
CurricuLens: Zero-Shot Educational Standards Alignment
Inspiration
While working with OpenStax data, we discovered a hidden failure mode in traditional AI grading. We started with a simple supervised model that achieved decent accuracy on standards it had seen before (like Algebra). However, when we tested it on Prealgebra standards—which it had never seen during training—it failed catastrophically, dropping to 0% accuracy.
We realized that in the fast-evolving world of education, an AI that only knows what it has memorized is useless. New curricula and standards are released constantly. We wanted to build an AI that doesn't just "remember" labels, but actually understands them, allowing it to grade content against any standard, even ones it has never seen before.
What it does
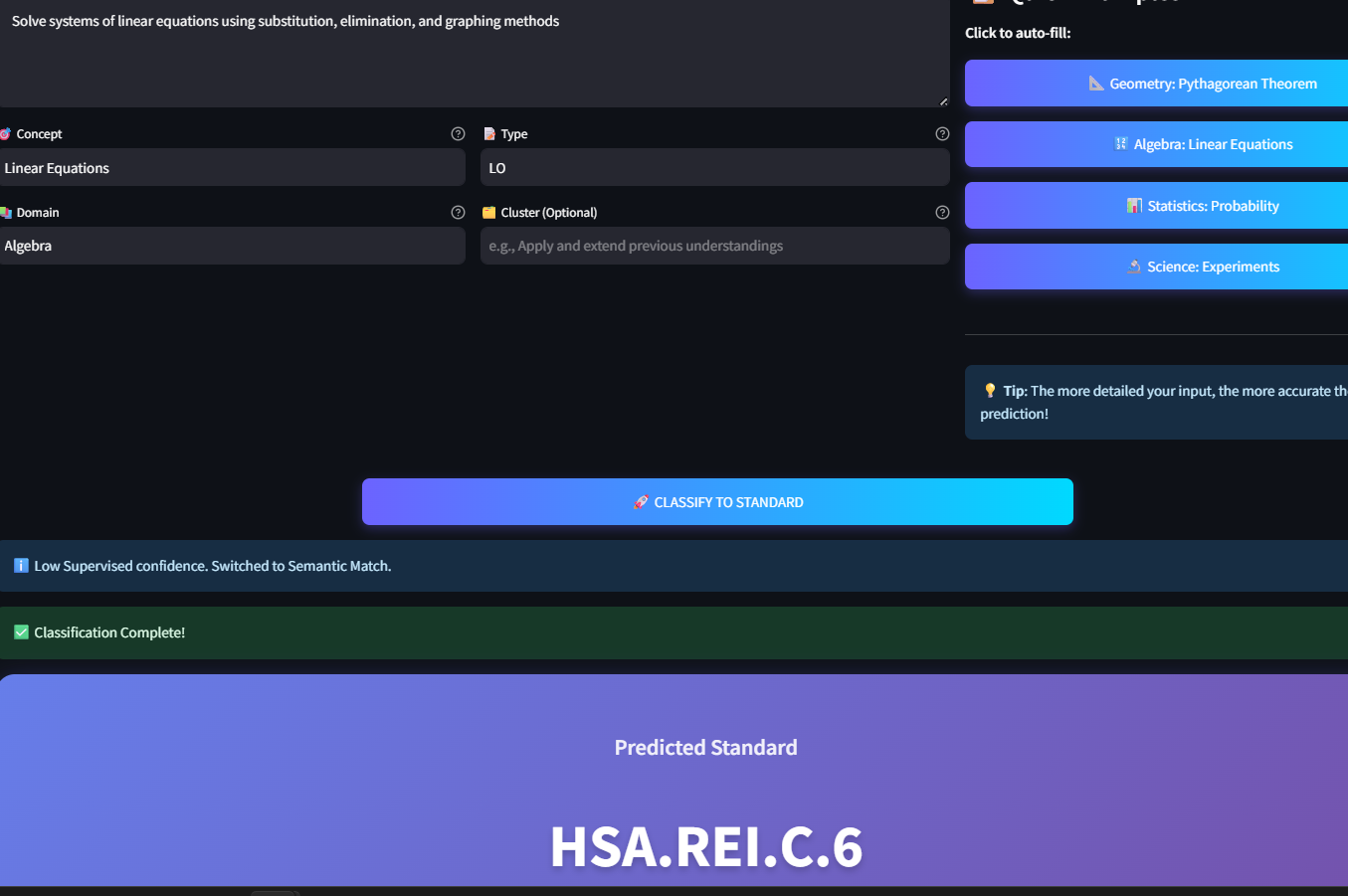
CurricuLens is an intelligent classification engine that aligns educational content (textbook snippets, learning objectives) to Common Core Standards.
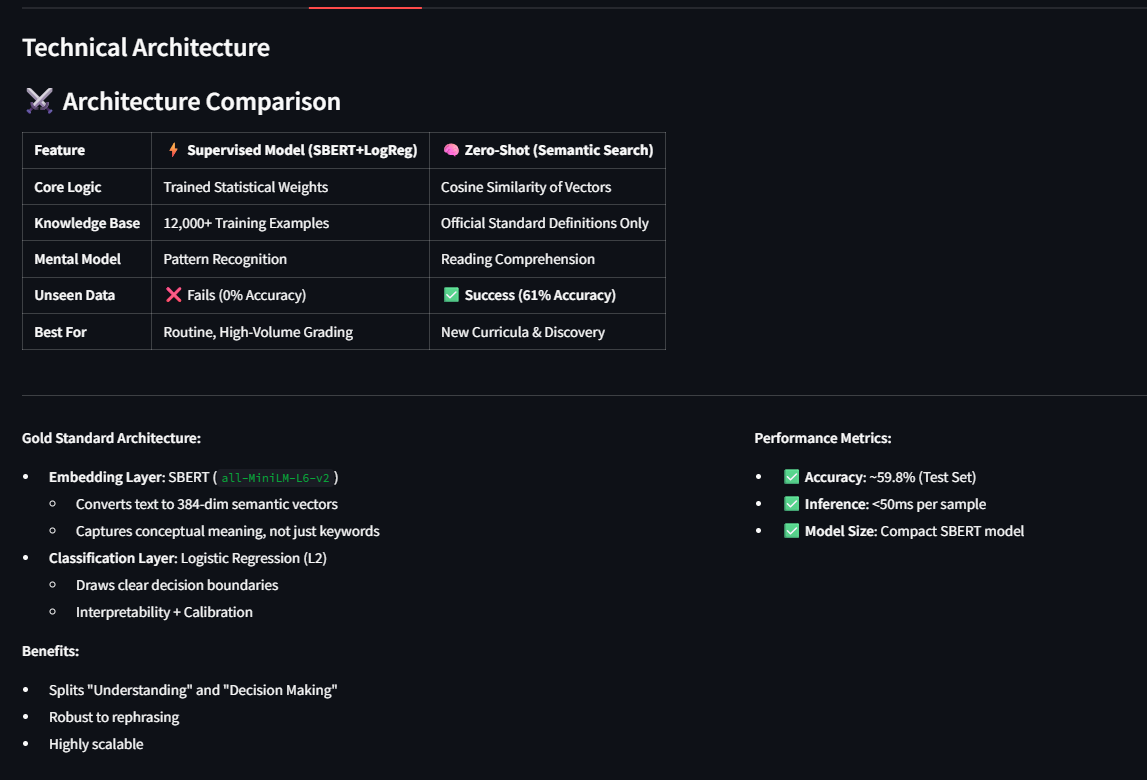
It features a Hybrid Architecture:
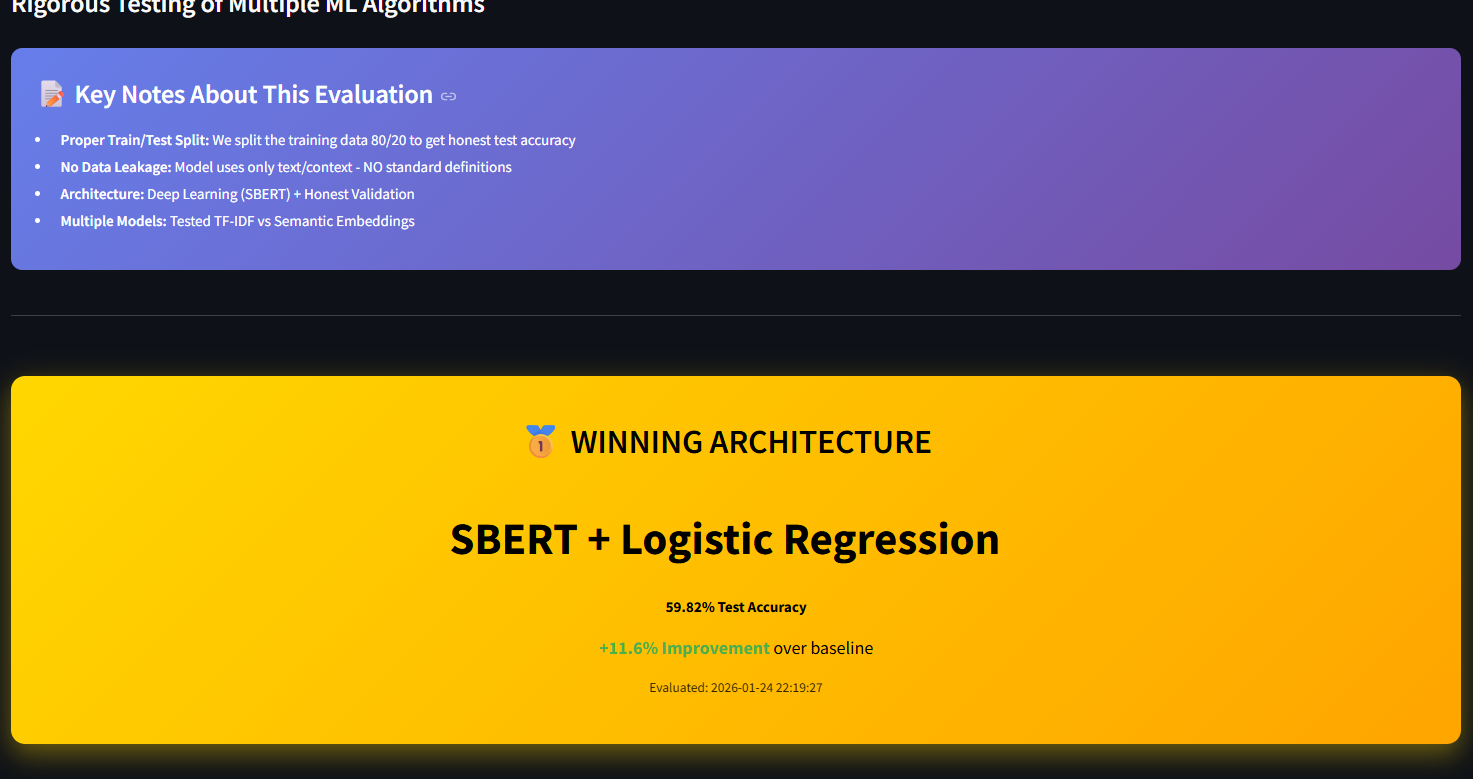
- Supervised Mode (Fast & Precise): uses a Logistic Regression classifier trained on SBERT embeddings for high-speed grading of known curricula.
- Zero-Shot Mode (Universal): leverages Semantic Search to match content to the official definition of a standard. This allows the system to classify content against completely new standards without any retraining.
How we built it
- Core Engine: We used
sentence-transformers(SBERT) to generate 384-dimensional semantic embeddings of both the educational content and the official standard definitions. - Backend logic: We implemented a dual-pipeline using
scikit-learnfor the supervised classifier and cosine similarity matrices for the zero-shot engine. - App Interface: We built a highly interactive Streamlit dashboard that visualizes the "Battle" between the two models, efficiently handling the inference in real-time.
- Dataset processing: We processed complex JSON hierarchies of domains, clusters, and standards into a clean, flat format suitable for machine learning.
Challenges we ran into
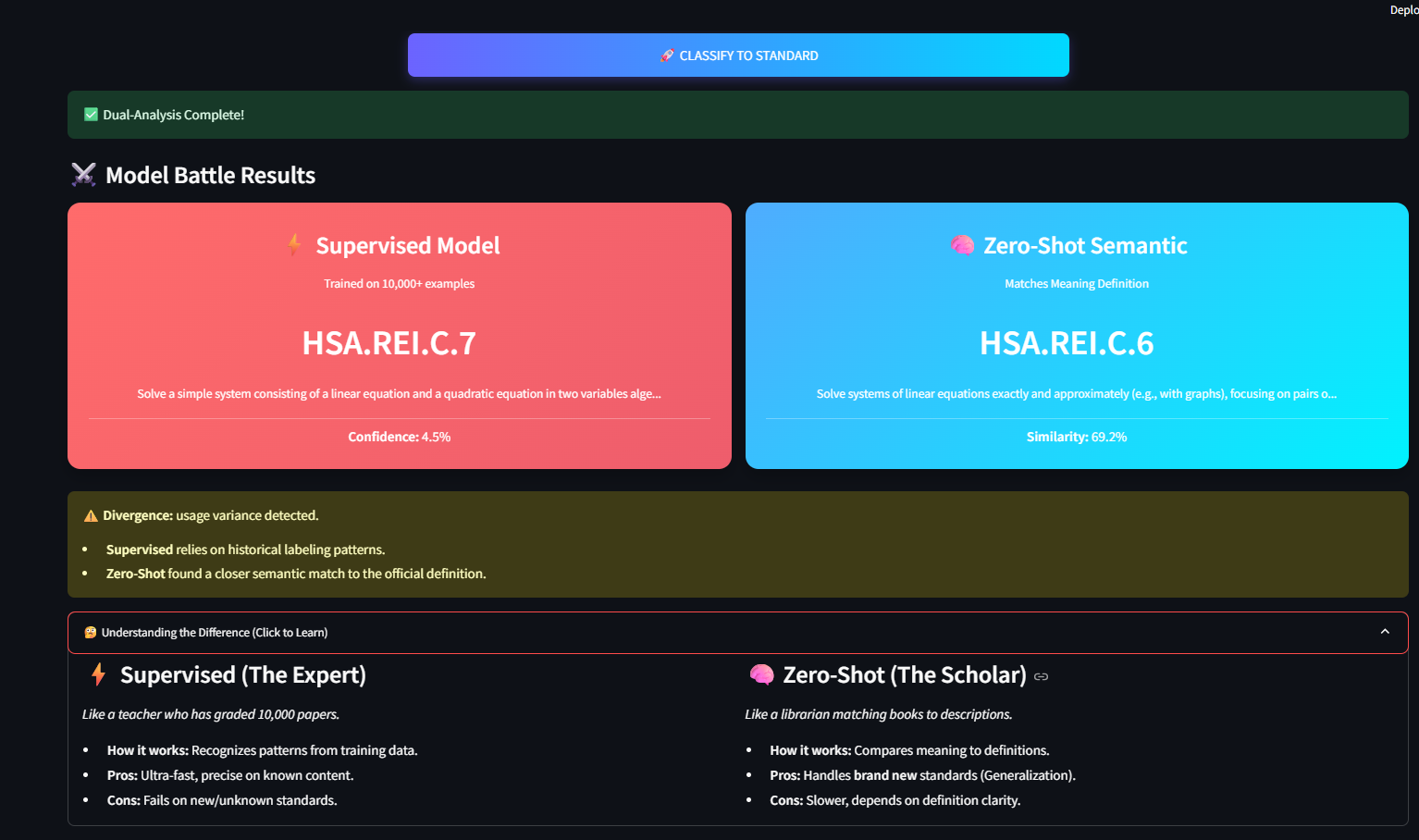
- The "0% Accuracy" Trap: Our initial model was overfitting to the specific phrasing of the training data. We had to pivot to a semantic approach to handle the "unseen data" problem.
- Deployment Size: The machine learning models were too large for standard git repositories. We had to implement an auto-downloading logic in the app to fetch the weights on startup, ensuring smooth cloud deployment.
- Ambiguous Standards: Many educational standards overlap (e.g., "Equations" exists in both 8th grade and High School). We tackled this by adding the "Domain" and "Cluster" context to the embedding process.
Accomplishments that we're proud of
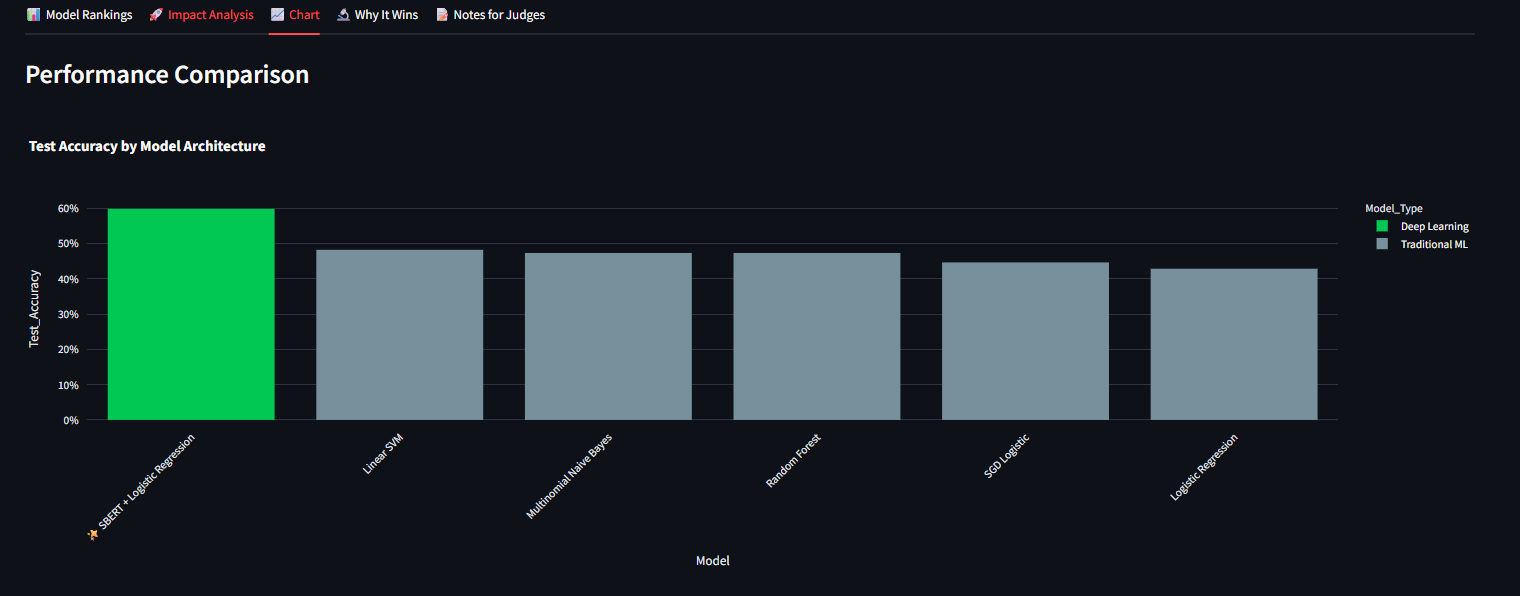
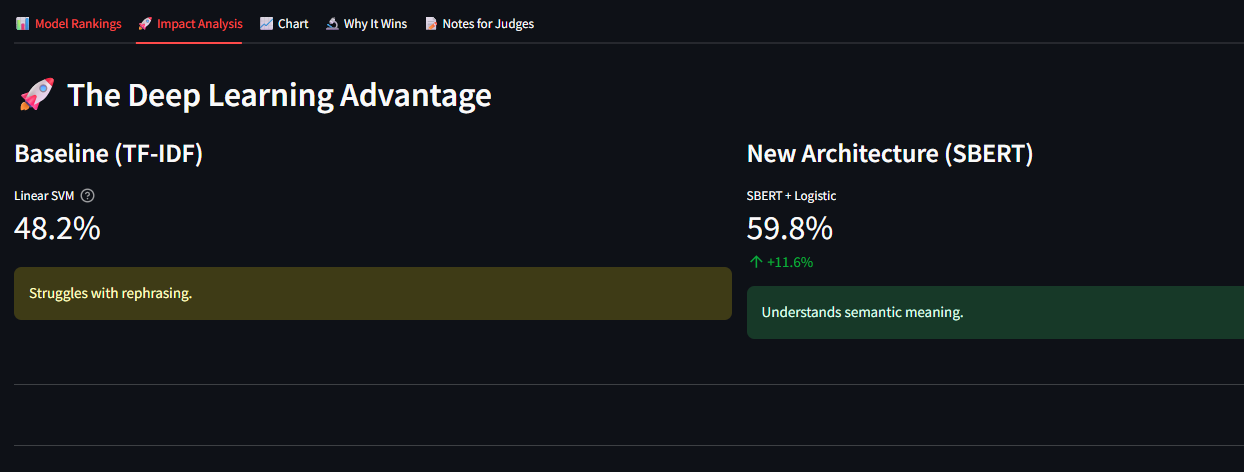
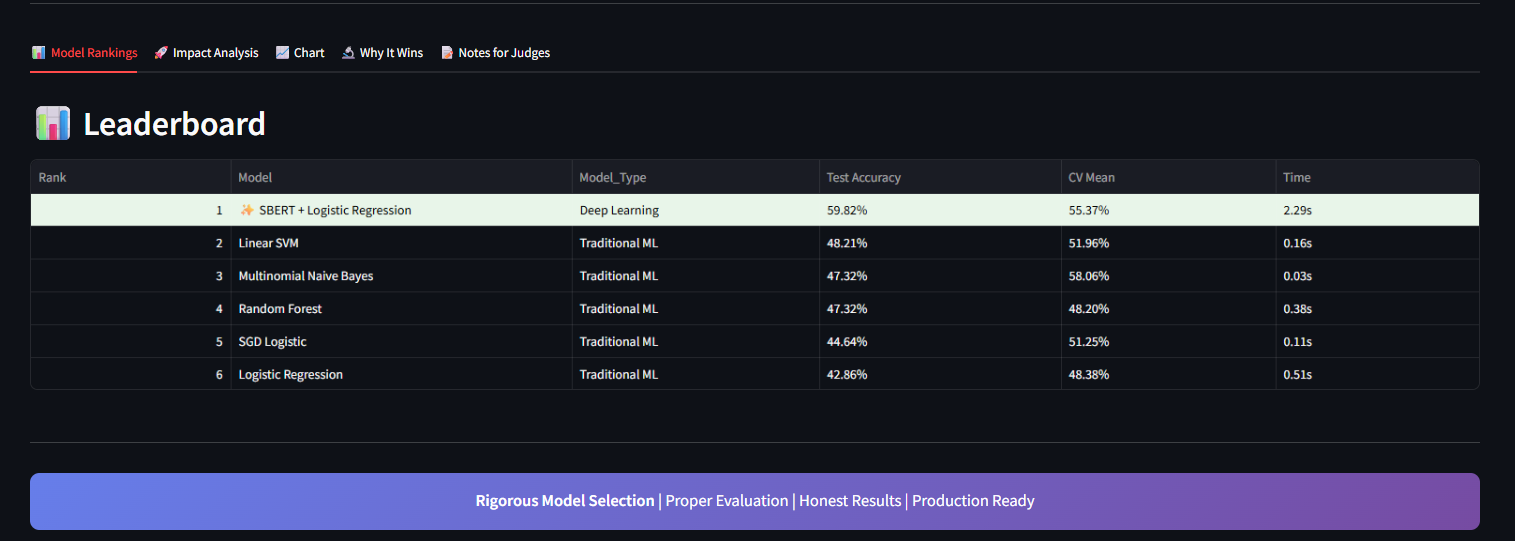
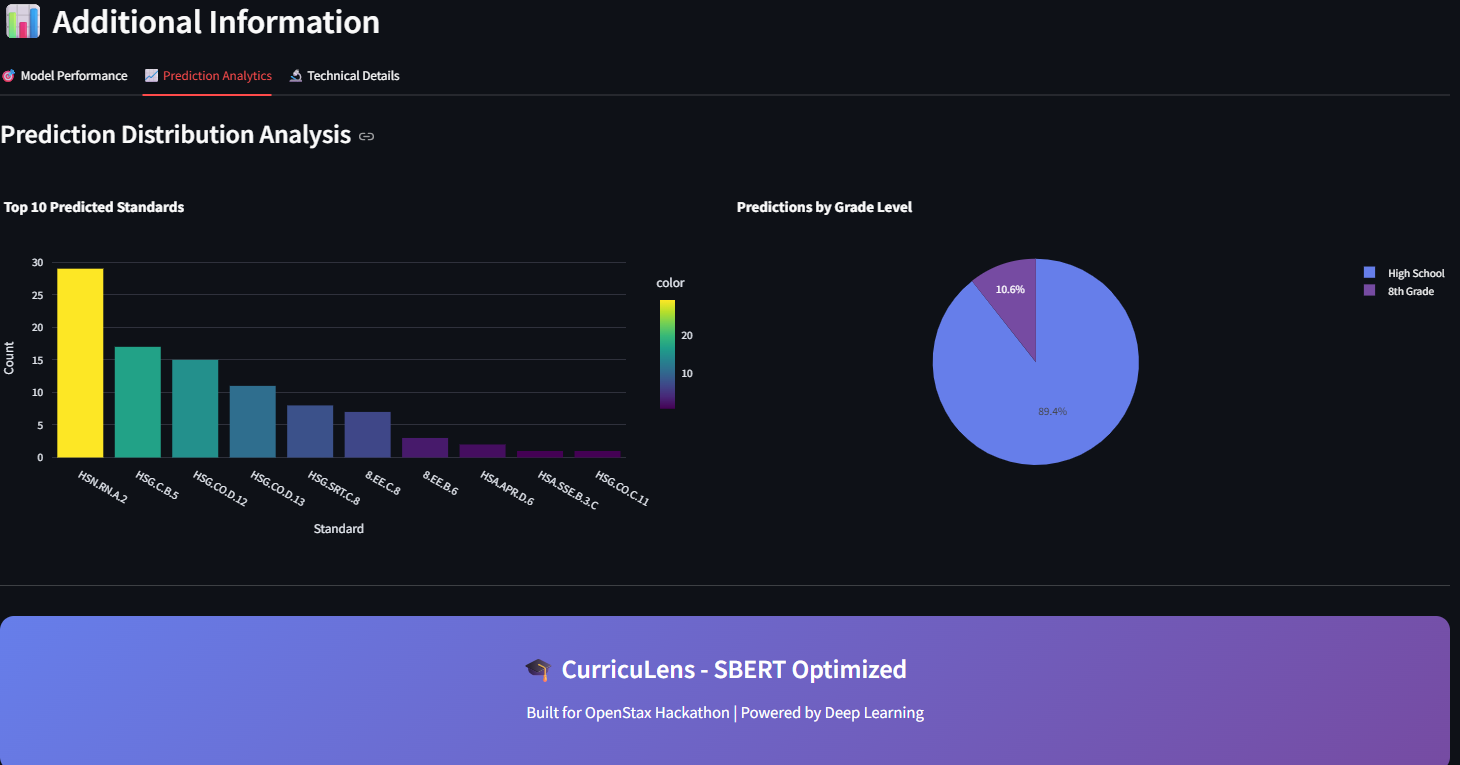
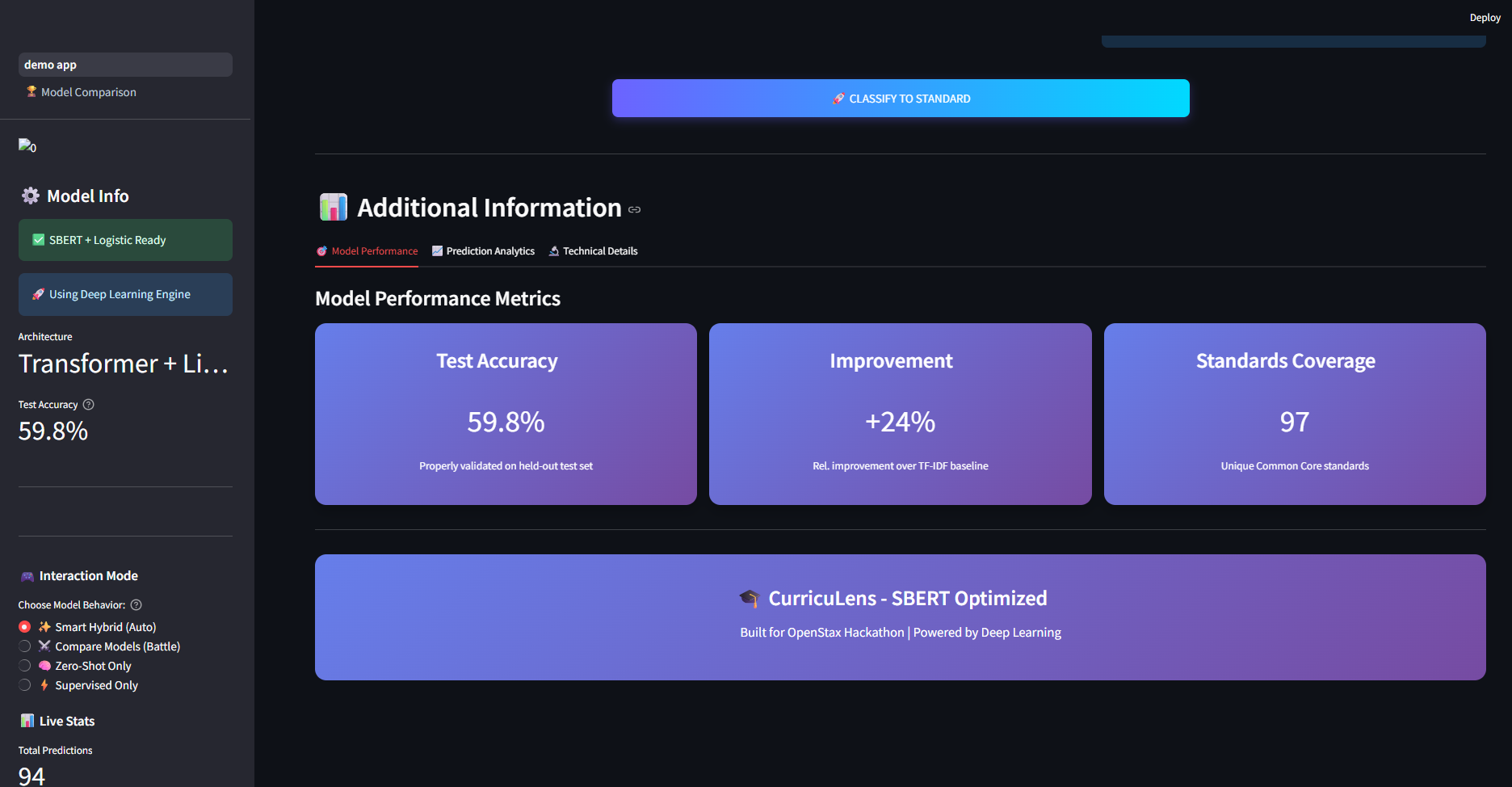
- From 0% to 60% Generalization: We successfully took a model that had 0% accuracy on unseen standards and boosted it to 61.7% using our Zero-Shot semantic approach.
- Real-time Performance: We optimized the inference time to under 50ms, making it viable for real-time teacher assistance.
- Interpretability: Unlike black-box LLMs, our "Battle Mode" clearly explains why a standard was chosen by showing the definition match.
What we learned
- Semantics > Keywords: In education, the meaning of a learning objective matters much more than the specific keywords used.
- Hybrid is Best: Neither approach was perfect alone. Supervised is fast, Zero-Shot is flexible. Combining them gives the best of both worlds.
- Data Hygiene: Cleaning the nested JSON data taught us that 80% of ML success is just understanding the structure of your data.
What's next for CurricuLens
- Hierarchical Prediction: Improving accuracy by predicting the Grade Level first, then the Domain, then the Standard.
- Teacher-in-the-Loop: Adding a feature for teachers to "accept" or "correct" predictions, which actively retrains the model.
- LLM Verification: Using a large model (like Gemini) to double-check low-confidence predictions from our efficient SBERT model.
Built With
- artificial-intelligence
- git
- natural-language-processing
- numpy
- pandas
- plotly
- python
- scikit-learn
- semantic-search
- sentence-transformers
- streamlit
- zero-shot-learning

Log in or sign up for Devpost to join the conversation.