-
-
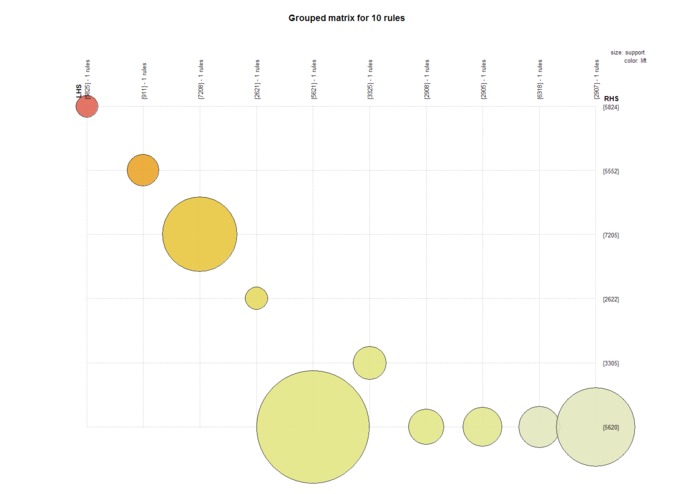
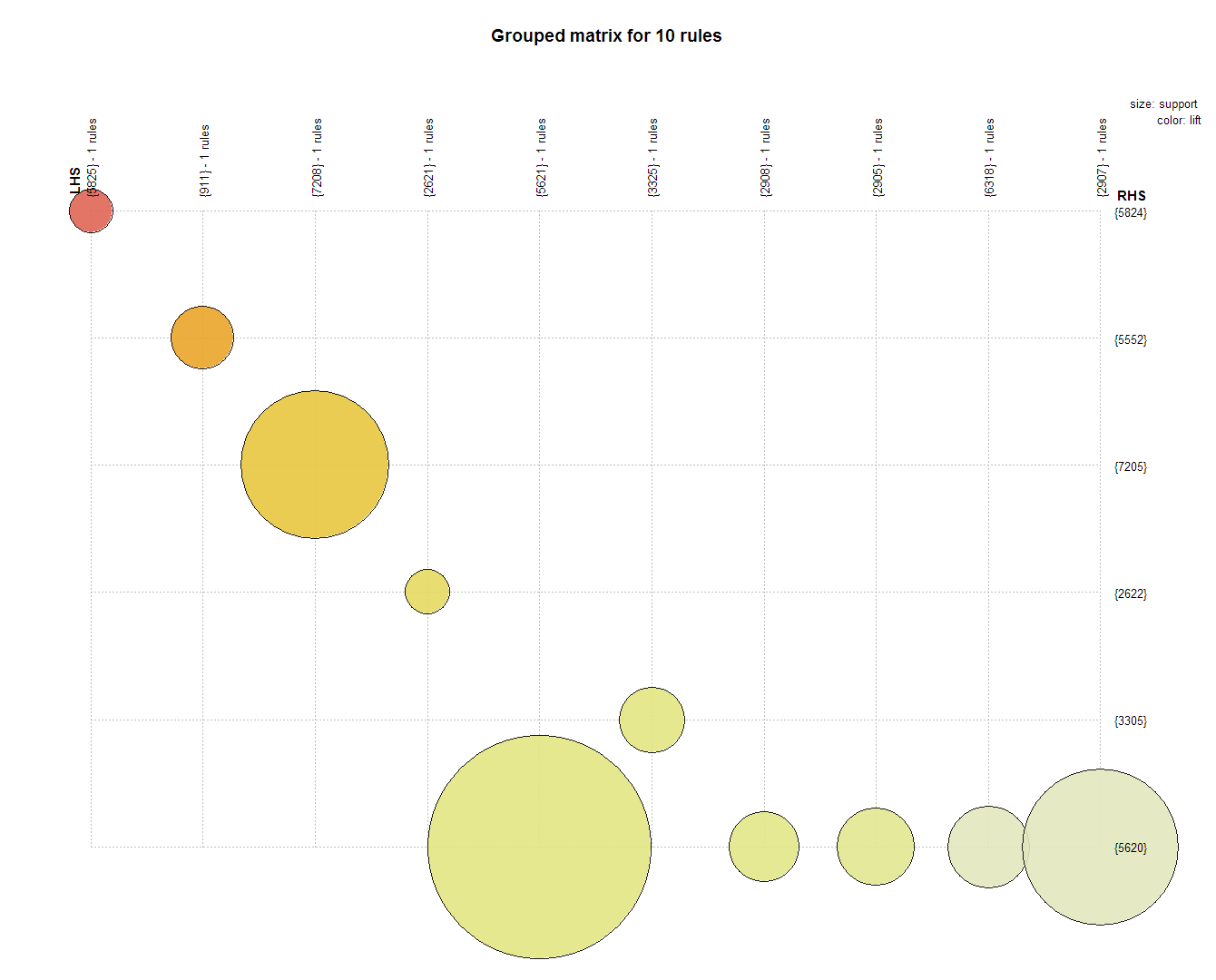
Top 10 Association Rules by Lift
-
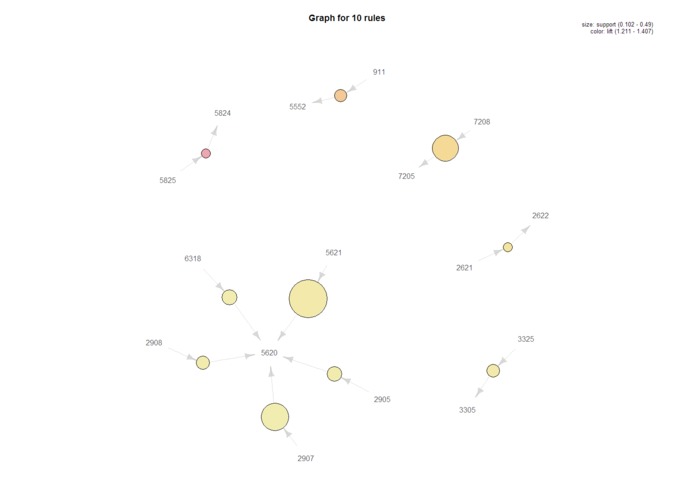
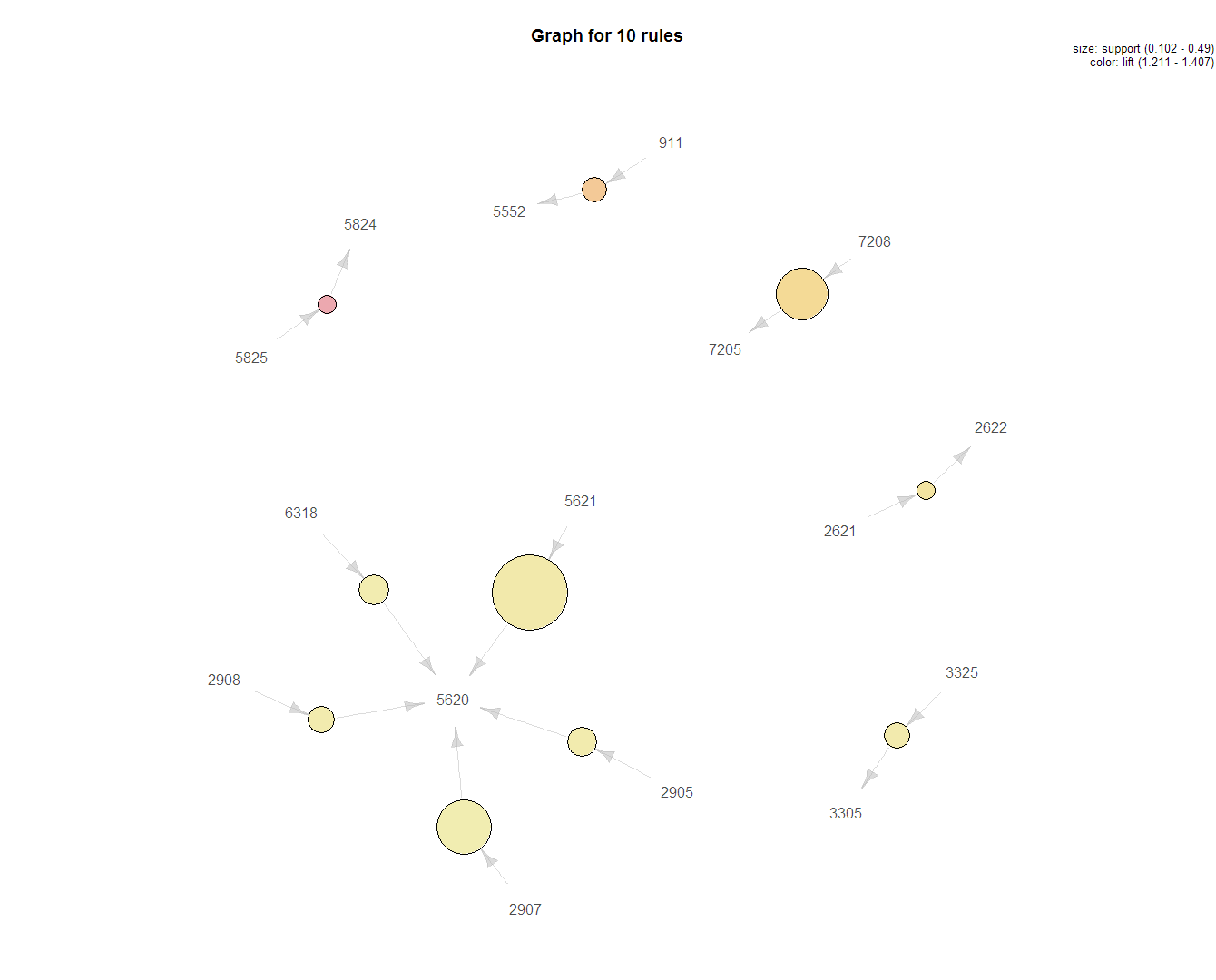
Network Visualization of Top 10 Association Rules by Lift
-
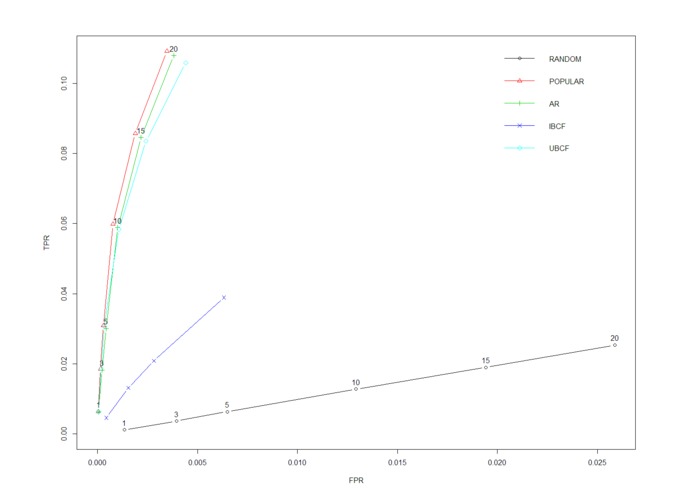
Recommend Algorithm Evaluation
Introduction
This Apache Spark application is directed around customer analytics to address marketing execution, gain insights regarding product assortment, and improve the customer experience.
The application provides three features
- Customer Segmentation using a Recency, Frequency, Monetary (RFM) model
- Market Basket Analysis using Association Rules
- Evaluation of Product Recommendation Algorithms
Specific Business Need
As customer affinity programs move from plastic barcode cards to mobile apps, companies gain increased opportunities to understand their customers through app engagement data. This will enhance traditional transaction data because it can include customer preferences, engagements, location, and social activity. Companies which excel at this new data augmentation have the potential to offer better customer experiences.
This application is intended to lay the analytics foundation for mobile app affinity programs. Apache Spark is an analytics operating system to hold all this new data and build applications on top of it for analysis and reporting.
About the data
You want to have a sufficiently large scale data set to explore the capabilities of Apache Spark. The data set I used for this challenge contained 350 million annonomized customer transaction records. The data storage for this file was close to 20 GB.
Infrastructure and Tools
The application was developed on the IBM Bluemix cloud platform. It uses the Apache Spark and Object Storage services. The Apache Spark application runs in the SparkR notebook.
I installed the R package, arules, within my SparkR notebook to run the market basket analysis association rules. Association rules is computationally intensive, and the size of the item sets can grow quite large rather quickly as you data mine for additional sets.
The recommenderlab package was used to evaluate the various product recommendation engines. Other R packages include arulesViz, highcharter, dplyr, lubridate and magrittr. In addition, I used the Swift CLI tool to upload the data Object Store.
Data Transformation
The initial data set is an aggregate transaction record from multiple retail chains. In order to perform the proposed analysis in a way that would make sense, I would need to select one chain. The data set was accompanied with a smaller promotions data set. I used the promotions data set to identify the chain to select. I ran a frequency distribution on customer ID to identify the chain with the largest number of customers. I used this chain as the primary analysis data set. The one chain subset contains 12 million transaction records.
Customer Segmentation
Recency, Frequency, Monetary (RFM) is a simple model to segment existing customers based on a few data points within your transaction data.
Recency - When was the customer's last purchase?
Frequency - How often does the customer make purchases?
Monetary - How much has the customer purchased within at time period?
Each term is scored into five segments. The terms are grouped and then ordered with 555 being the highly valued customers and 111 being the least.
RFM has two key advantages in a corporate environment.
- Easy to communicate to a broad audience. Marketing, operations, executive decision makers can understand the principles behind the model.
- Performs well with transaction data. If your core customers are trend obsessed, it can track fast moving segment shifts.
Process
The primary objective for this RFM analysis is to compare customer segment differences between last quarter and the most recent quarter. I created a data frame for each of the RFM elements - recency, frequency, monetary and at each quarter. There are six data frames in total. The data frames were exported to partition csv files in Object Store which were used to create the RFM segments and the interactive visualizations in R Studio. The visualizations used the highcharter package, a R wrapper for d3 visualizations.
RFM Heat Map Visualizations
The heat maps show the quarter to quarter difference. Last quarter was the Christmas holiday season and it reflects the increased monetary intensity within the top right hand quadrant for the highly valued customers. The interactive visualization which show the average monetary value for each segment can be found here: http://rpubs.com/robcamp/affinity
Market Basket Analysis
Market Basket Analysis attempts to learn about the product relationships in the customer's transactions. If a customer purchased item A, what can I learn about item B?
Association Rules are written such as
A ==> B
Association rules have three important metrics: Support, Confidence, Lift
Support is the probability both items are in a basket. It answers the question "What percent of all the customer baskets contain A and B"?
Confidence is the conditional probability that B is in the basket given that A is present. It expresses validity for the rule. Expected confidence is the probability that B is in a basket.
Lift is the confidence divided by expected confidence. It is the ratio of the likelihood of B being in a basket with A to the likelihood of B being in any basket. When lift is greater than 1, A is believed to lift the presence of B above what we would normally expect to see.
Data Process
Using the transaction data frame, I created a unique ID for each transaction. This ID is transformed to create a customer trip ID which is used to identify all the products purchased on that trip. The data frame is transformed again to create a customer-product data frame which builds a product history for the customer. This data frame is used for the market basket analysis.
Association Rule Learning
The market basket analysis used the ECLAT (Equivalence Class Transformation) algorithm to build the product item sets. ECLAT is an elegant algorithm to find frequent item sets. The analysis seeks to find item set pairs that are in at least 10% of all transactions. The ECLAT algorithm found 64,487 item set pairs.
The next step is to build the association rules. I wanted to create a set of rules with 90% confidence. Simply put, I can say that I am at least 90% confident that Product A has a relationship with Product B. From the association rules, I created a subset of ten product relationships based on the item sets with the highest lift. These are used in the following visualizations.
This network graph shows the product item sets for the top 10 association rules with the highest lift. This visualization's strength is to show the product relationships. Product 5620 has five related products. 5621 ==> 5620 has support of .49 which means this item set can be found in 49% of all transactions.
This is a 2D representation of the same top 10 association rules with the highest lift. It represents the lift order, and shows the scale of the support for the item sets.
Recommendation Engine
The final step of the analysis is to evaluate product recommendation algorithms. This is a followup based on the data analysis from the market basket analysis and uses the R objects created from the market basket analysis.
I use the R package recommenderlab. I create a binary matrix from the transactions object in the market basket analysis. I use this binary matrix to create the evaluation scheme by executing a split test with 1 fold using 90% of the samples for training with 3 items as given. I built a list of recommendation algorithms which can work with a binary matrix. These include:
- Random (used as the baseline)
- Association Rules
- Popular
- Item Based Collaborative Filter
- User Based Collaborative Filter
The algorithms are evaluated by looking at the top N items for 1,3,5,10,15,20 product recommendation. The evaluation routine computes the confusion matrix for each algorithm.
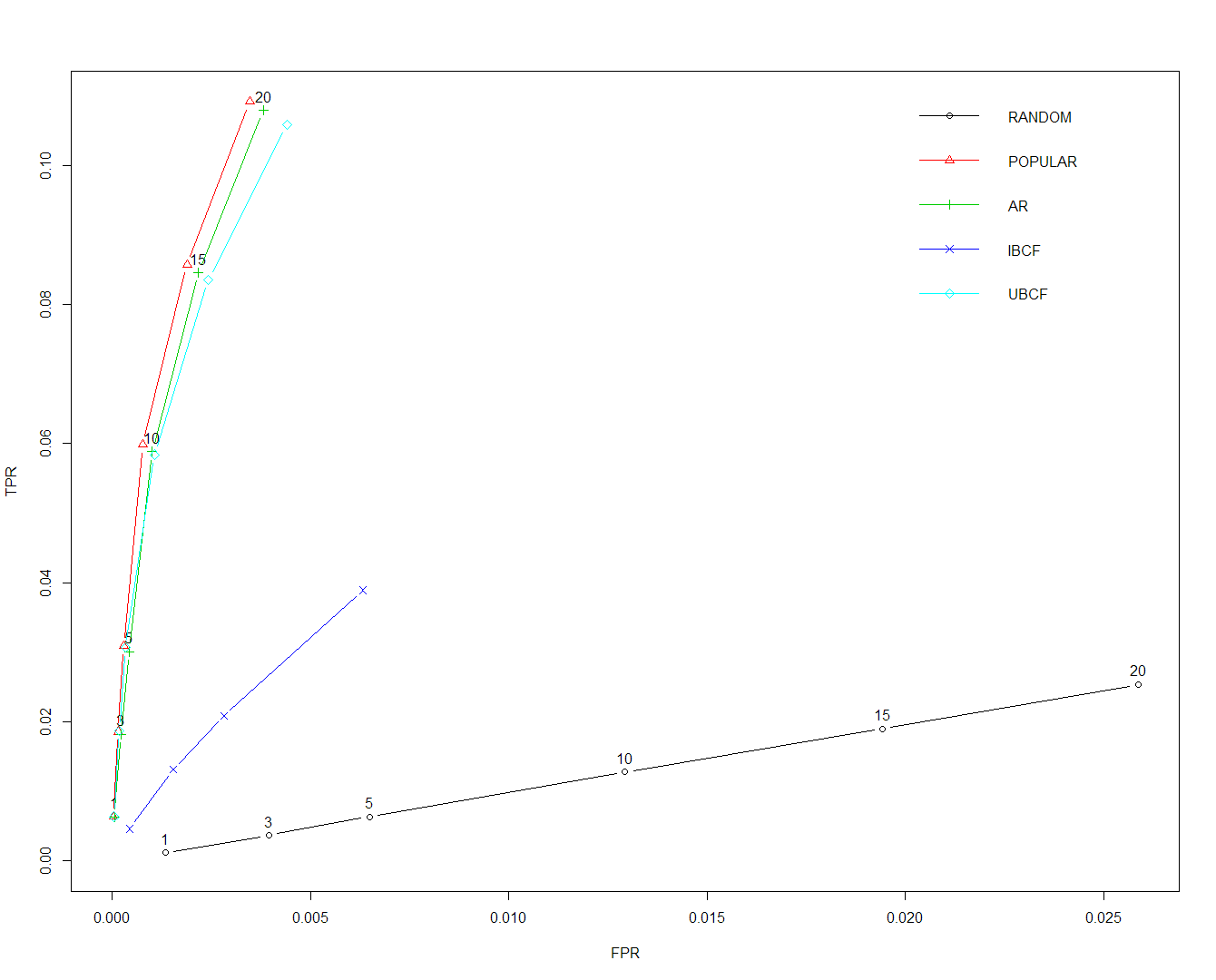
Recommendation algorithm evaluation
This graph shows the results from the recommendation algorithms evaluation. It plots the True Positive Rate (TPR) and False Positive Rates (FPR) for each of the algorithms. For the first five recommended items, three algorithms appear to be equal, Popular, Association Rules (AR), and User-Based Collaborative Filter (UBCF). As you starting increasing the number of items in the recommendation suggestions, separation starts to occur after 10 items. The Item-Based Collaborative Filter (IBCF) algorithm stopped after ten items.
Challenges and Learning Experiences
I bumped up against the 5 GB upload limit to Object Storage on Bluemix. In order to upload the 20 GB transaction data, I needed to use the Swift CLI and upload the file by setting segment sizes which could not exceed 5 GB. I needed to install all the necessary python packages and their dependencies and figure out all the authentication settings to move the file into my Bluemix environment. SparkR on Bluemix did have an elegant method to access the data once all the segments were upload.
transactions <- read.df(sqlContext,"swift://notebooks.spark/transactions.csv",source = "com.databricks.spark.csv", header="true", inferSchema = "true")
Another challenge I ran into was trying to use the new R Studio package, sparklyr, to connect to Spark on Bluemix. JJ Allaire spoke about this package at the the Apache Spark Maker Community Event. It would have been nice to use this package and keep the development within one IDE. For this challenge, I needed to use two IDEs. Notebook for SparkR on Bluemix for the spark data and R Studio on my local machine for the visualizations.
My key learning experience with this challenge is knowing how to build a market basket analysis with association rules. It is a subject which I've read material, but having large data set to execute the analysis and dive in deep to the rich R packages around association rules was worthwhile.
What's Next
This application lays the foundation to build an enhanced customer relationship. The RFM analysis creates your customer segments. The market basket analysis shows related purchased products. This can be used to bundle products in store displays, inform your online customers "Customers Who Bought This Item Also Bought", or create marketing programs for suppliers. Recommendation algorithm evaluation gives you the direction to begin creating customer product recommendations.
Now you know the customer's transaction history and have put it into a context.
However, transaction data alone does not tell much about your customer's needs. The next step is to layer the data from your mobile app affinity program on top of your transaction data.
This will allow you to build an analytics platform which creates personalized customer experiences and predictive insights to help you stay on top of fast moving consumer trends. Successful execution will not only enhance your customer relationships, but integrate the relationship as a part of your best customers lifestyle.


Log in or sign up for Devpost to join the conversation.