challenges I ran into
There is a high imbalance in the given training dataset. 479912 were False and 17254 were True. Resampling techniques are used, including oversampling, undersampling, SMOTE, and random stratified sampling. Hyper parameter tuning was used to find the best parameters for the model. The best model used the RandomForestClassifier with 400 n_estimators, 2 min_samples_split, 1 min_samples_leaf, with data normalization and undersampling.
Accomplishments that I am proud of and what I learned
This is my second data hackathon so there were lots to learn. Using the list of feedback I got from my previous data hackathon, I first focused on fixing my mistakes such as data leakage, then researched into how I could further improve my model (e.g. hyper parameter tuning). The final model has a ROC-AUC score of 0.78449 and a PR-AUC score of 0.45471.
Built With
- hyperparameter-tuning
- machine-learning
- pandas
- python
- random-forest
- resampling
- shap

Log in or sign up for Devpost to join the conversation.