About the Project
Curtain is the name we gave our URL shortener app.
Performance Under Pressure
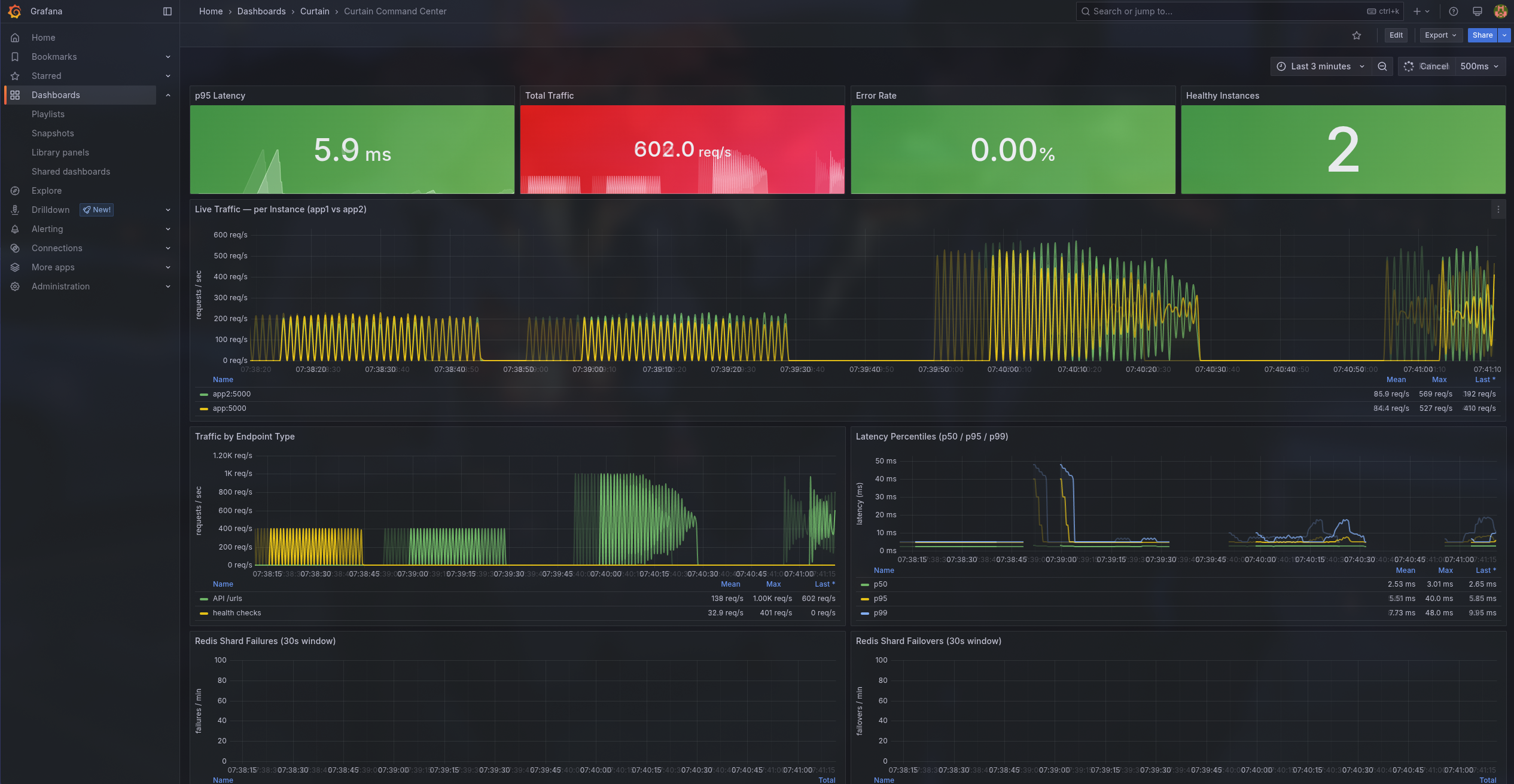
At 50 concurrent users, the service clocks a p95 latency of 38ms with a 0% error rate; most redirects resolve faster than a single frame renders on screen. Scale that 4x to 200 concurrent users behind two horizontally-scaled app replicas and Nginx load balancing, and the p95 only climbs to 218ms, still well under a quarter-second, still 0% errors. Push it to the breaking-point test at 500 concurrent users, and the system holds the line: p95 of 1.01s, zero errors, zero dropped requests. The Redis cache layer means hot reads never touch Postgres, the consistent-hash shard ring distributes click writes across isolated Redis instances, and the 50ms Redis timeout policy ensures a slow backend degrades gracefully instead of cascading into queue buildup. From 50 to 500 users, a 10x traffic multiplier, the error rate stayed flat at 0.00% across every tier.
How Everything Works Together
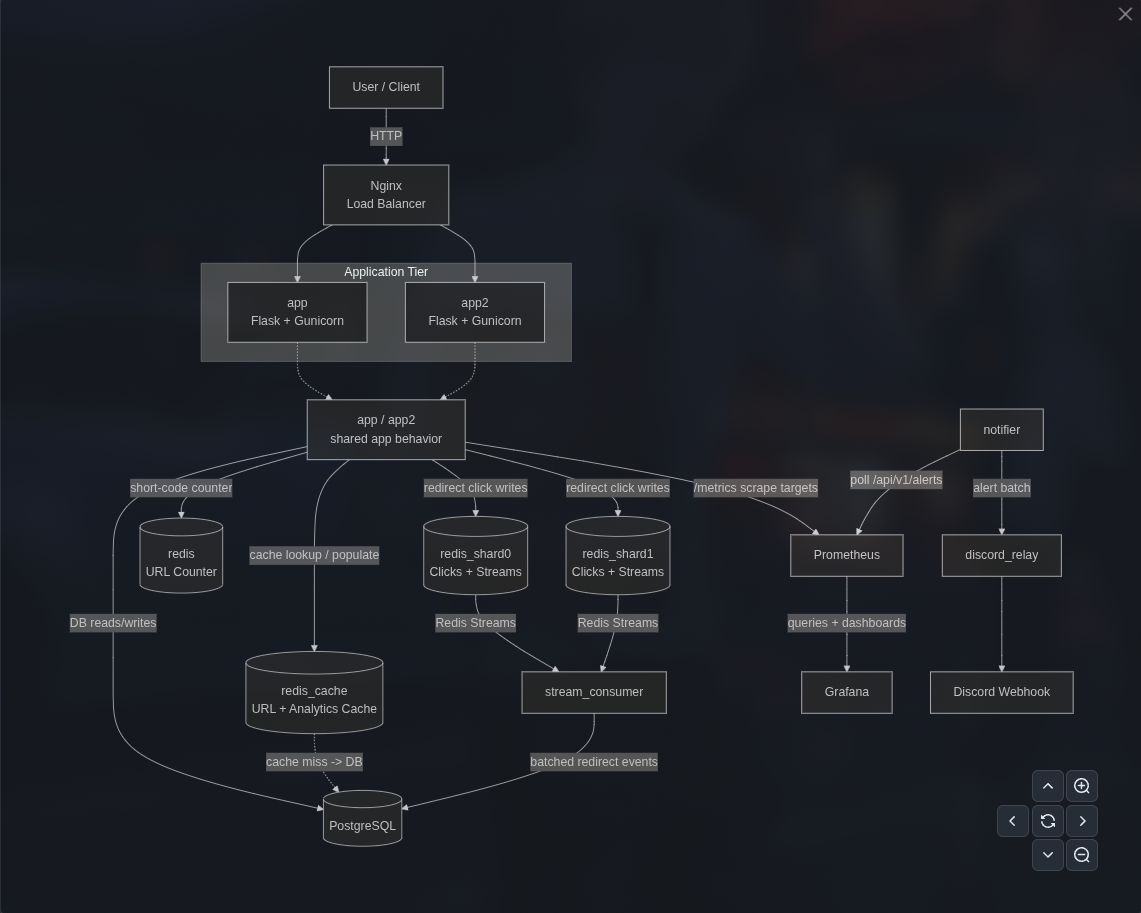
Request Flow: An incoming HTTP request hits Nginx, which load-balances across two identical Flask application replicas using least_conn. Nginx maintains a connection pool (keepalive 64) to minimize TCP overhead to the upstream servers.
Application Layer: Each app instance runs behind Gunicorn with the gthread worker class (4 workers, 4 threads per worker), giving us 16 concurrent request handlers per replica, 32 total. The Flask app uses Peewee ORM with a PooledPostgresqlDatabase (max 20 connections, 300s stale timeout) for all durable reads and writes.
URL Shortening: When a URL is shortened, the app uses a dedicated Redis counter instance with SETNX + INCR to generate globally unique, monotonically increasing short codes — no database sequences, no coordination between app replicas. If Redis is unavailable, it falls back to a database-derived counter.
Redirect (the hot path): When a user hits /r/<short_code>, the app first checks the Redis cache for the redirect metadata. On a cache miss, it queries Postgres, caches the result, and returns a 302. Every redirect also fires a click recording pipeline to the Redis shards — this is the write-heavy path that the sharding layer is designed to handle.
Event Persistence: Click data written to Redis shards via XADD (Redis Streams) is consumed by stream consumer workers (2 replicas) running XREADGROUP in consumer groups. These workers batch-insert events into Postgres and XACK on success, giving us eventual consistency between the real-time Redis counters and the durable Postgres event log.
Observability Stack: Both app replicas expose a /metrics endpoint scraped by Prometheus (using prometheus-client in multiprocess mode). Grafana provides dashboards, PromLens offers a PromQL explorer, and a custom notifier service polls Prometheus alerts and forwards them through a Discord relay for real-time incident awareness.
Tech Stack
| Layer | Technology |
|---|---|
| Language | Python 3.13 |
| Web Framework | Flask 3.x + Gunicorn (gthread) |
| ORM | Peewee + PooledPostgresqlDatabase |
| Database | PostgreSQL 16 |
| Caching & Streams | Redis 7 (4 instances, role-separated) |
| Reverse Proxy | Nginx (Alpine) |
| Metrics | Prometheus + Grafana + PromLens |
| Alerting | Custom notifier + Discord webhook relay |
| Packaging | uv (astral-sh/uv) |
| Load Testing | k6 |
| Deployment | Docker Compose |
Redis Architecture: Caching, Sharding, and Streams
One of the core production engineering decisions in Curtain is how we use Redis — not as a single monolithic instance, but as four operationally isolated Redis instances, each with a distinct role, failure domain, and eviction policy.
Redis Topology
| Instance | Role | Eviction Policy | Purpose |
|---|---|---|---|
redis |
Counter | Default (no eviction) | Monotonic short-code generation via INCR |
redis_cache |
Cache | Default | Read-through JSON response cache |
redis_shard0 |
Click Shard | allkeys-lru (64MB) |
Click counters, HyperLogLog, streams |
redis_shard1 |
Click Shard | allkeys-lru (64MB) |
Click counters, HyperLogLog, streams |
This separation means a cache eviction storm can't starve the counter, and a click traffic spike on the shards can't evict cached API responses. Each failure domain is independent.
Response Caching Strategy
The cache layer (app/cache.py) implements a read-through JSON cache on the dedicated cache Redis instance with explicit TTLs per data type:
| Data Type | TTL | Cache Key Pattern |
|---|---|---|
| URL Detail | 300s (5 min) | cache:url:{id} |
| URL Redirect Metadata | 300s (5 min) | cache:url:redirect:{short_code} |
| URL List | 120s (2 min) | cache:url:list:... |
| URL Analytics | 120s (2 min) | cache:analytics:url:{id} |
Every cached response includes an X-Cache header (HIT, MISS, or BYPASS) for observability. On writes (create, update, delete), the cache is actively invalidated — not just for the specific URL, but for all related list-cache key permutations (global lists, per-user lists, filtered by is_active), preventing stale reads.
Resilience: All Redis cache operations are wrapped in try/except RedisError — a cache failure degrades to a miss (read) or a no-op (write/delete). The application never fails because the cache is down.
Application-Level Sharding with Consistent Hashing
Rather than using Redis Cluster (which adds operational complexity), Curtain implements client-side consistent hashing (app/shard_ring.py) to distribute click data across Redis shard instances.
How it works:
Hash Ring Construction: Each shard gets 150 virtual nodes placed on an MD5-based hash ring. This ensures even distribution even with a small number of physical shards.
Key Routing: For a given short code, the ring determines which shard owns that key. All click data for that URL (counters, HyperLogLog, streams) lands on the same shard, preserving locality.
Failover with
ResilientShardRing: If the primary shard for a key is unreachable, the ring walks to the next distinct shard in the ring. This means a shard failure doesn't drop writes — they fail over to the next shard in the consistent hash order. Shard failures and failovers are tracked via Prometheus counters for alerting.
Click Recording Pipeline (the hot path)
When a redirect happens, record_click() in app/services/click_counter.py executes a non-transactional Redis pipeline on the target shard:
INCR clicks:{short_code}:total # Total click count
INCR clicks:{short_code}:h:{hour} # Hourly bucket (72h EXPIRE)
PFADD clicks:{short_code}:uv # HyperLogLog for unique visitors
XADD stream:clicks:{short_code} # Redis Stream entry for persistence
All four commands are batched in a single pipeline round-trip. If the entire pipeline fails (shard down, no failover available), the app falls back to writing a redirect event directly to Postgres — so click data is never silently lost.
Redis Streams → PostgreSQL (Eventual Consistency)
The stream consumer (app/stream_consumer.py) runs as a separate service (2 replicas via Docker Compose) that drains click events from Redis Streams into Postgres:
- For each shard, discovers all
stream:clicks:*keys - Creates a consumer group (
pg_writers) if it doesn't exist - Reads batches via
XREADGROUP(blocking read) - Bulk-inserts
Eventrows into Postgres viainsert_many XACKs processed messages only after successful DB write
This gives us real-time counters in Redis (sub-millisecond reads) with durable event history in Postgres (for analytics, auditing, and complex queries) — the best of both worlds.
Connection Management
- Redis clients are singletons per worker process, created via
@lru_cache(maxsize=1)— no reconnection overhead per request - Aggressive timeouts: Socket timeout and connect timeout default to 50ms (
REDIS_SOCKET_TIMEOUT_SECONDS), configurable via environment variables — a slow Redis is treated as a failed Redis - PostgreSQL pooling: Peewee
PooledPostgresqlDatabasewith max 20 connections and a 300s stale timeout per app replica
Why This Design?
| Decision | Rationale |
|---|---|
| Separate Redis instances per role | Fault isolation — a cache eviction can't kill the counter |
| Client-side consistent hashing | Simpler ops than Redis Cluster, easy to add shards |
| 150 virtual nodes per shard | Even distribution with few physical nodes |
allkeys-lru on shards |
Bounded memory (64MB); old click buckets naturally evict |
| Redis Streams + consumer groups | At-least-once delivery, parallel consumers, backpressure handling |
| 50ms Redis timeouts | Fail fast — a slow cache is worse than no cache |
| Postgres fallback on shard failure | Zero data loss guarantee on the click path |
Built With
- caching
- docker
- flask
- grafana
- gunicorn
- loadbalancing
- ngnix
- postgresql
- redis
- sharding


Log in or sign up for Devpost to join the conversation.