-

-

Front Page
-
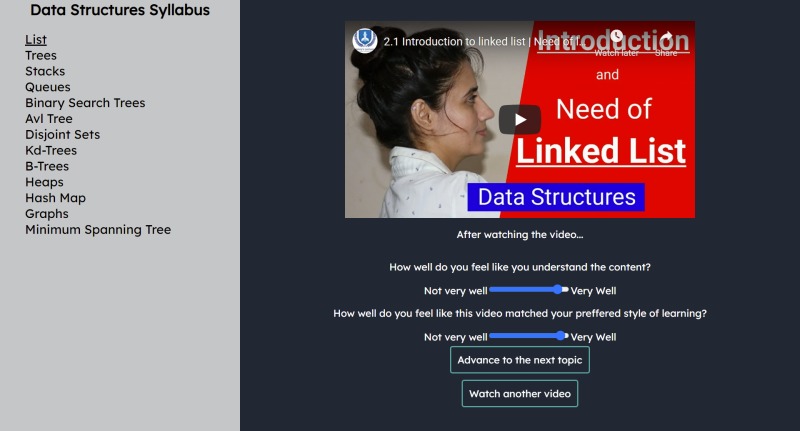
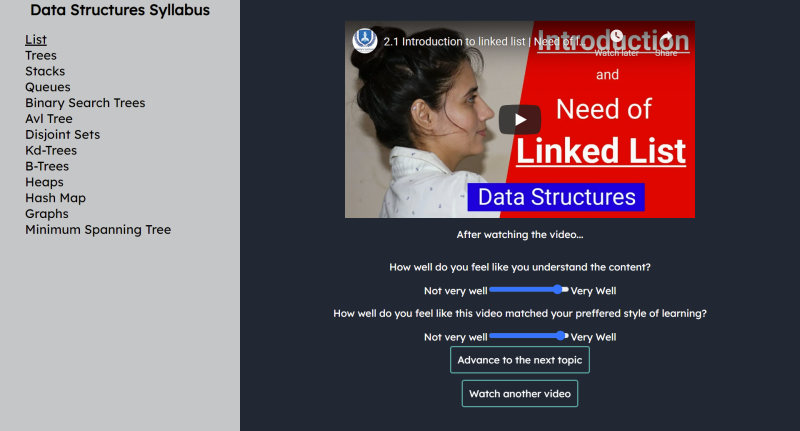
User Interface


Inspiration
With the pandemic, more educational content than ever has been uploaded to the internet for all to see, and with all these hours of free content available, it should be possible for anyone with an internet connection to learn anything they desire! However, it can be very difficult to do so as few have collated the massive amount of fresh data into a cohesive, personalized, and distraction-free curriculum. Introducing, Curio!
What it does
Curio is a service that aims to deliver the best possible online education for a student by leveraging the surge in online content during the pandemic. With several different lessons on a similar topic, (i.e. several videos on Binary Search Trees), our task is to find the best video for the individual student to help them understand the topic. To achieve this, we use a Deep Neural-Network-based recommendation system to analyze trends in student engagement with particular lessons and styles all to ultimately recommend the best videos to help an individual student understand a topic.
Let's say that we offer to teach 'Data Structures' through Curio:
- We start by manually creating a syllabus for the broad topic (Easy, since this only has to be done once)
- Next, we automatically gather youtube/MIT OCW/user-submitted/etc. videos that are related to the concepts in the syllabus (i.e. Heaps, AVL Trees)
- Now, we use our recommendation algorithm to match students to videos based on information they gave us (via a survey at signup) and based on their interactions with the videos that they watch.
- As more students watch more videos and give feedback, the recommendation algorithm gets smarter, ensuring that the students get even more relevant content!
How we built it
Our frontend is built with React, with a Flask API and a PostgreSQL database. We integrated Google OAuth2 sign in and maintain user accounts.
Our Recommendation engine is built from scratch with PyTorch. The architecture is as such: with user interactions with a video(or any other content such as homework, text articles, etc.), we assign an affinity between the user and the content. Positive affinities (0,5] are for favorable outcomes (student responds that they understand, or student doesn't request a different video on the same topic), and Negative affinities for unfavorable (confusion, requests different video). With this, we learn vector embeddings for both videos and for users by attempting to minimize the cosine distance between vectors for users and videos where the affinity was positive and maximizing it where negative. With this, we achieve a sort of collaborative separation of the videos and users by preference. (See slides for math)
Challenges we ran into
As with any recommendation system, we have the challenge of not having any user data to pretrain our recommendation model on (the 'cold start' problem). While this would be mitigated by simply having a bad model at first and allowing users to slowly train the model, for hackathon demonstration purposes, we had to generate our own synthetic data that mimics clusters of people to show what our algorithm can do.
We also attempted to integrate some natural language understanding into the vector embeddings for the videos, however, this proved to be too difficult a task within the time frame as the length of the video transcripts exceeded 10,000 words in some cases, which would take too much time to parse.
A big part of our data collection algorithm and process leverages resources on the web, and is able to pull from multiple sources including MIT OpenCourseWare, 3Blue1Brown, BlackPenRedPen, HackerRank, and other channels in order to correctly validate that the video is of high quality. We take into account the user metadata for each video in order to efficiently curate a playlist on the topic of the user's choosing. This part was especially hard as we had to pre-process the data for the videos to make sure it could be parsable by our engine.
On the UI side, we implemented an Account Management service that allows users to store their credentials in order to access their course content at any time. This part was especially difficult surrounding the database management on the backend and the need to safely store private user information. Google OAuth2 authentication required a bit of a learning curve for us, and the integration with Flask, a Python API library, meant that countless hours of our 36 hours were spent trying to understand a new tool we haven't yet used before.
Although we spent the majority of the hackathon look at new API's and services to work with, we felt that the knowledge gained was incomparable to the time lost, as we made grade strides to be able to almost fully flush out a minimum viable product for this hackathon.
Accomplishments that we're proud of
Our good code design philosophy and style means that this project can be carried on and improved in the future without much significant work. The documentation for our code is almost complete, and any new user to our code base should be able to understand what is going on. We are very proud of making both our code relatively fast during execution, as well as readable to encourage the public to use bits and pieces of our projects in whatever endeavors they might have going on.
Of further note is that during this time of stress from both Covid-19 and schoolwork, we as a team were able to get together and flush out a minimum viable product during the hackathon that hopefully will be used in the future to help benefit learners during this time of social distancing. Without complete access to resources, and with much time on one's hand, any person can start an account with our application and proceed to learn just about any topic imaginable using our flexible syllabus and course design.
"""
This script is used to query the Youtube API using the python-youtube
package in order to retrieve all relevant youtube data and stores
it in a json.
Make sure you have downloaded the required packages by doing:
pip install --upgrade python-youtube
pip install youtube_transcript_api
"""
from pyyoutube import Api
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_channels import Channel
import json
import copy
class Video_Search_Json:
"""Class to retrieve videos
This class helps query and search our video database
using an API YouTube key if needed to pull from Youtube.
Automatically updates the json file.
"""
def __init__(self, API_KEY, JSON_PATH):
# Declare an API object using our API_KEY
self.api = Api(api_key=API_KEY)
self.data_path = JSON_PATH
with open(JSON_PATH) as f:
self.database = json.load(f)
def search_by_keywords(self, subtopic, channels=[Channel['MIT']], num_videos=10, force_query=False, include_transcripts=True):
"""Searches for videos by subtopic
Takes in a query string to search for on youtube.
Returns a JSON.
...
What we learned
While brainstorming for our application and coding parts of it, we realized a lot of what the user might want as part of the application, and we were ecstatic to be able to include these bits in our project. Some ideas we came up with while coding included adding an account management system for our clients, as well as implementing a reactionary video recommendation algorithm based off of the user's preferences, previous watch history, and their affinity towards different videos. We learned to walk through our application from end to end in a user's point of view to best maximize how our application can impact learners and best deliver content so our users can focus on learning the content.
What's next for Curio
Currently, our recommendation engine is largely unaware of the content of the things it is recommending; it just uses how certain users reacted to it as a metric. This leaves possibilities for both expanding the type of content(allowing written articles, homework problems, etc.) and leaves the potential for integrating an NLP engine for video transcripts and written articles to get a better idea as to what causes some content to be recommended.
We are planning on fixing a couple bugs here and there as well as getting more training samples and data from our users who will be using our site. We want to make sure that our algorithm is inclusive to everyone and delivers the best content to maximize education and understanding. We also want to improve our codebase to be more legible in order to help encourage other people to use the tools we have made in this hackathon.
Concerning our social impact, we want to host our application on a live server and open this to the world so that during this time, those who want to can get a personalized any-topic learning curriculum curated for their needs that mathematically maximizes the effectiveness of the education so that one can come out of quanrantine and Covid with more knowledge of a myriad of topics and a deeper understanding of old subjects.
To the reader...
If you've read this far, I want to thank you for sticking by us and I hope you find our project interesting. If this is something that interests you greatly, please go and star our repository so you can get updates and help contribute to elevate learning to the next level.
Built With
- api
- artificial
- deep
- flask
- intelligence
- json
- machine-learning
- natural-language-processing
- net
- neural
- pandas
- postgresql
- python
- pytorch
- react
- sql
- youtube




Log in or sign up for Devpost to join the conversation.