-
-
UI
-
Analyzing resume
Inspiration
Traditional hiring pipelines are bottlenecked by manual resume screening, which often consumes hours of a recruiter's time and can introduce unconscious bias. We wanted to build a tool that acts as an instant, intelligent HR assistant—empowering technical recruiters to instantly bridge the gap between complex candidate histories and rigid job descriptions. Seeing how fast and accurately generative AI can evaluate structured datasets inspired us to create a rapid, automated screening engine.
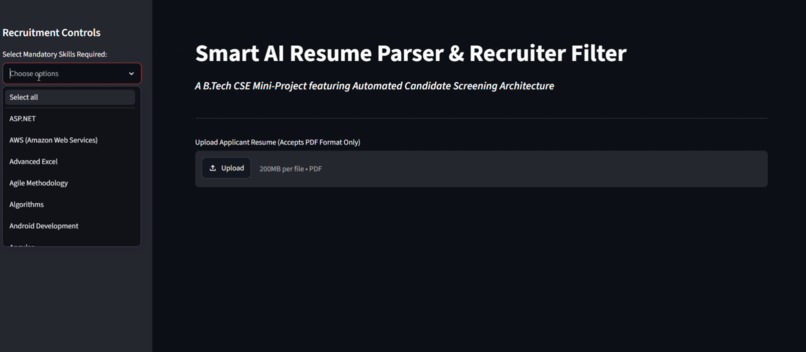
What it does
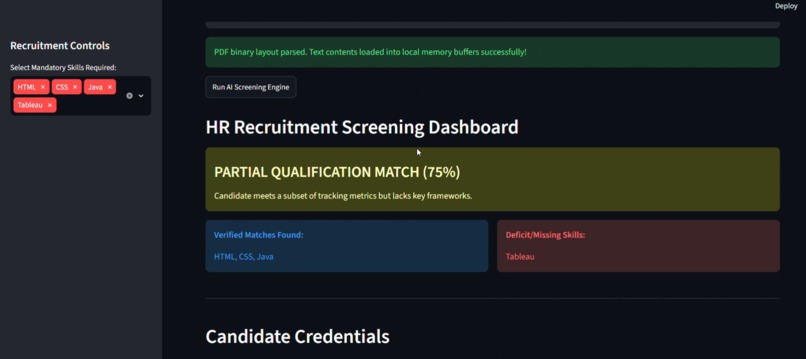
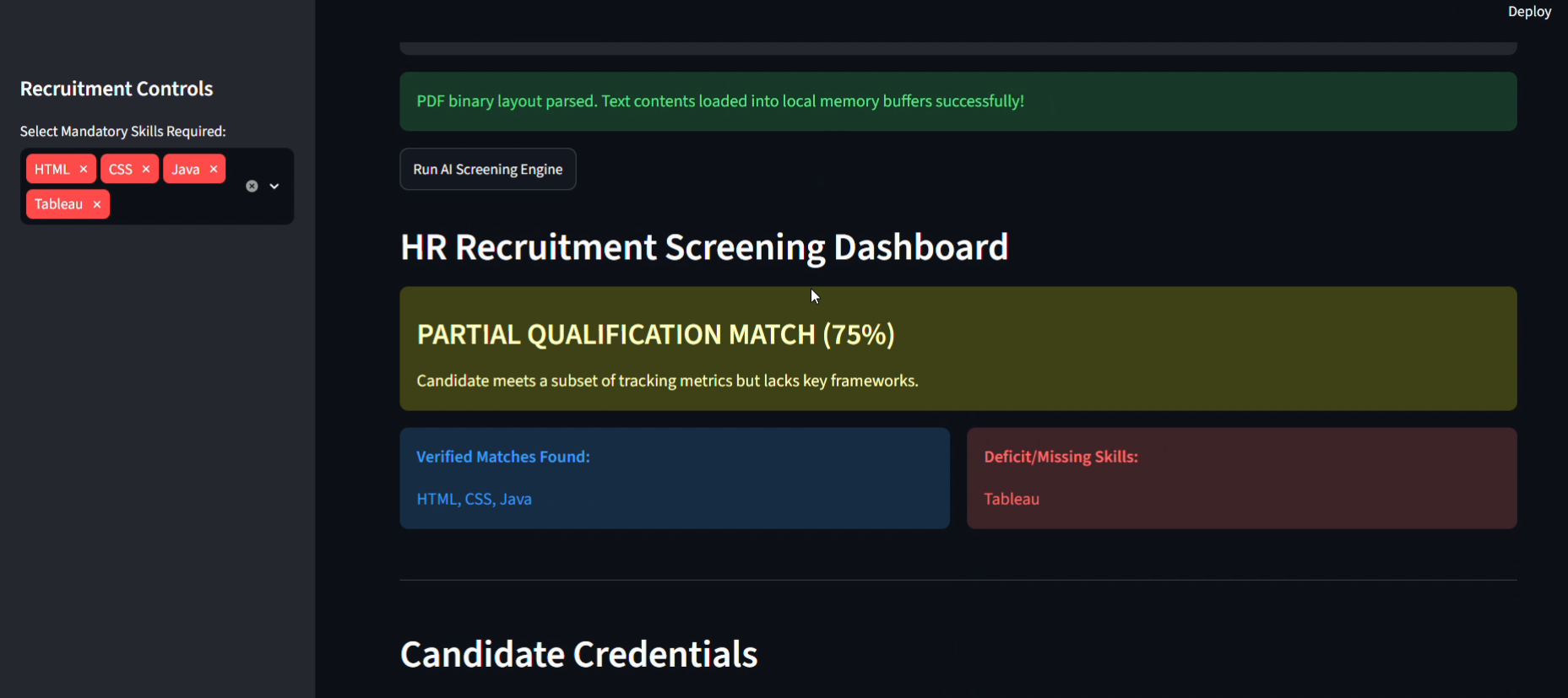
Resume Parser AI completely automates the initial candidate vetting phase. Users upload a raw candidate resume (PDF format) and paste a specific Job Description. The platform instantly performs a deep-text extraction, maps out a structured candidate profile, and conducts a matching analysis. It calculates an immediate match score, breaks down aligned vs. missing critical technical skills, and generates a definitive recruiter summary complete with concrete strengths, potential concerns, and a hiring verdict (e.g., "Strong Hire").
How we built it
The core engine is built using Python, leveraging the pypdf library for ultra-fast document text extraction. The raw text pipeline connects directly to the state-of-the-art Gemini API via the Google GenAI framework. By leveraging structured Pydantic schemas and precise system prompting, we forced the LLM to return strict, predictable JSON objects representing the profile and analysis fields. To create a seamless user interaction flow, we implemented a Streamlit frontend dashboard that lets users upload documents and view formatted analytics cards dynamically.
Challenges we ran into
One of our biggest hurdles was overcoming environmental package dependency shifts during a high-stakes, time-sensitive coding window. Migrating our JSON schema logic dynamically to adapt to strict API formats required quick pivot strategies and aggressive debugging. Additionally, ensuring that free-form, unformatted PDF data could reliably map onto uniform JSON schemas without losing key project details required precise prompt tuning and lowering model temperature for optimal consistency.
Accomplishments that we're proud of
We are incredibly proud of shipping a completely end-to-end operational backend pipeline under intense crunch time. Going from raw script concept to a fully realized JSON-rendering engine that correctly evaluates, scores, and lists specific skill mismatches dynamically felt like a massive win.
What we learned
We learned an immense amount about the power of Structured JSON outputs in generative AI workflows. Relying on traditional string matching or regex for parsing is fragile; letting an LLM parse data into deterministic schemas changes the game for data reliability. We also learned how to aggressively debug development environments and stay calm under tight submission deadlines.
What's next for CV analyzer
Moving forward, we want to scale this into a full multi-candidate comparison matrix dashboard, allowing recruiters to upload bulk ZIP folders of resumes and see an automated stack-ranked leaderboard. We also plan to integrate semantic vector embeddings to calculate match scores based on project context rather than just keyword presence, along with adding automated interview question generation based on the candidate's detected "Concerns" block.

Log in or sign up for Devpost to join the conversation.