-
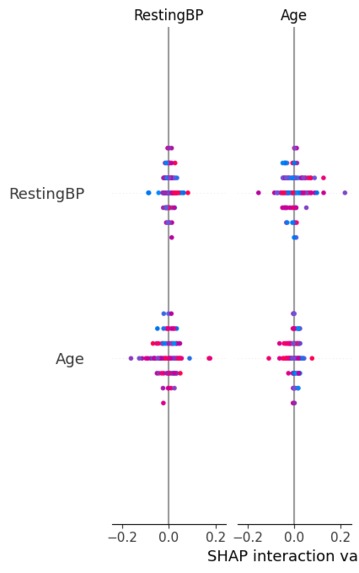
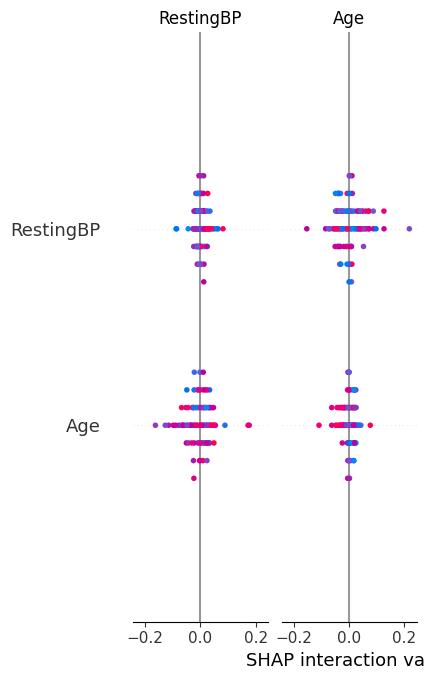
SHAP-based feature importance showing how clinical variables contribute to cardiovascular disease risk.
-
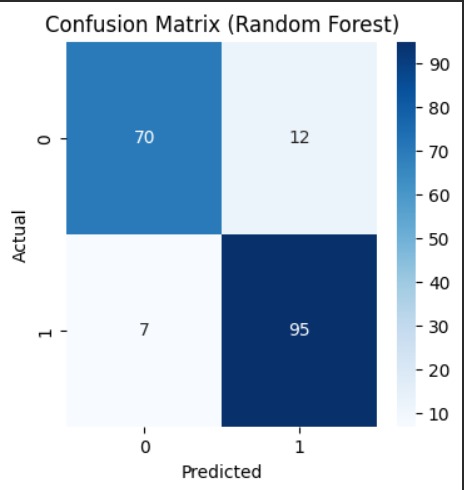
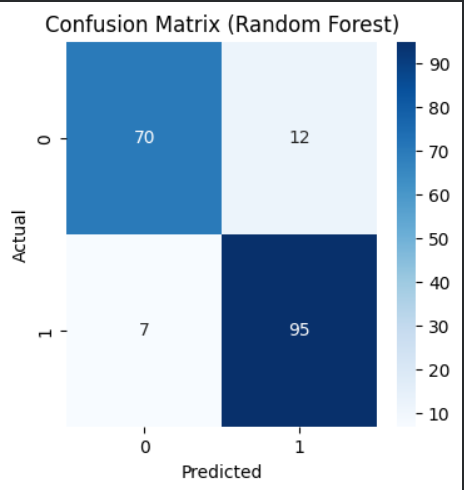
Confusion matrix of the Random Forest model highlighting accurate identification of high-risk patients.
-
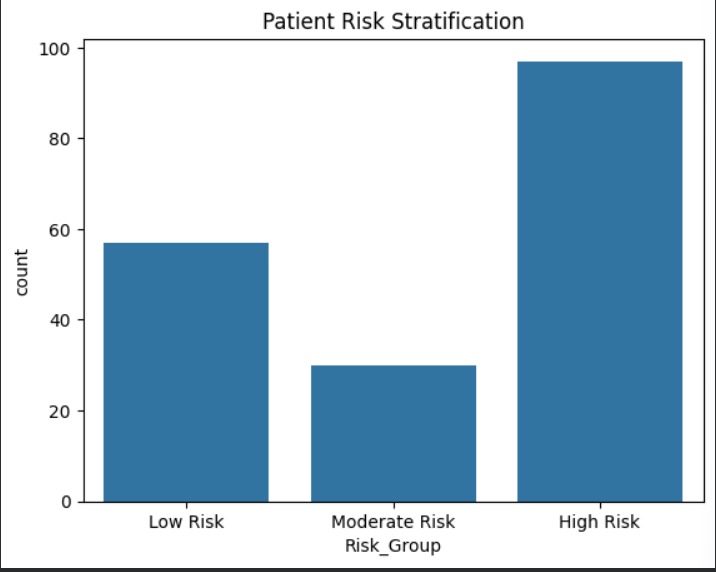
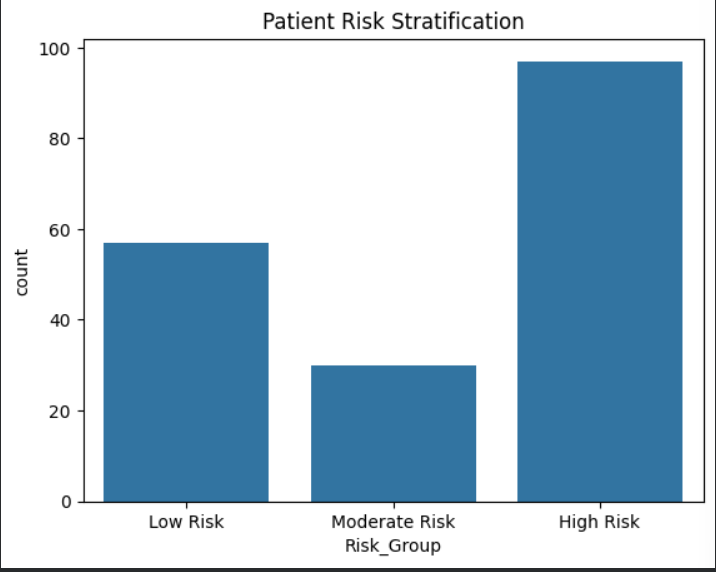
Clinical risk stratification of patients into low, moderate, and high cardiovascular disease risk groups based on predicted probabilities.
Inspiration
Cardiovascular disease remains the leading cause of death globally. Early identification of high-risk individuals can enable timely preventive care and reduce avoidable complications. While machine learning models have shown promise in disease prediction, their lack of interpretability often limits adoption in clinical settings. This project was inspired by the need for transparent, clinically meaningful machine learning systems that support—not replace—medical decision-making.
What it does
This project builds an interpretable machine learning system that predicts and stratifies cardiovascular disease risk using routinely collected clinical features. In addition to predicting disease presence, the system converts predicted probabilities into clinically actionable risk categories (low, moderate, and high risk), enabling patient prioritization for early intervention .
How we built it
We used a de-identified cardiovascular dataset containing demographic, physiological, and electrocardiographic features. After exploratory data analysis, two models were trained:
- Logistic Regression as a transparent baseline model
- Random Forest as an advanced non-linear model Model performance was evaluated using accuracy, ROC-AUC, and recall, with emphasis on minimizing false negatives. To ensure interpretability, we used feature importance analysis and SHAP (SHapley Additive exPlanations) to explain both global and individual predictions. Finally, predicted probabilities were translated into clinically meaningful risk strata.
Challenges we ran into
Building an interpretable healthcare model required balancing predictive performance with transparency. One key challenge was ensuring model explainability without introducing unnecessary complexity. We also encountered technical issues when generating SHAP explanations due to library version differences, which required careful handling of output formats and feature alignment. Additionally, prioritizing recall for high-risk patients while maintaining overall performance was an important design consideration.
Accomplishments that we're proud of
We successfully developed an end-to-end, interpretable machine learning pipeline for cardiovascular disease risk prediction. The final model achieved strong discriminative performance while maintaining high recall for patients with heart disease. Most importantly, we translated model outputs into clinically meaningful risk categories and provided transparent explanations using SHAP, aligning predictions with established medical knowledge.
What we learned
hrough this project, we learned the importance of interpretability in healthcare machine learning and how explainable models build trust and usability. We gained hands-on experience with model evaluation in a clinical context, where minimizing false negatives is critical. We also learned how to communicate machine learning results in a medically meaningful way, bridging the gap between data science and real-world healthcare applications.
What's next for CVD Risk Prediction (Interpretable ML)
Future work includes validating the model on external and more diverse datasets, incorporating longitudinal health data to predict disease progression, and evaluating fairness across demographic subgroups. We also plan to explore deployment as a lightweight clinical decision-support tool for primary care and community health screening, ensuring ethical and responsible use alongside clinical judgment.
Built With
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- seaborn
- shap

Log in or sign up for Devpost to join the conversation.