-
-
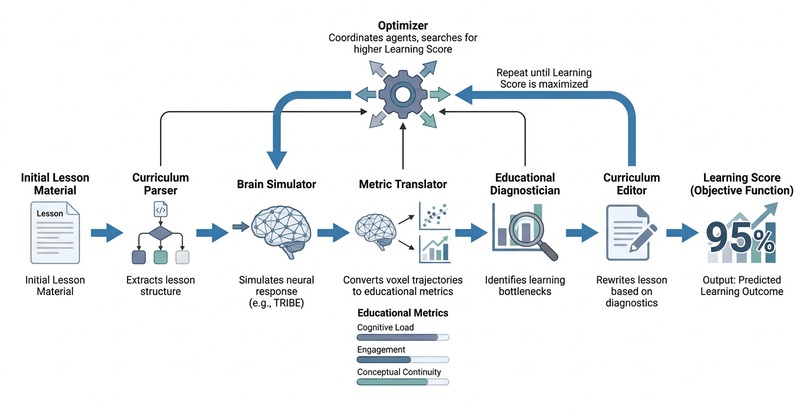
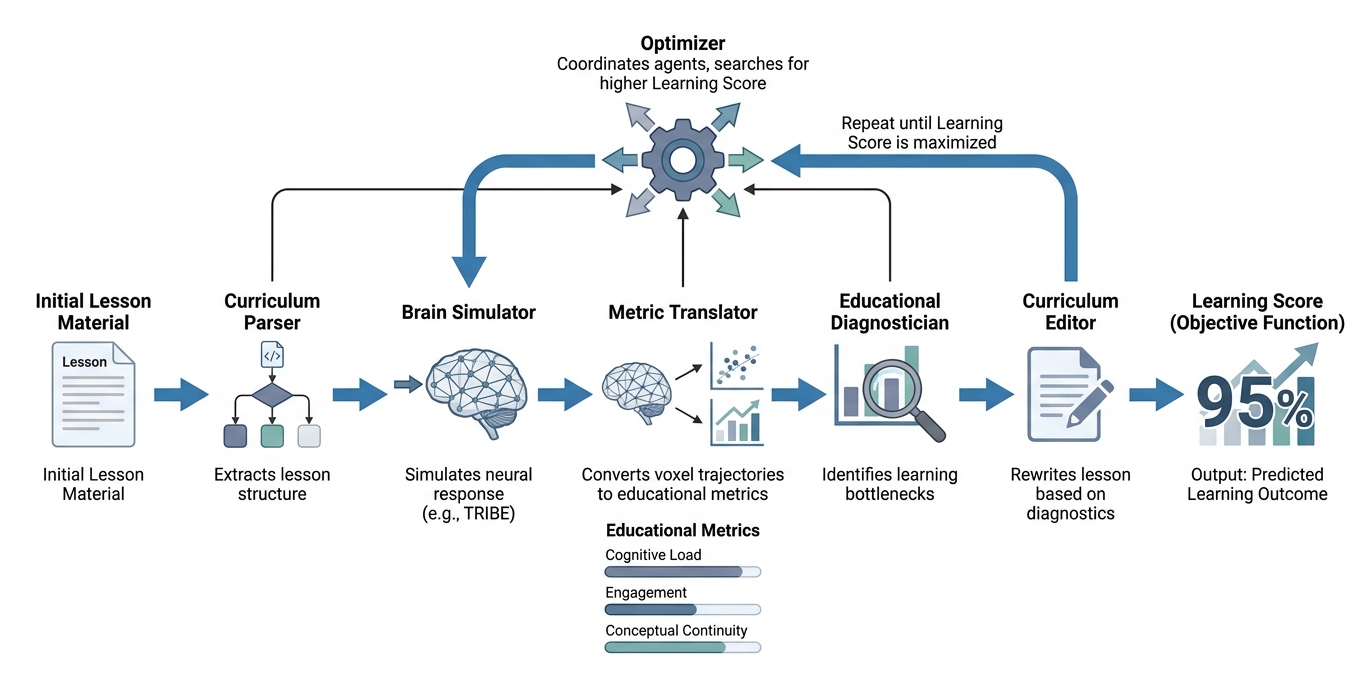
Flow chart of how CurricuLearn works
Inspiration
The New York Times published an article this past May with the headline claiming "U.S. Test Scores Are in a 'Generation-Long' Decline". These statistics are backed by teacher sentiment: nearly half of all teachers say that student engagement has declined compared with 2019 (Discovery Education, 2024). Teachers have no way to see inside a student's mind before a lesson fails them.
Now, they can! CurricuLearn attacks this gap directly by asking a new question: what if we could simulate how curriculum feels to a student’s brain before it ever reaches the classroom? We applied TribeV2, Meta’s cutting-edge brain encoding model, in a novel educational context: the model predicts cognitive responses to uploaded lesson material and identifies weak points in the curriculum. Then, based on desired patterns of neural activity for the best learning experience possible, it iteratively optimizes the lesson for engagement, clarity, and overall learning.
What it does
CurricuLearn is a curriculum optimization platform grounded in the science of learning. Teachers can upload educational resources (e.g. lesson plans, slideshows, worksheets, transcripts), and the system simulates how students would cognitively respond to it by scoring the lesson across five metrics: learning score, cognitive load, engagement, concept flow, and retention.
Rather than simply providing feedback, CurricuLearn automatically rewrites weak sections: splitting dense content, inserting examples and knowledge checks, and generating better speaker notes. It then re-simulates the revised lesson and compares scores against the original to ensure a stronger solution.
How we built it
We built CurricuLearn as a multi-agent curriculum optimization pipeline. First, we structured lesson content into individual sections so that each part of the lesson could be analyzed independently. From there, our system passes the lesson through a brain-simulation layer, translates the resulting representations into educational metrics, diagnoses weak points in the lesson, and automatically generates improved versions of the curriculum.
Our original goal was to use TribeV2’s brain simulation capabilities to predict how students might cognitively respond to lesson material. However, because running full brain-response simulation was too computationally expensive for the hackathon environment, we built a lightweight proxy model that preserves the same core idea. Instead of producing full voxel-level brain activity, our prototype converts lesson segments into semantic embedding trajectories, treating each embedding as a simplified representation of a student’s cognitive state over time.
We then built a metric translation layer employing Claude agents, which will map these representations into five interpretable learning metrics: learning score, cognitive load, engagement, concept flow, and retention. These scores allow the system to identify issues like overloaded sections, abrupt transitions, weak reinforcement, or material that introduces concepts too quickly.
Finally, we designed an optimization loop to automatically improve the lesson. Using these diagnoses, Claude agents can split dense sections, insert transitions, add review questions, generate examples, and restructure content. After each rewrite, the lesson can be re-evaluated and scored again, allowing CurricuLearn to search for a version of the curriculum that is predicted to be more engaging, understandable, and effective.
Although our hackathon prototype uses a lightweight approximation instead of the full TribeV2 model, we built the architecture around the same interface: lesson content goes in, simulated cognitive responses come out, and those responses drive automatic curriculum improvement. This lets us demonstrate the full CurricuLearn workflow now while leaving a clear path to swap in TribeV2’s brain simulation system as the backend when more compute is available.
Challenges we ran into
- Compute constraints: TribeV2's full simulation required more disk/compute than our laptops could support. We pivoted to the lightweight embedding-based proxy described above, preserving the same architecture and interface.
- Balancing depth with usability: Our users are teachers, not engineers, so the dashboard needed to explain a technical process without overwhelming them. We iterated on the UI multiple times to keep it informative but clean.
- The particle visualization: Building a Next.js animation to represent the background cognitive simulation was technically tricky to get smooth, but it made the optimization process feel tangible rather than like a black box.
Accomplishments that we're proud of
We built more than a lesson generator: CurricuLearn evaluates why a lesson would or wouldn't work cognitively, then closes the loop by rewriting and re-scoring it. We preserved the intent of brain-based optimization despite real compute limits, made a technically dense system feel approachable for non-technical users, and finalized a full end-to-end flow: upload → simulate → score → rewrite → re-score.
Ethical considerations
Because CurricuLearn touches simulated neural data and automated assessment of teachers' work, we treated a few principles as non-negotiable:
- No conflating simulated and real data: Every score in the UI is explicitly tagged as coming from our proxy model, never presented as an actual student's biometric reading. As we integrate TribeV2's real backend, this distinction will remain visible to users.
- Minimal, non-identifying data: The pipeline only ever produces coarse, named metrics (e.g., "cognitive load: 0.7"). In the case that we do obtain real student neural data to improve our model, we will not have raw signals tied to an individual student.
- Human-in-the-loop, not human-replaced: Claude simply suggests and rewrites. It doesn't make unilateral decisions about a teacher's curriculum or a student's ability, since teachers see why a change was made and retain full control to accept or reject it.
- Awareness of compute cost: Re-simulating a lesson on every optimization pass isn't free. We kept our proxy lightweight specifically to avoid the environmental cost of brute-force re-running large models on every iteration, and see real efficiency tradeoffs as part of the eventual TribeV2 integration, not an afterthought.
- Open questions we haven't solved yet: consent and data governance for real student neural data, and bias testing for the LLM's rewriting decisions, are both necessary before any real deployment, and we see them as our next milestone.
What we learned
We learned how to design an AI system around a real optimization loop rather than a single generation step. Hitting TribeV2's compute wall taught us to build around a stable interface so a backend swap doesn't require a redesign. We also learned to translate raw model outputs into metrics non-technical users can actually act on, and how to keep iterating on a UI for an audience.
What's next for CurricuLearn
- Integrate TribeV2's full brain simulation once compute allows, replacing our proxy with richer neural representations.
- Support more material types: lecture transcripts, videos, diagrams.
- Generate and compare multiple candidate rewrites per lesson, not just one.
- Incorporate real student feedback and outcome data to validate and improve scoring accuracy over time.
- Build out the consent and data-governance framework needed before any real neural data is used.
Built With
- anthropic
- claude
- css
- html
- javascript
- next.js
- python
- tribev2



Log in or sign up for Devpost to join the conversation.