


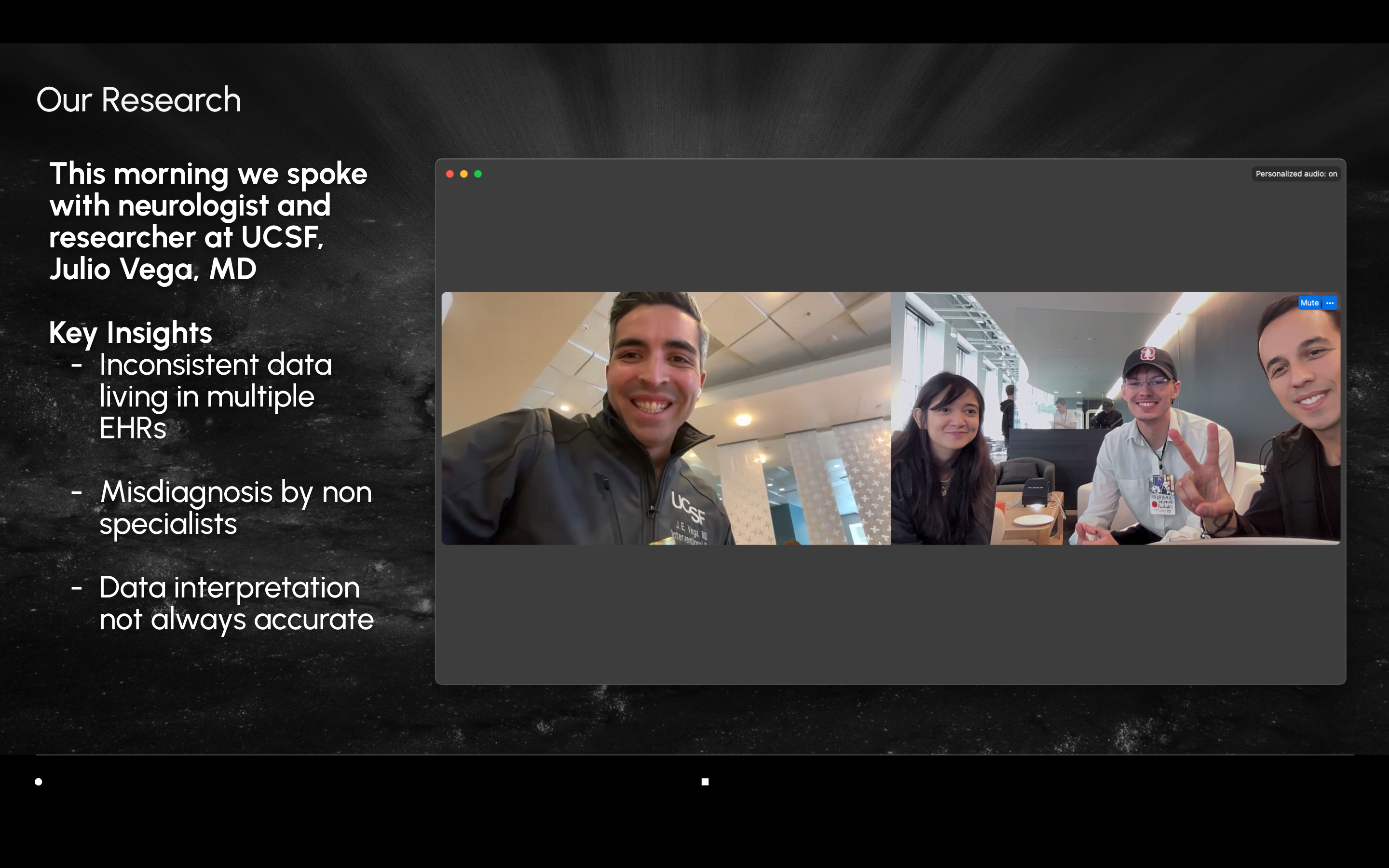
Inspiration: We were inspired by the inefficiencies in clinical trial recruitment, particularly for complex conditions like brain tumors. Researchers often spend weeks manually reviewing fragmented medical records, only to miss eligible patients due to inconsistent terminology and limited data access. We wanted to make it possible for researchers to simply talk to their data.
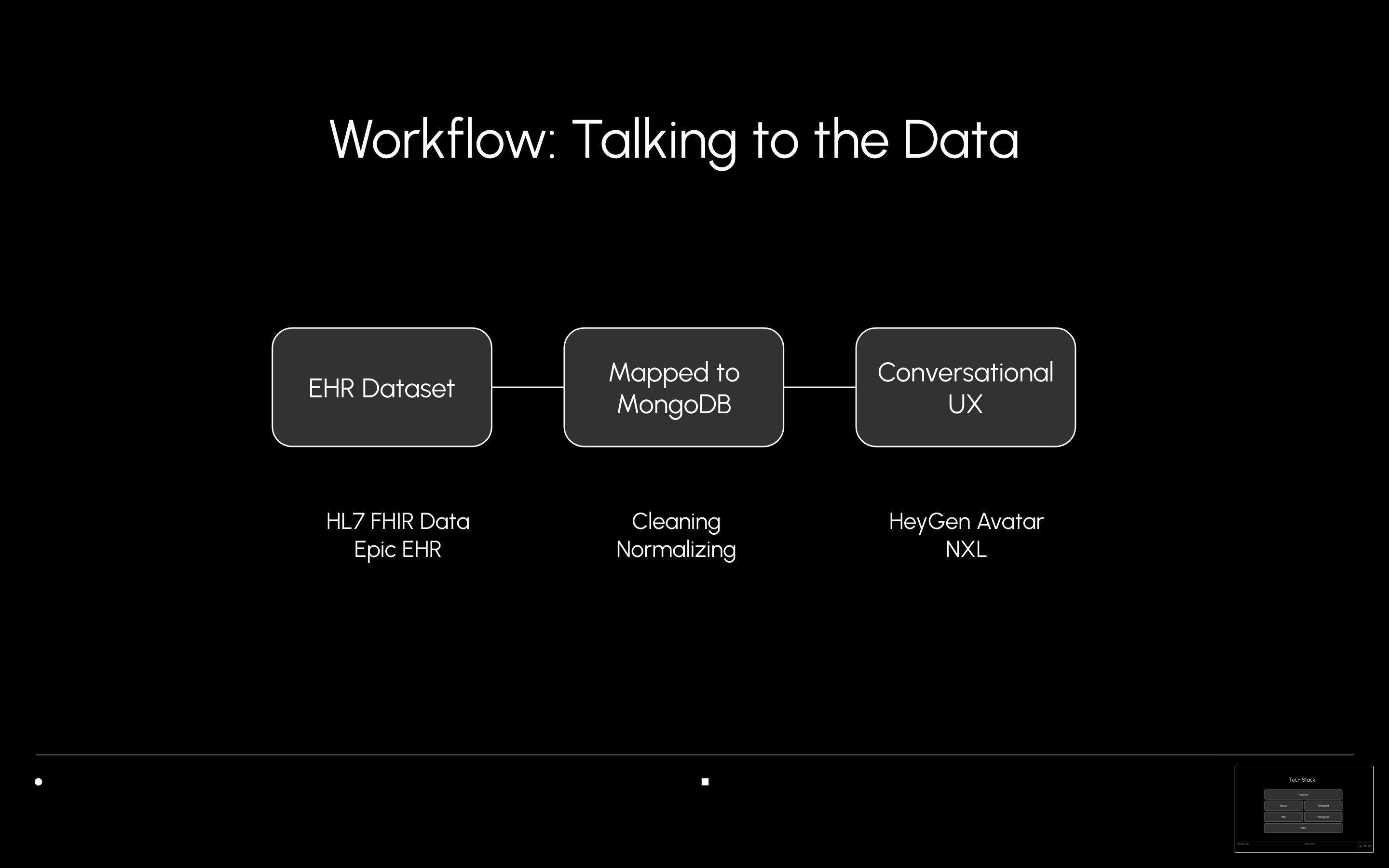
What We Built: We developed an AI-powered patient screening assistant that enables researchers to query structured clinical data using natural language. The system interprets prompts like “Find patients with glioblastoma under 60 not on anticoagulants” and returns matched patients by generating structured MongoDB queries in the background.
Our backend uses synthetic patient data formatted in a FHIR-like structure and normalized with SNOMED codes. The system is powered by MiniMax LLMs and orchestrated with Wiz, while the interface is delivered through a HeyGen avatar to create an intuitive user experience.
What We Learned: How to model clinical data using HL7 FHIR standards
Techniques for normalizing diagnosis terms across SNOMED codes
Prompt engineering for translating freeform queries into structured filters
Managing data privacy and controlled access in cloud-based infrastructure
Challenges We Faced: Mapping inconsistent medical terminology to standardized codes
Designing flexible but safe filters for patient eligibility logic
Connecting real-time natural language input to backend query execution
Ensuring data remained secure, queryable, and interpretable within time constraints
Future Work: We plan to integrate longitudinal records, support multilingual queries, and explore deployment in real-world clinical research settings with appropriate ethical and data compliance protocols.
Built With
- amazon-web-services
- heygen
- mongodb
- senso
- temporal
- wiz

Log in or sign up for Devpost to join the conversation.