-

App Logo
-

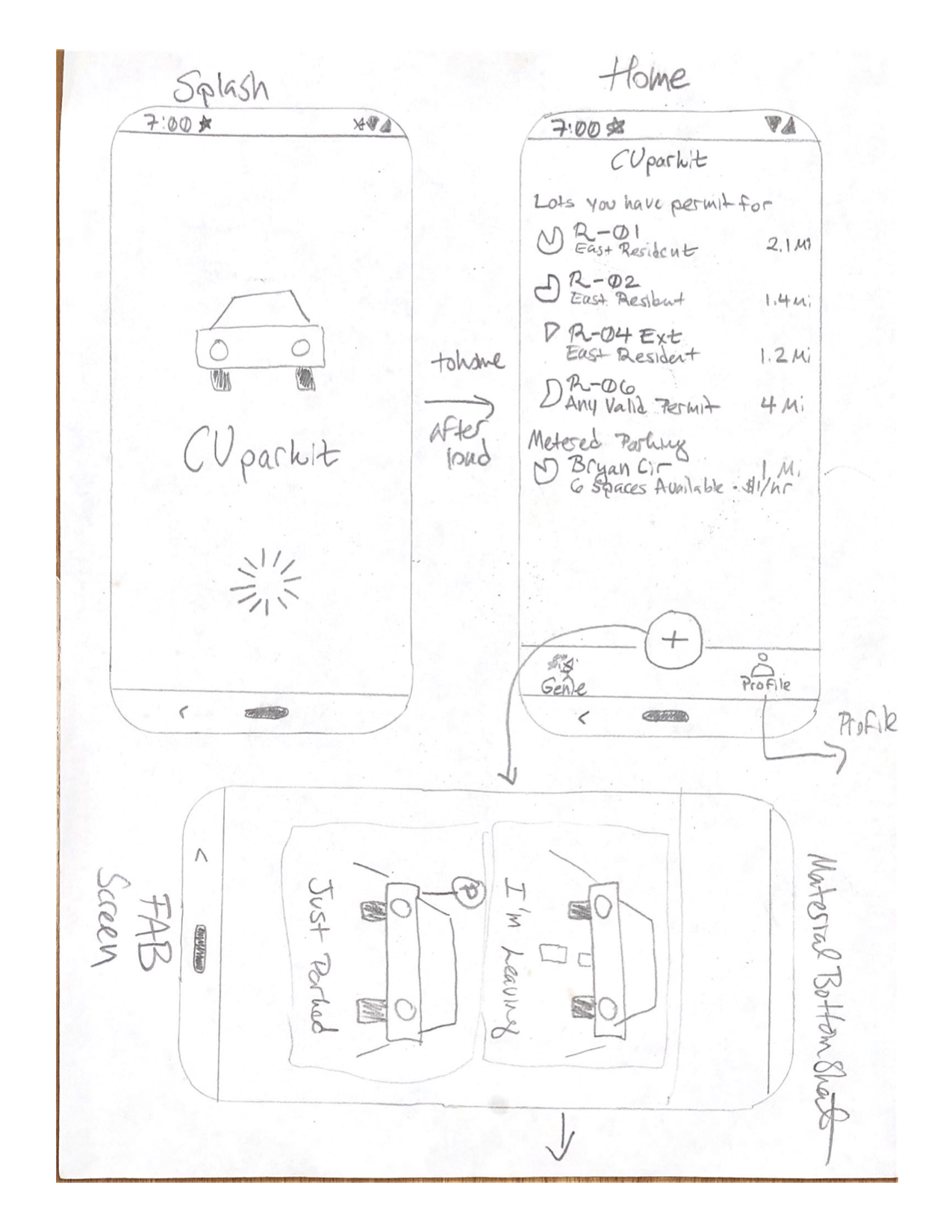
App Design Sketches

Inspiration
Looking for a place to park on Clemson's campus can be an arduous and time consuming task—it's no good to still be circling the parking lot at 10:00 when your class started at 9:30. Getting to the right lot at the right time is simply the result of good guesswork and lots of hope—unless you know when and where to be. CUhackit, meet CUparkit.
What it does
CUparkit is a hybrid predictive system that combines forecasts about parking lot availability from a machine learning model with live crowd sourced data. This data is presented in a lightweight progressive web app that adds to the model forecasts by allowing users to self report the status of various parking lots on campus.
How we built it
The backend was built using Python with pandas, numpy, and keras for data processing and model development. Python scripts for training and prediction interfaced with a Firebase database to both provide newly updated predictions for all parking lots as well as pull crowded sourced data to retrain the model and produce better predictions.
The frontend progressive web app was constructed in Angular.js and hosted through GitHub pages. It utilizes Material Design elements in a combination of HTML, CSS, and JavaScript. It pulls information about parking lots and predictions from the database and populates a clean, navigable view for the user.
Challenges we ran into
We ran into challenges in the development of both the frontend and backend services. In the backend, we had trouble cleaning and merging the data from two different datasets. This set us back and required us to remove the use of weather data in our model. This weather data would have further trained the model to increase the specificity of its predictions. Frontend challenges with data handling also caused a time set back, however we continued to work through these issues by prioritizing the MVP while still keeping the usability of the interface a priority. In the end, we were not able to implement our complete user reporting feature or icon and design plans, although the app does receive updates from the machine learning model.
Accomplishments that we're proud of
We pleased and proud be able to train and implement a custom machine learning model that interfaces with a database to provide relevant information through an accessible web app.
What we learned
Data preprocessing can often be very time consuming—a good amount of time was spent sanitizing data to feed into the machine learning model. Additionally, we learned to balance time between debugging roadblocks and moving forward on another path.
What's next for CUparkit
We hope to continue to break out more data to the user via our web app views and as we begin to collect crowd sourced data will be continue to retrain our model and improve predictions that are tailored for Clemson parking lots. Further, we will add more data about individual parking lots so users can tailor the homepage of the web app to display parking lots that best fit their needs, whether they be to get to the right class or the availability of accessibility services.






Log in or sign up for Devpost to join the conversation.