-
-

Logo
-
Landing page
-
Sign up page
-
User background prompt (Powered by Typeform)
-
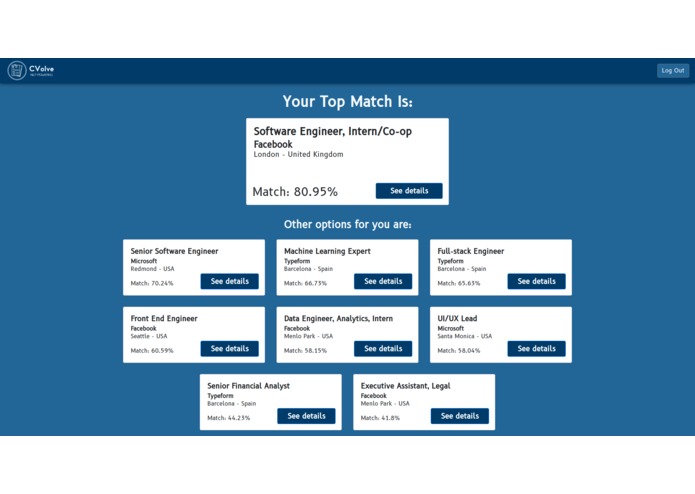
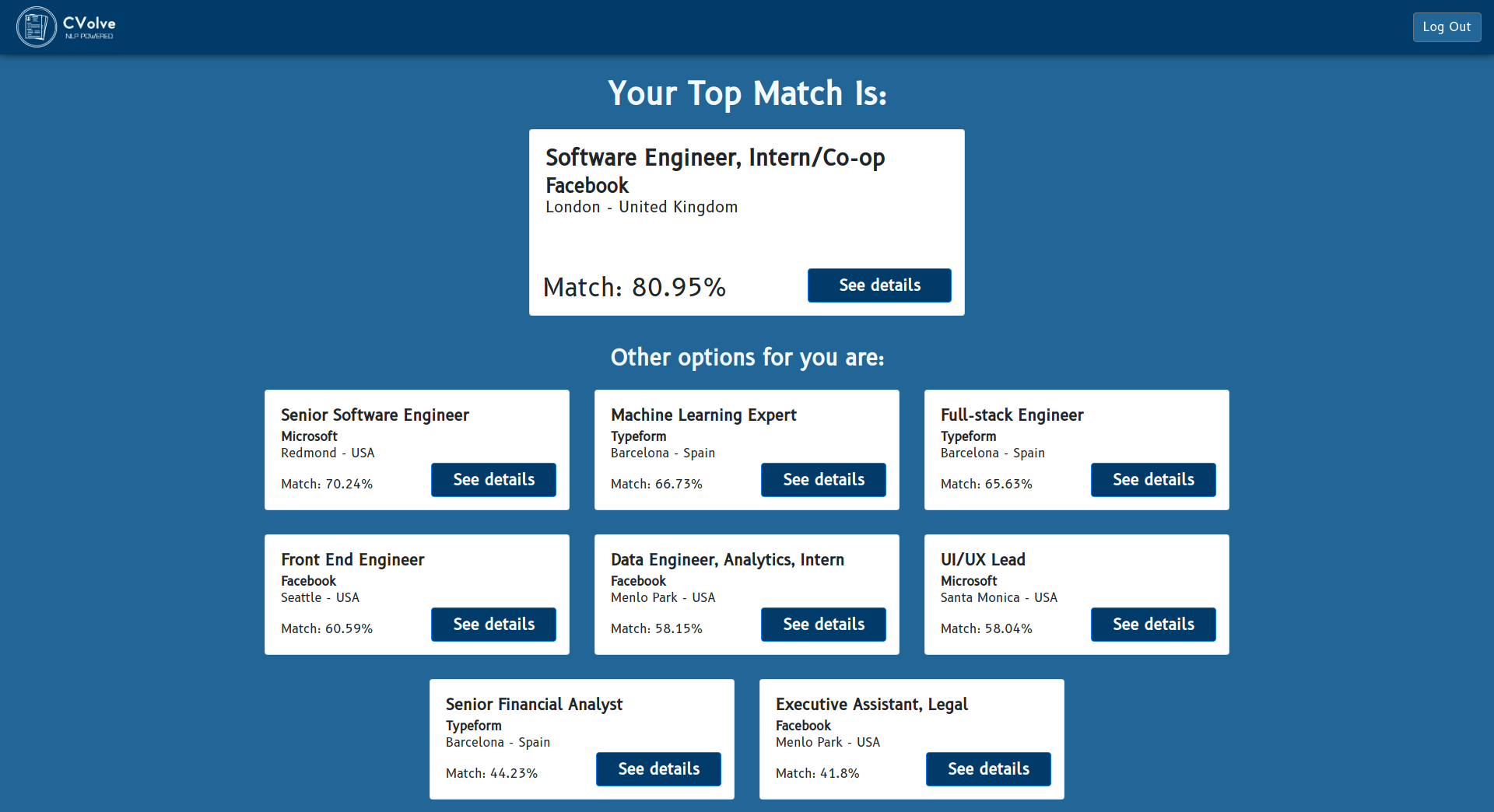
Offers view
-

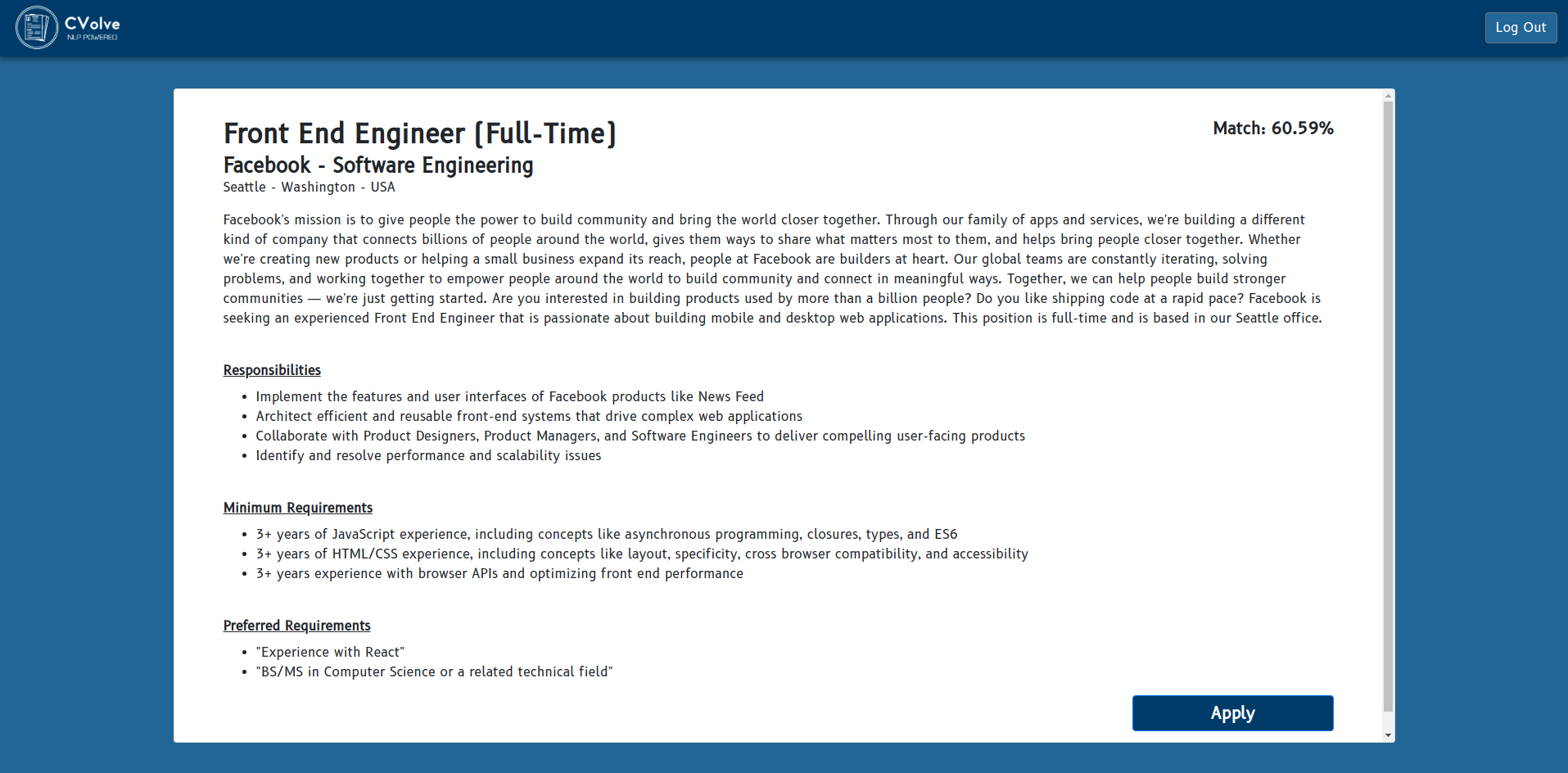
Offer detail
-

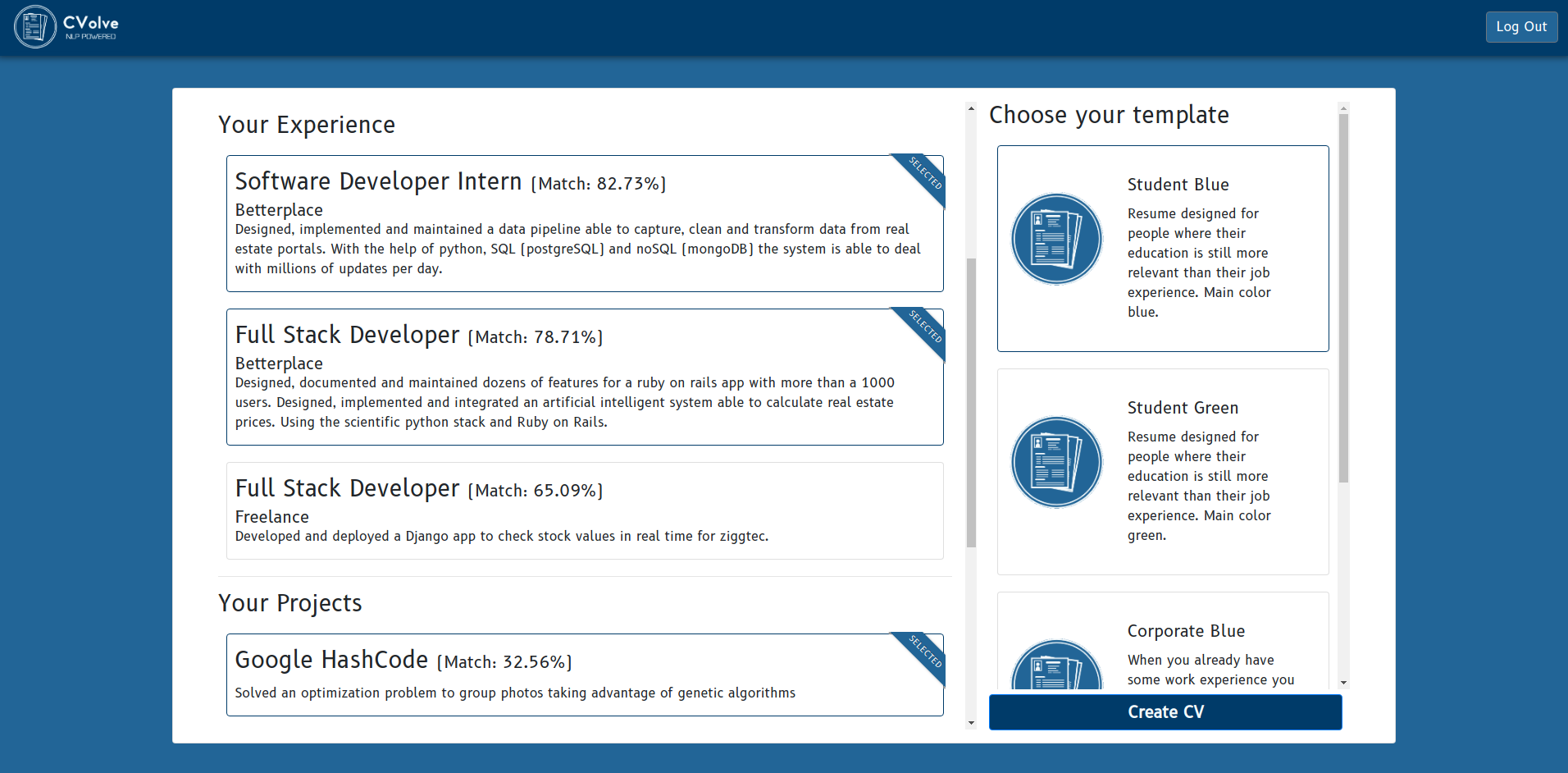
Resume preview
-
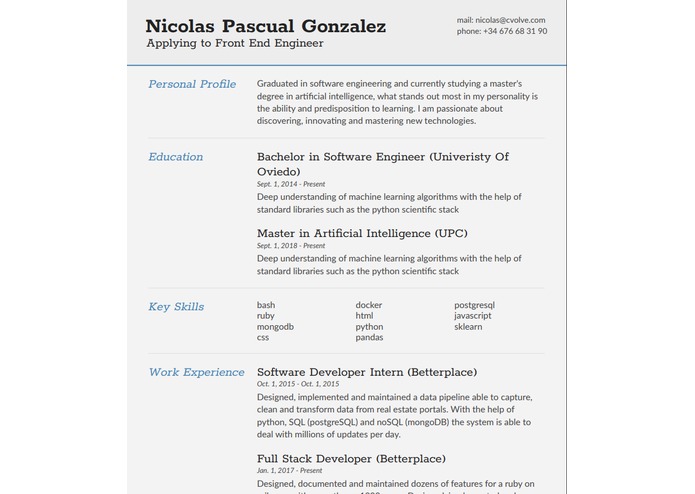
Generated resume



Inspiration
CVolve pursues the possibility to offer the users an augmented experience in the task of applying for a job. If we think on splitting the process of landing a job into smaller steps, we could find the following ones:
- Try to find job offers that fit as much as possible your expectations. If we want to find our dreamt job, it is likely that we would have to scroll down for a very long time in a given job portal reading dozens of offers to choose just a bunch of them and discarding a lot that didn't suit us at all.
- Adjust our resume to the selected offers. It is important to remark our most valuable skills taking into account the requirements of each offer. This means that we will be creating more than one CV, which means spending some time per each offer, knowing that many of them may be discarded by the recruiters, and we will just land a job, so just one resume will be worth it.
- Applying to the selected offers. Last step is the most straight forward. We just fill the form of the company, attach our resume, click on submit and wait for the (not so quick) answer. After applying, we keep doubting if the recruiter will be conformed with the content of the resume, either if we have missed something or added too much information, ...
If this process is done manually, it is easy to see that it leads to a huge waste of time for the applicant, as well as the possibility of missing good job options because of the fatigue generated by searching too much, or maybe the underestimation of the resumes by the applicants because the content could be improved, ...
We are awared of all these disadvantage, that is why we have developed CVolve.
What it does
We have focused on tackling the disadvantages shown in the previous section. The system indexes a huge set of job offers that then will be compared against the skills of the user, that will be retrieved by prompting a form to the user. Once we have the data from both sources (user data and offer details), we carry out some calculations using NLP algorithms so we can obtain the distance between the user knowledge with respect to the offer requirements. With this distance, we can determine which offers are more likely to fit the user expectations, and be able to sort all these offers and prompt to the user the ones that suit the best to him.
We consider that the step of creating and adapting a resume for each offer is the most time consuming, so CVolve offers also a solution for that. The distance we calculate is not just the global one between the offer contents and the user experience. We also calculate a relative distance for the four main field groups provided by the user:
- Skills (programming languages, libraries, frameworks, ...).
- Education.
- Work experience.
- Personal Projects (hackathons, volunteering, event organization, ...).
With all this information and regarding the offer requirements, we start generating a dynammic resume. The most important feature of this generation is that the system emphasizes on the information whose calculated distance is lower. The final layout of the CV shows several sections (contact information, education, work experience, ...) whose elements will be sorted according to their distance to the offer. In this way we increase the applicants probabilities of gaining the interest of the recruiters.
How we built it
We structured the project into 4 different parts:
NLP model
The app is powered by an NLP model based in GloVe pretrained embeddings. GloVe is an unsupervised learning algorithm for obtaining vector representations for words. We used a model pretrained with 400K words and and 6B tokens, this makes possible the comparison in narrow domains such as the technology one.
To compare the vectors produced by the embeddings we use the word moving distance which compares the vectors taking into account semantic information of the words.
The model is able to compare any type of documents making possible to analyze each of the items involved in the generation of a resume on its own. We used a python library called Gensim to manage the embeddings.
Server
The whole project was developed using Django. Taking advantage of the MTV (Model, Template and View) pattern, a variation of MVC, we have designed all the views for the system but one (that is explained in the next section). Backend and frontend were built together using Django, as the abovementioned pattern made the development task easier.
Database
For the database we are using SQLite, as we all have used it before. The main reason to choose this option, is that we are developing a MVP, so we don't have to struggle in terms of scalability or availability. Currently we are working on a small scope that does not require an extremely powerful database.
TypeForm
For the task of gathering the information from the users, we have decided to use TypeForm. In that way, we externalize the creation of a large form with user-friendly design, and retrieving the data filled by the user is made easier using WebHooks. Once the user has submitted the form, the webhook sends the results to some Django endpoint, where the data is parsed and persisted into the corresponding database table.
Challenges we ran into
During the integration process we struggled with external API usage deriving in losing a couple of hours in the development process. Integration with Typeform required using webhooks, a technology we haven't used before. Webhooks provide a mechanism where by a server-side application can notify a client-side application when a new event (that the client-side application might be interested in) has occurred on the server.
Also, the NLP model for the project generated many difficulties, as just one of the members of the team have already worked with that technologies. Not just defining the model, but the integration and retrieving the results in reasonable time took longer than expected.
Accomplishments that we're proud of
Knowing that there is an empirical study behind the selection of the resume content, gives more confidence to the user. Moreover, the user is informed about the percentage of likelihood between each offer and its profile. Also, before generating the CV, the system shows them a preview so they can decide which template to use among several from the gallery. In this way, the user knows the information he will be sending, and has the final decision whether to use our CV or another one done by him. Another good point is that, if the application wants to use a custom styling for the resume, he can still generate one from our templates and reuse the contents as they are the most accurate ones, but with his own style.
What we learned
Aside from the technologies that some of us never used before like Django or Typeform, I would like to remark that after several hackathons we have learnt how to organize a team for this kind of events. The difference lies on the way of preparing the project by the very beginning. Some weeks ago we started planning what we wanted to build for this one, deciding the main features to be implemented and which were optional, estimation of the different tasks we would have to accomplish, ... We made it different from the very beginning.
What's next for CVolve
There are many possible extensions for future development:
- Increase the scope of the system.
- New forms for different job types.
- Cover letter generation based on the requirements of the offer.
- Historical data of the resumes generated for the different offers, including application date and copy of the resume.
- Scraper to gather job offers.
- New templates for the resumes.
- Linkedin/Github integration.
- Add more fields for user information.



Log in or sign up for Devpost to join the conversation.