-
-
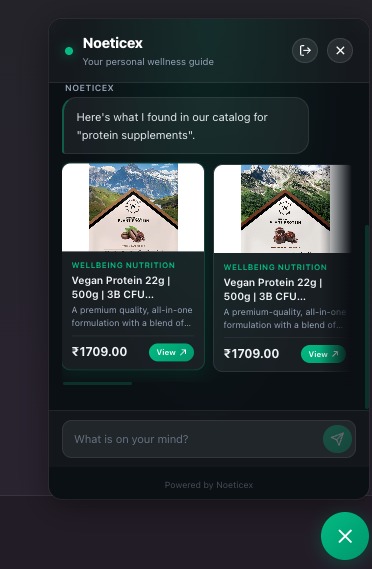
Chatbot product view
-
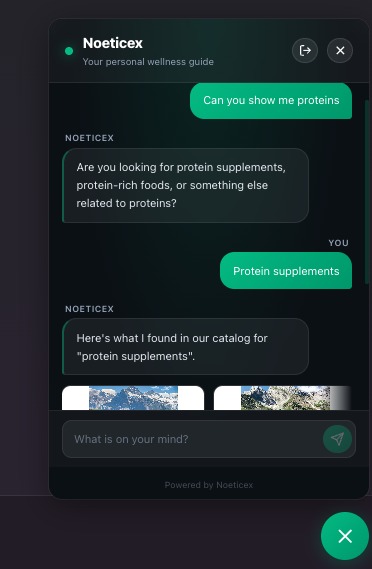
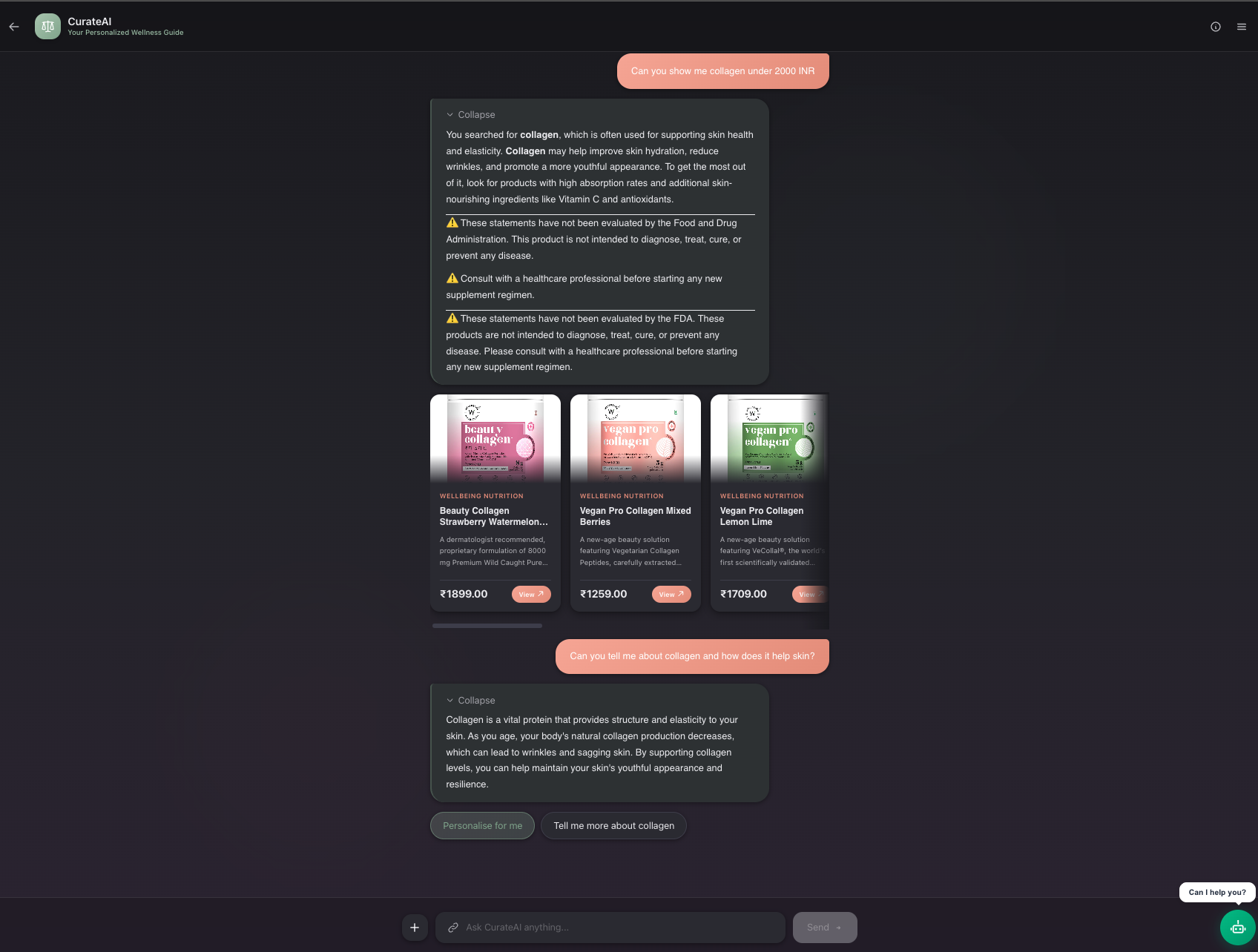
Direct search on chat bot
-
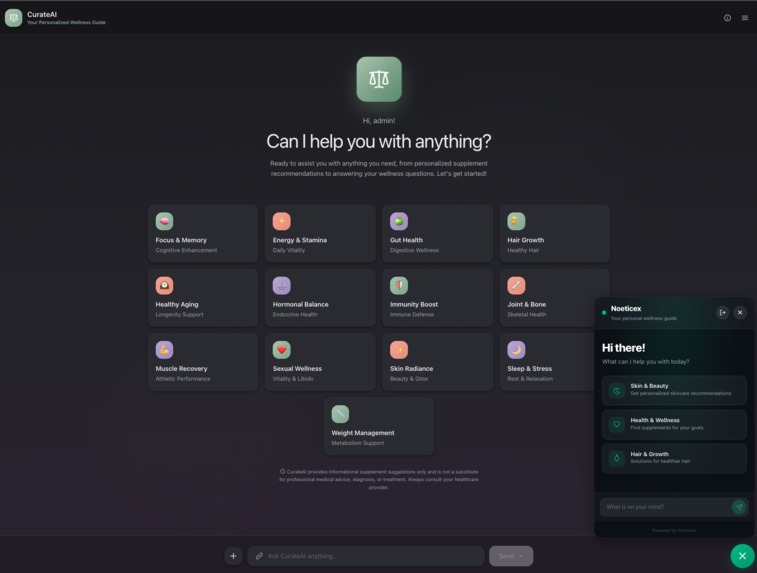
Home page with the chatbot. The idea is to have the main website for all products and chatbot to be integrated externally
-
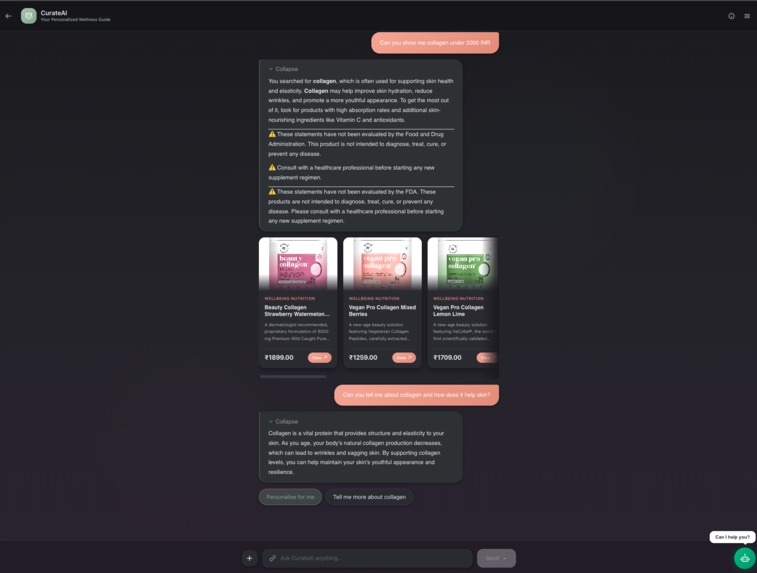
Direct search component
-
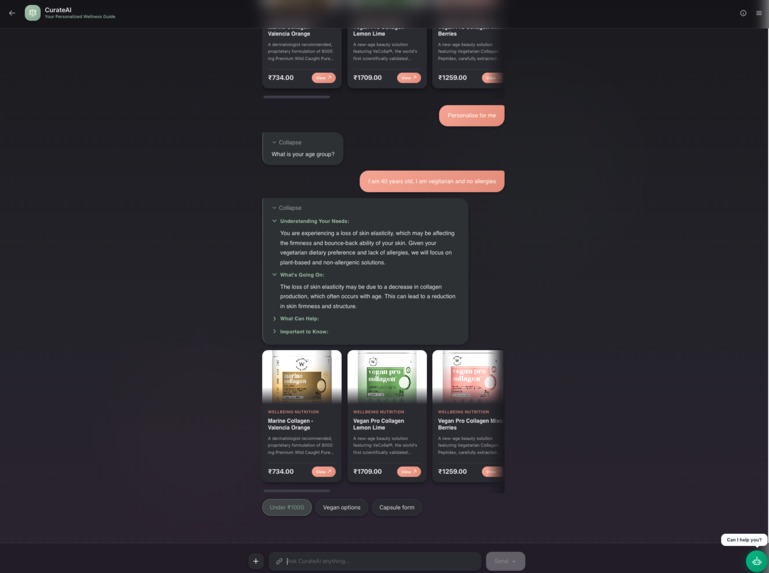
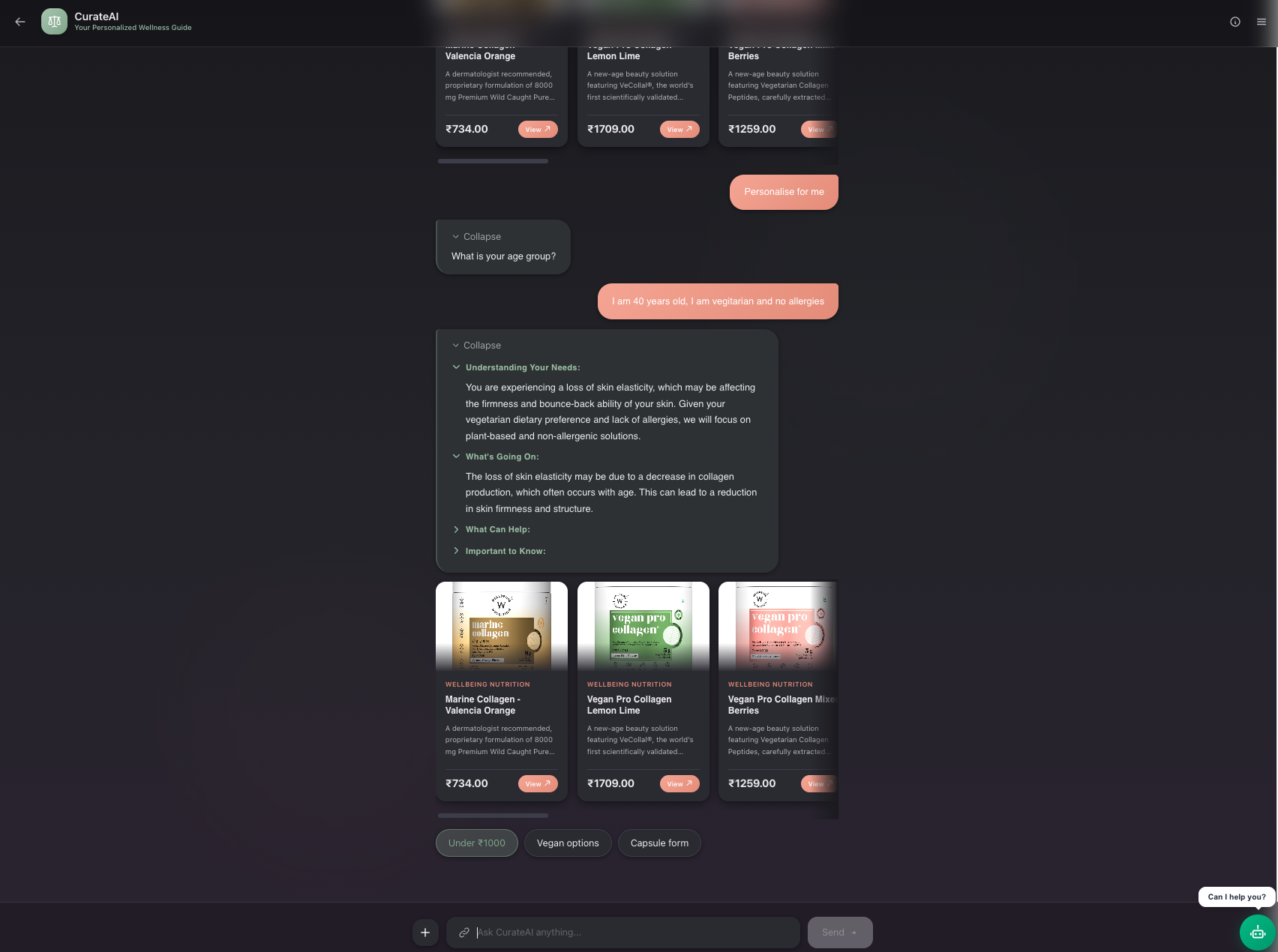
Personalised product search with a compound customer response
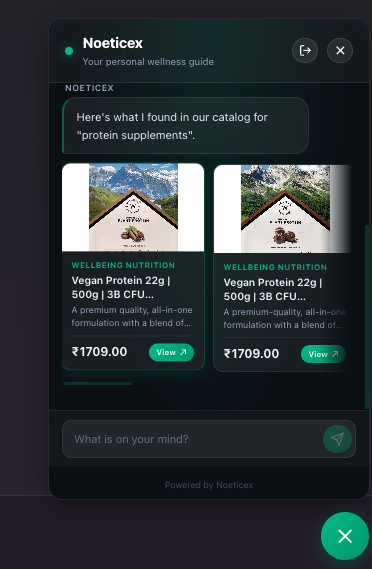
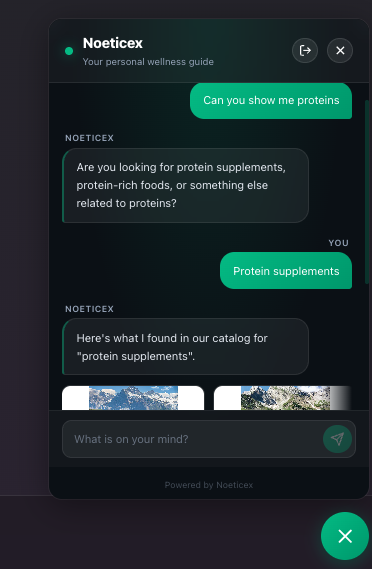
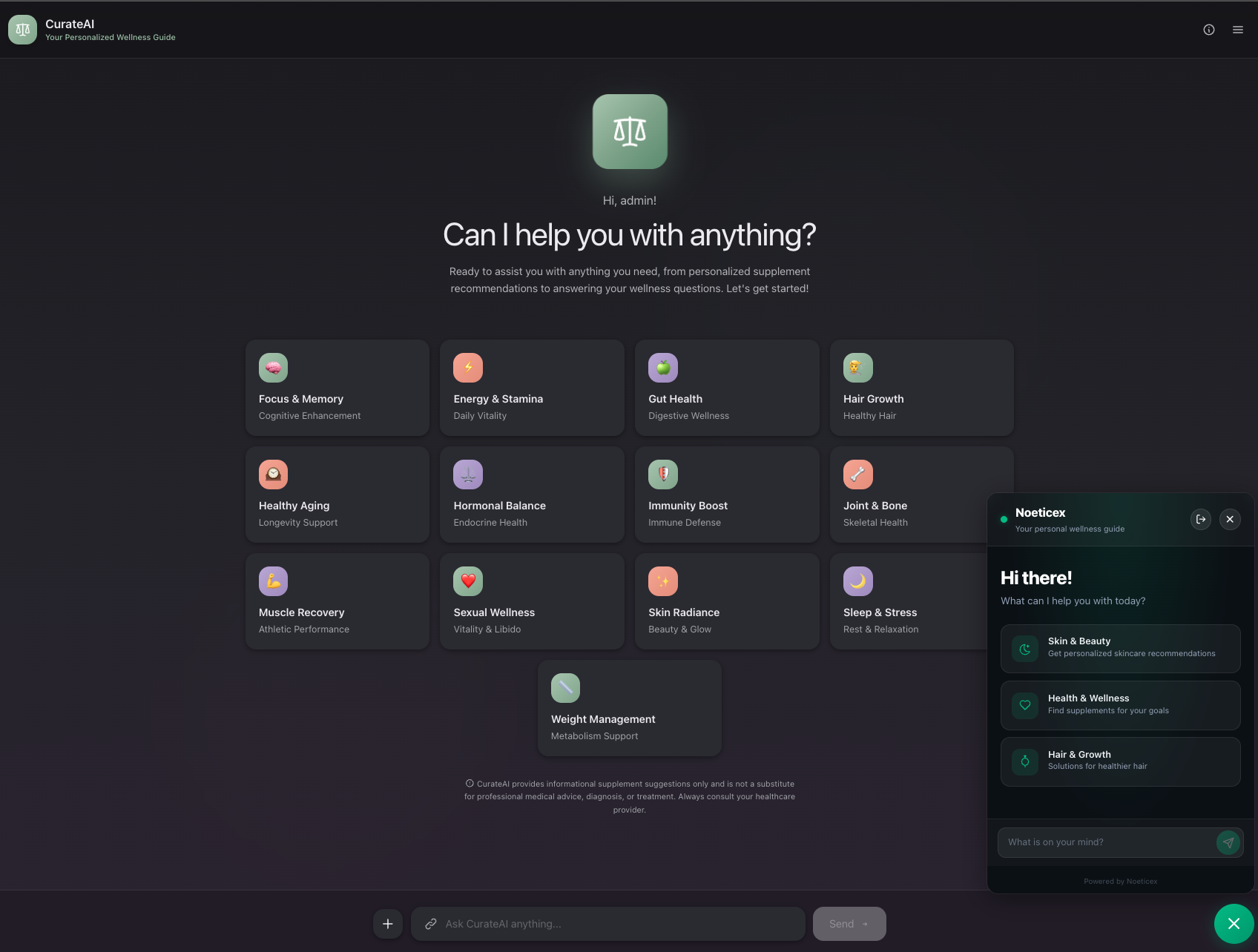
Inspiration
Online supplement stores throw hundreds of products at you and expect you to figure it out. Users end up overwhelmed, scrolling through pages of options with no way to know what's actually right for them. We wanted to flip that — instead of browsing, you just describe your concern and have a short conversation. The system figures out what matters, asks only what it needs, and gives you personalized picks in seconds.
What it does
CurateAI is a conversational AI that recommends products through a short, focused consultation. A user says "I need help with low energy," sees instant relevant picks, and can optionally answer 2 quick questions (diet, allergies) to get personalized results filtered to their exact needs. It handles follow-ups too — say "I also have a fish allergy" after seeing results, and it re-searches with that constraint applied as a hard filter.
The system covers multiple wellness domains (energy, skin health, sexual wellness, brain & focus) and gracefully handles out-of-scope requests through a fallback discovery flow.
How we built it
Five specialized AI agents work together in a LangGraph state machine:
- Router classifies intent and maps it to a domain using knowledge graph synonym matching
- Interviewer asks up to 2 personalisation questions, ranked by search impact — attributes that create hard SQL filters (diet, allergies) are prioritized over soft reranker-only constraints
- Search Architect builds ingredient-aware queries using a knowledge graph, boosting ingredients recommended for the user's specific attributes, then runs hybrid vector + SQL search via pgvector
- Reranker filters results against user constraints (budget, contraindications)
- Safety adds medical disclaimers and screens for contraindicated ingredients
The knowledge layer is a set of YAML-defined domain graphs (NetworkX) encoding problems, ingredients, attributes, and their relationships (TREATS, RECOMMENDED_FOR, CONTRAINDICATED_FOR). This drives both question selection and search query construction.
Stack: FastAPI, LangGraph, AWS Bedrock (Claude 3.5 Haiku + Titan Embeddings), PostgreSQL + pgvector, Docker Compose.
Challenges we ran into
Question fatigue vs. recommendation quality — Early versions asked 5-6 questions before showing any products. Users dropped off. We solved this by showing initial products immediately after problem identification, then capping personalisation at 2 questions ranked by actual search impact rather than a fixed priority order.
LLM output unpredictability — Structured output from the LLM sometimes returned empty dicts, wrong key names, or JSON strings instead of native types. We built a shared validator layer and added sensible defaults to every required field to make the system resilient to partial responses.
Constraint key mismatch — The refinement agent extracted allergy info under arbitrary keys ("allergy", "fish_allergy") that the search filter builder couldn't read. We had to add explicit key-name guidance in prompts to ensure end-to-end compatibility between agents.
Graph data gaps — Some problems had no REQUIRES_KNOWING edges, meaning the interviewer had nothing to ask. Rather than crashing, the system gracefully asks whatever global questions exist and proceeds to search.
Accomplishments that we're proud of
- Zero to personalised results in under 10 seconds — initial products appear instantly, full personalised results after just 2 questions
- Knowledge graph-driven intelligence — questions, ingredient boosting, and safety screening all flow from the same graph structure, making it easy to add new domains by writing YAML
- Graceful degradation everywhere — empty LLM outputs, missing graph edges, out-of-scope queries, and post-completion refinements all have clean handling paths instead of crashes
- Search-impact ranking — the system mathematically determines which questions matter most for search results rather than relying on hardcoded priority orders
What we learned
- Show results early, personalise later — users engage more when they see something useful before being asked questions
- Fewer, smarter questions beat comprehensive profiling — 2 high-impact questions produce nearly the same result quality as 6, with far better user experience
- Multi-agent systems need explicit contracts — when one agent's output is another agent's input, implicit assumptions about field names and formats break silently. Explicit schemas and key-name guidance in prompts are essential
- Knowledge graphs and LLMs complement each other well — the graph provides deterministic structure (which ingredients treat which problems, which attributes create filters) while the LLM handles the fuzzy parts (understanding user intent, generating natural questions)
What's next for CurateAI
- More domains — expand beyond wellness into electronics, home & living, and other verticals by adding new YAML knowledge graphs
Built With
- amazon-web-services
- docker
- fastapi
- langchain
- langgraph
- pydantic
- python
- sqlalchemy


Log in or sign up for Devpost to join the conversation.