Write about the project ChatGPT said: ChatGPT Inspiration The inspiration behind this project comes from the growing need for businesses to understand their customer base better and provide personalized experiences. Traditional methods of analyzing customers often fail to uncover hidden patterns or segments within the data. By leveraging machine learning, particularly clustering techniques, businesses can more effectively identify distinct groups of customers with similar behaviors and preferences. This project aims to help companies target marketing strategies more efficiently, improve customer satisfaction, and boost sales by tailoring products and services to different customer segments.
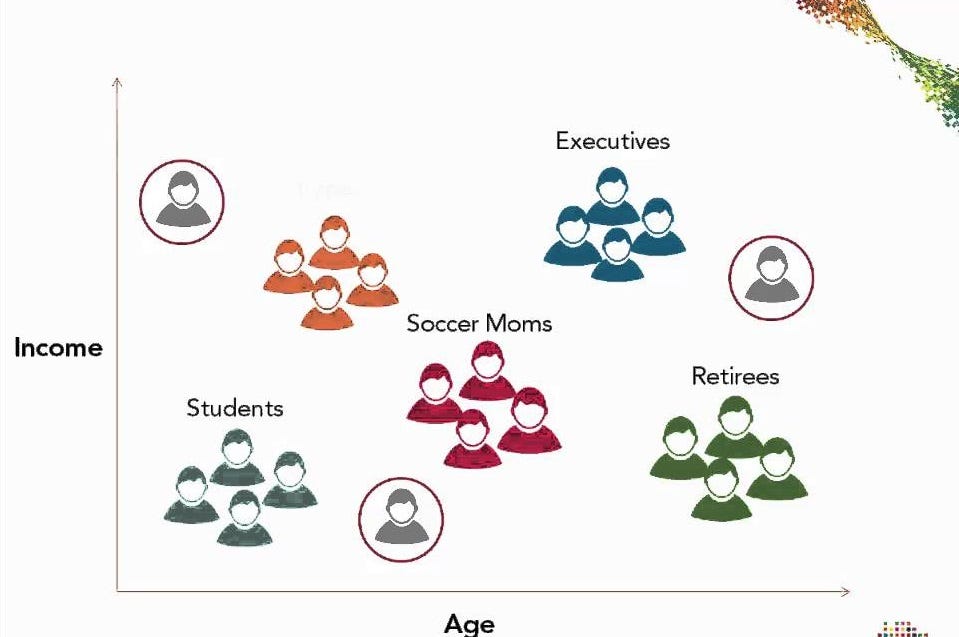
What it does This project utilizes K-means clustering to segment customers based on their purchasing behavior, demographics, or interaction with a product or service. The algorithm identifies natural groupings of customers within a dataset, providing businesses with insights into various customer profiles. These profiles can then be used to:
Develop targeted marketing campaigns. Create personalized product recommendations. Improve customer retention strategies. Enhance overall customer experience by offering more relevant services. How we built it Data Collection: The first step was to gather a comprehensive dataset containing relevant customer information such as age, gender, location, spending habits, and purchase frequency. We used Kaggle’s e-commerce customer segmentation dataset for this purpose, which provided a rich source of structured data.
Data Preprocessing: Data preprocessing involved cleaning the dataset by handling missing values, encoding categorical variables, and scaling the data using techniques like StandardScaler to ensure uniformity across all features. This step was crucial for optimizing the performance of the K-means algorithm.
Feature Selection: We carefully selected the most relevant features for clustering. These included demographic features (like age and location) and behavioral features (such as frequency of purchases and total spending).
K-means Clustering: The core of the project was implementing the K-means clustering algorithm. The algorithm was trained to identify the optimal number of clusters using techniques like the elbow method to determine the best number of segments that represent the diversity of customer behaviors.
Evaluation and Interpretation: After applying the K-means algorithm, we analyzed the results by examining the characteristics of each customer segment. We used visualizations such as scatter plots and silhouette scores to assess the quality of the clusters and gain insights into customer behavior.
Visualization: Finally, we visualized the clusters using matplotlib and seaborn to create clear, understandable plots showing the different customer segments. This made it easier to interpret the results and demonstrate the potential business applications of customer segmentation.
Challenges we ran into Determining the Optimal Number of Clusters: One of the primary challenges in this project was determining the correct number of clusters. The elbow method helped, but sometimes, the results weren't as clear-cut as expected, especially with large datasets. We also used the silhouette score to validate the cluster cohesion and separation.
Handling Imbalanced Data: Some customer segments were underrepresented, which could lead to skewed results. We had to balance the dataset to ensure that all segments were adequately represented and that the algorithm wasn’t biased toward more prominent groups.
Feature Selection: Selecting the right features was another challenge. Including too many irrelevant features could reduce the quality of the clusters, while excluding useful ones could lead to an incomplete understanding of customer behavior.
Scalability Issues: As the dataset grew, the K-means algorithm sometimes faced performance issues. We had to fine-tune the algorithm’s parameters and sometimes reduce the dataset’s size for testing purposes.
Accomplishments that we're proud of Accurate Customer Segmentation: We were able to successfully segment customers into meaningful groups that aligned with known marketing strategies and behaviors, which would be valuable for any business looking to optimize its operations.
Clear and Understandable Visualizations: The visualizations of the customer segments were easy to interpret, making it simple to convey our findings to stakeholders, even those with little experience in data science.
Insightful Business Implications: Our clustering results provided actionable insights into how businesses could approach different customer segments with tailored strategies, which could improve customer engagement and sales.
What we learned Importance of Feature Engineering: The project reinforced the importance of selecting the right features for clustering, as the success of the model heavily depends on the quality and relevance of the input data.
Challenges in Unsupervised Learning: Unsupervised learning, especially clustering, presents unique challenges such as choosing the correct number of clusters and dealing with noise in the data. We learned how to handle these challenges effectively.
Data Preprocessing and Scaling: We learned how crucial data preprocessing and scaling are for clustering algorithms like K-means. Properly preparing the data can lead to significantly better and more meaningful results.
Evaluating Clustering Models: The project helped us understand how to evaluate clustering models and ensure that the segments are meaningful. It wasn’t just about finding clusters but also about interpreting them correctly.
What's next for Customer Segmentation using K-means Clustering Model Optimization: Future iterations could involve tuning the K-means algorithm further or exploring other clustering techniques like DBSCAN or Gaussian Mixture Models (GMM) to improve segmentation accuracy.
Incorporating More Features: Adding additional features such as customer feedback, web interaction data, or social media activity could help make the segmentation even more granular and insightful.
Real-time Segmentation: Implementing the model into a real-time application where new customer data is automatically processed and segmented would add significant value for businesses looking to act on the insights instantly.
Predictive Analytics: Beyond clustering, we could develop predictive models that forecast customer behavior or predict the likelihood of a customer moving between segments over time.
By continuing to refine this project, we can create a robust customer segmentation tool that helps businesses not only understand their customers better but also optimize their marketing and service strategies.
Built With
- clustering
- k-means
- machine-learning

Log in or sign up for Devpost to join the conversation.