-
-
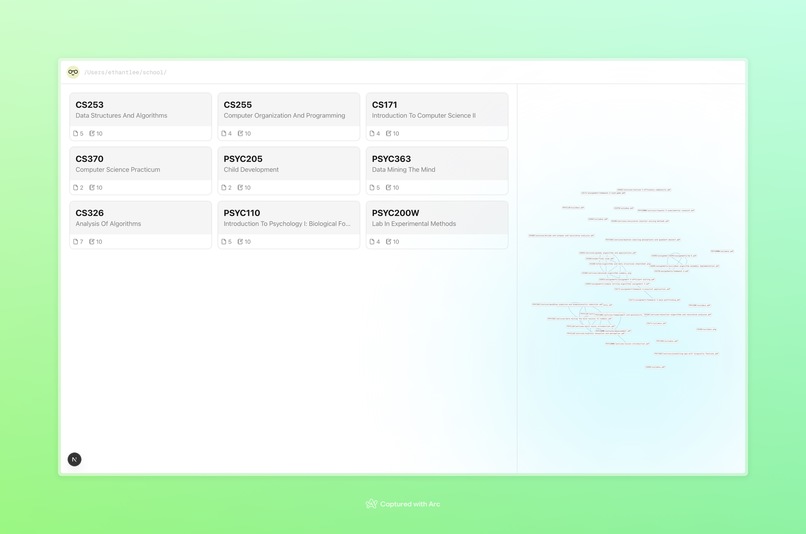
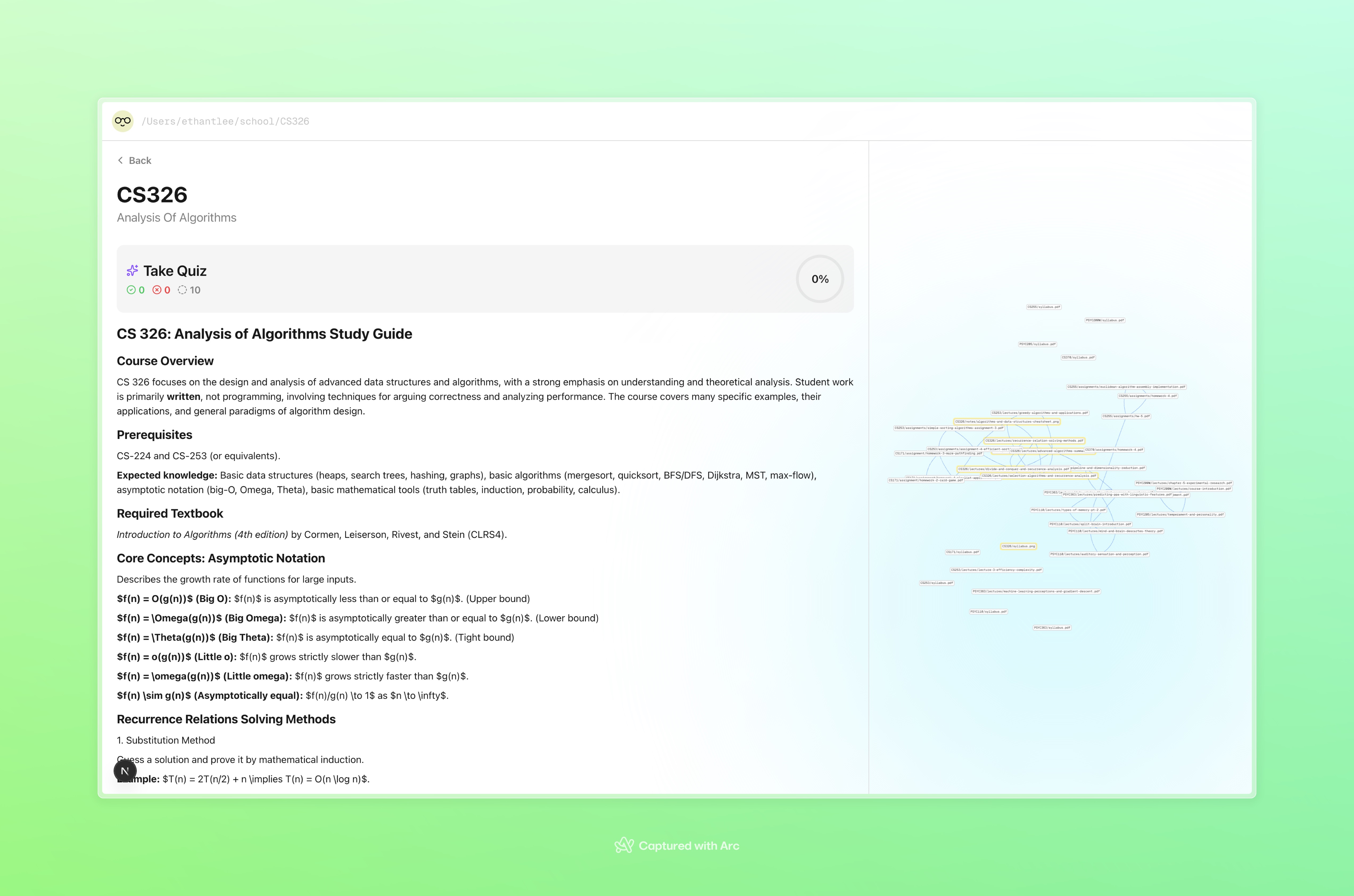
course overview
-
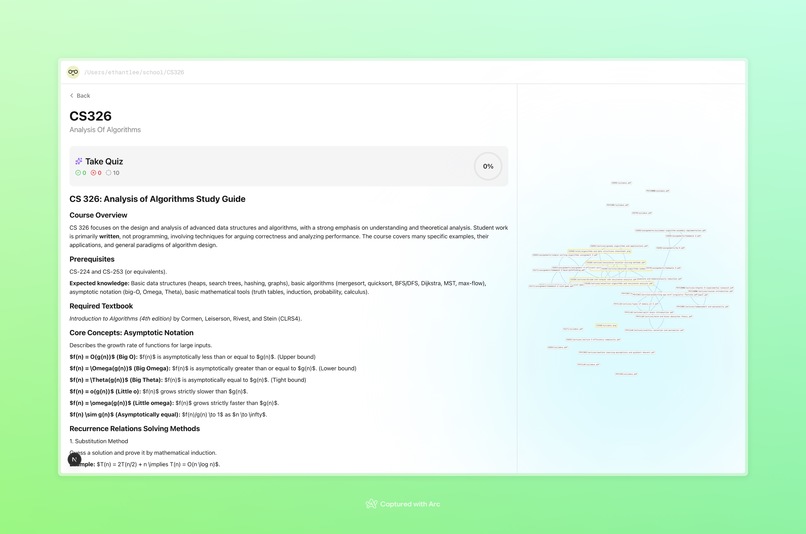
course detail and study guide
-
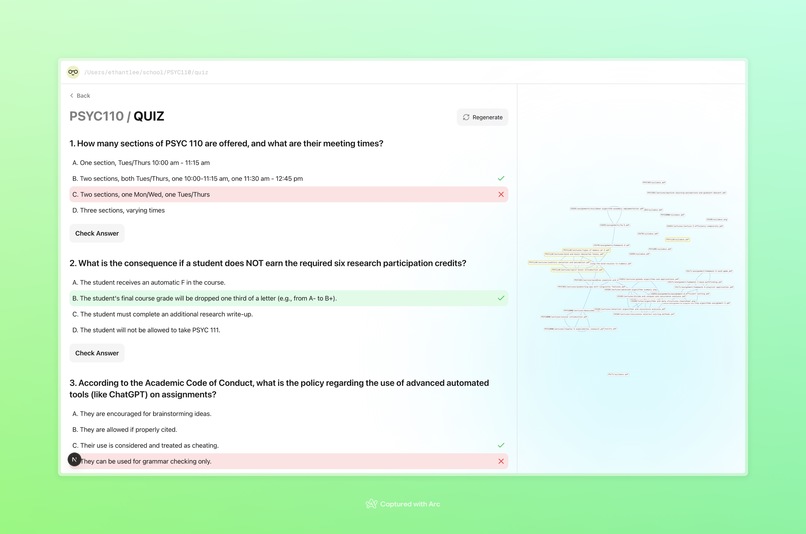
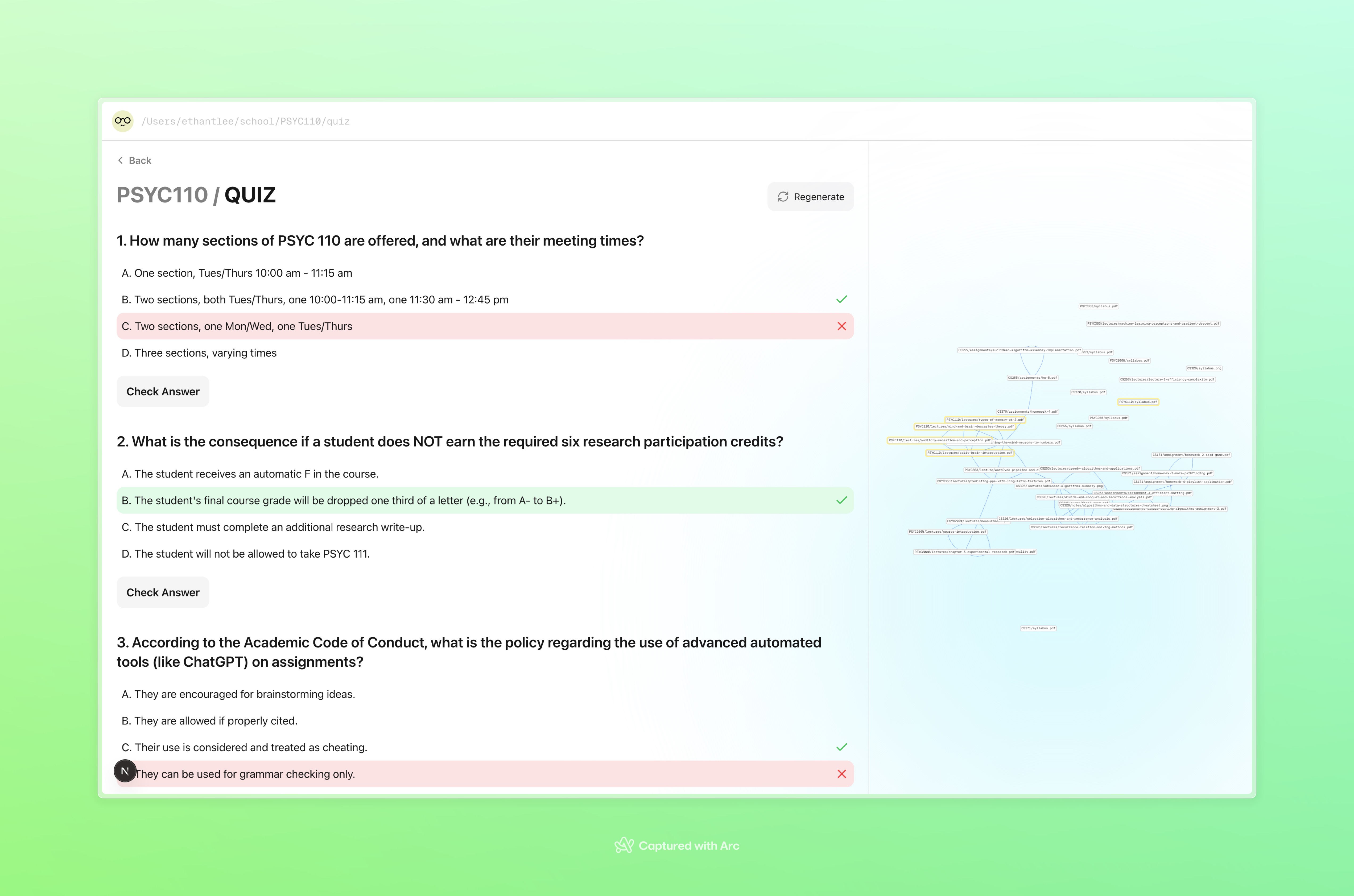
quiz
-

gobin
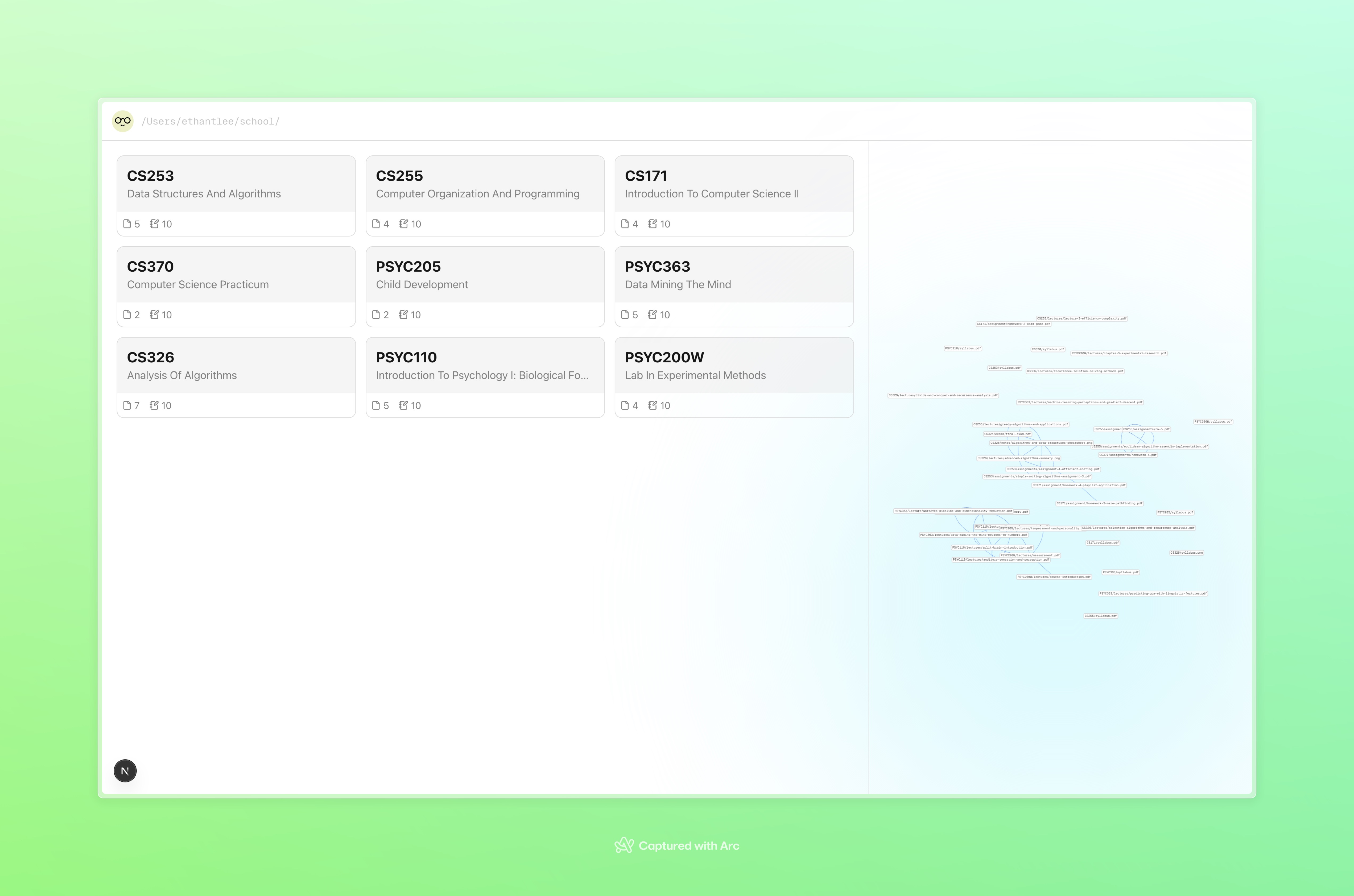

Inspiration
As students, we've all faced the chaos of our computer overflowing with slides, lecture notes, assignments, pictures of whiteboards and screenshots scattered across devices and buried in the downloads folder. When a quiz or a test approaches, that disorganization quickly turns into panic, inflicting stress and uncertainty of what to focus on. To combat this, we built Curaitor, a powerful agent that can automatically organize files and turn the passive notes into interactive quizzes, up-to-date study guides, and knowledge graphs. We attempt to bring education to life, where scattered information becomes structured knowledge and learning truly clicks for all.
What it does
Curaitor is a centralized study system. Instead of wasting time sorting files manually, students can drag and drop all their course materials into a single folder. Curaitor continuously monitors that folder, detects new files, and organizes them by course and file type. Our web UI allows students to display each course, its associated materials, and their relationships. Course content is processed in three major ways: Quizzes - 10 multiple choice questions that test understanding with instant feedback Study guides - Comprehensive summary that highlight notable topics from each course. Knowledge graphs - An interactive visualization that connects related files and concepts even across courses, which reinforces high-level conceptual learning. By combining organization with active learning tools, Curaitor creates an engaging learning environment without manual effort.
How we built it
Our backend written in Go features high concurrency and performance. It utilizes Google Gemini API to organize the user's files, generate study guides, and quiz questions. To maximize performance of LLM, we implemented the Actor Model to deploy multiple Gemini API clients concurrently and independently as goroutines. Each actor has distinct roles (e.g. quiz generation, study guide generation), all communicating via channels. This allows the backend to be highly dynamic and responsive to the user’s interaction. We cached generated data locally so that it remains persistent across multiple program runs. Finally, the frontend built with Next.js, Typescript, and React presents the data intuitively and interactively.
Challenges we ran into
The most challenging part was managing concurrent workers. Our backend continuously reads a directory and writes to another, while generating new quiz and study guides with the latest data on the side. We spent a lot of time discussing the architecture to avoid race conditions and minimize inefficiency. Reflecting this highly dynamic data on the frontend and translating them to effective learning tools was also a great challenge.
Accomplishments that we're proud of
We were able to successfully connect our backend and frontend built in different languages in a short amount of time! It is always exciting to watch our program magically process and organize a large amount of unsorted files. We’re also proud of surviving the sleep deprivation and homesickness!
What we learned
Our understanding of the Go language and concurrency advanced greatly. Having read a copious amount of Gemini API documentation we learned to use Gemini Go SDK and got to explore many ways of handling large data. We also experimented with cool animations and visualizations with Next.js and Tailwind CSS.
What's next for Curaitor
We would love to implement a feature where users can not only see if their answers to the quiz were right or wrong, but also receive subsequent quizzes that hone in on their weak points. We also would like to work on the code even more to provide study guides for specific sections instead of the entire class a whole.
Built With
- docker
- geminiapi
- go
- next.js
- react
- typescript








Log in or sign up for Devpost to join the conversation.