-
Dashboard without tweets
-

Tweet
-
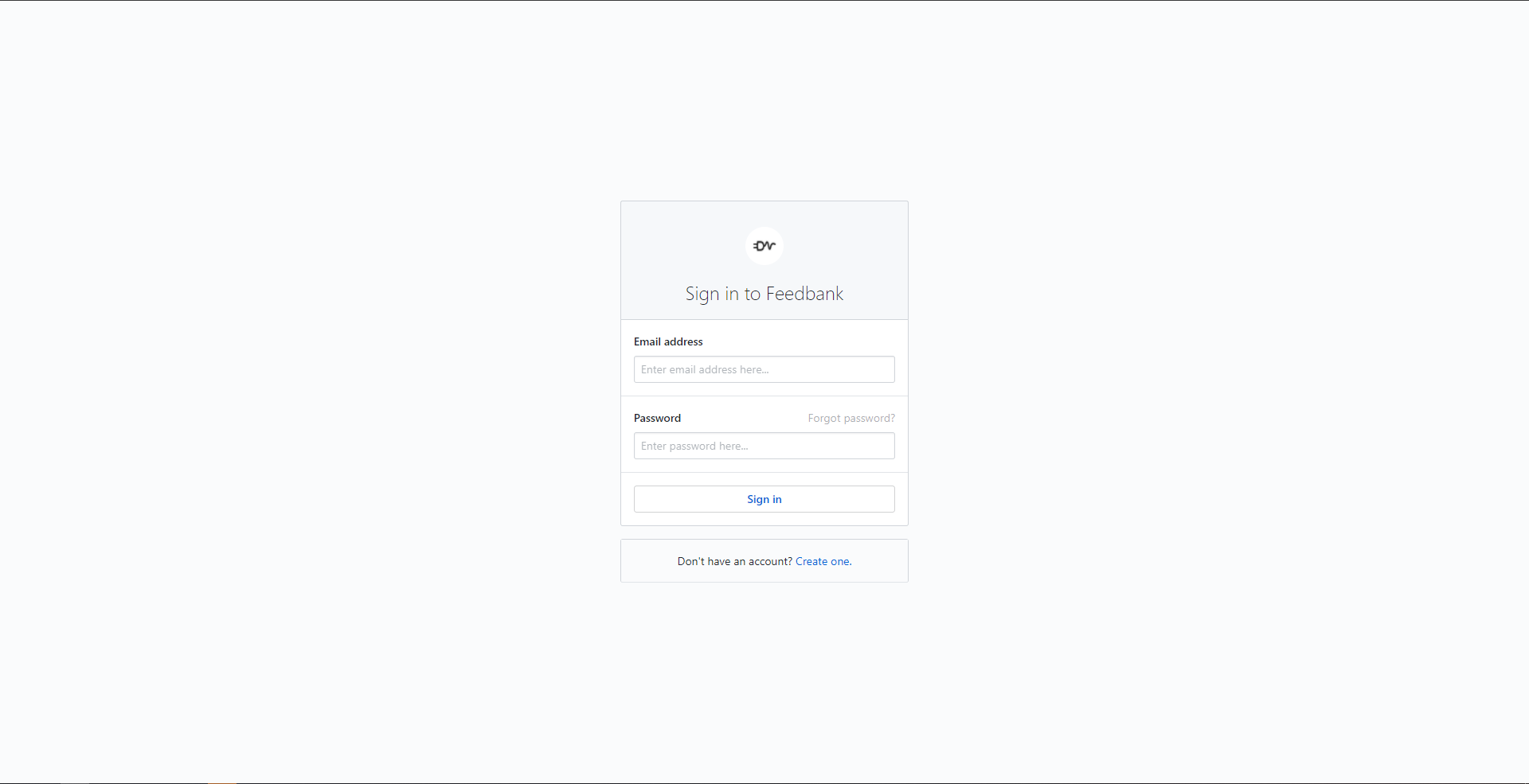
Sign-in
-
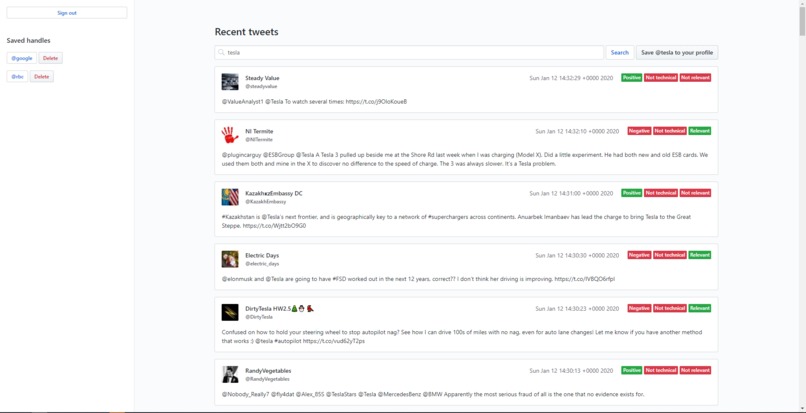
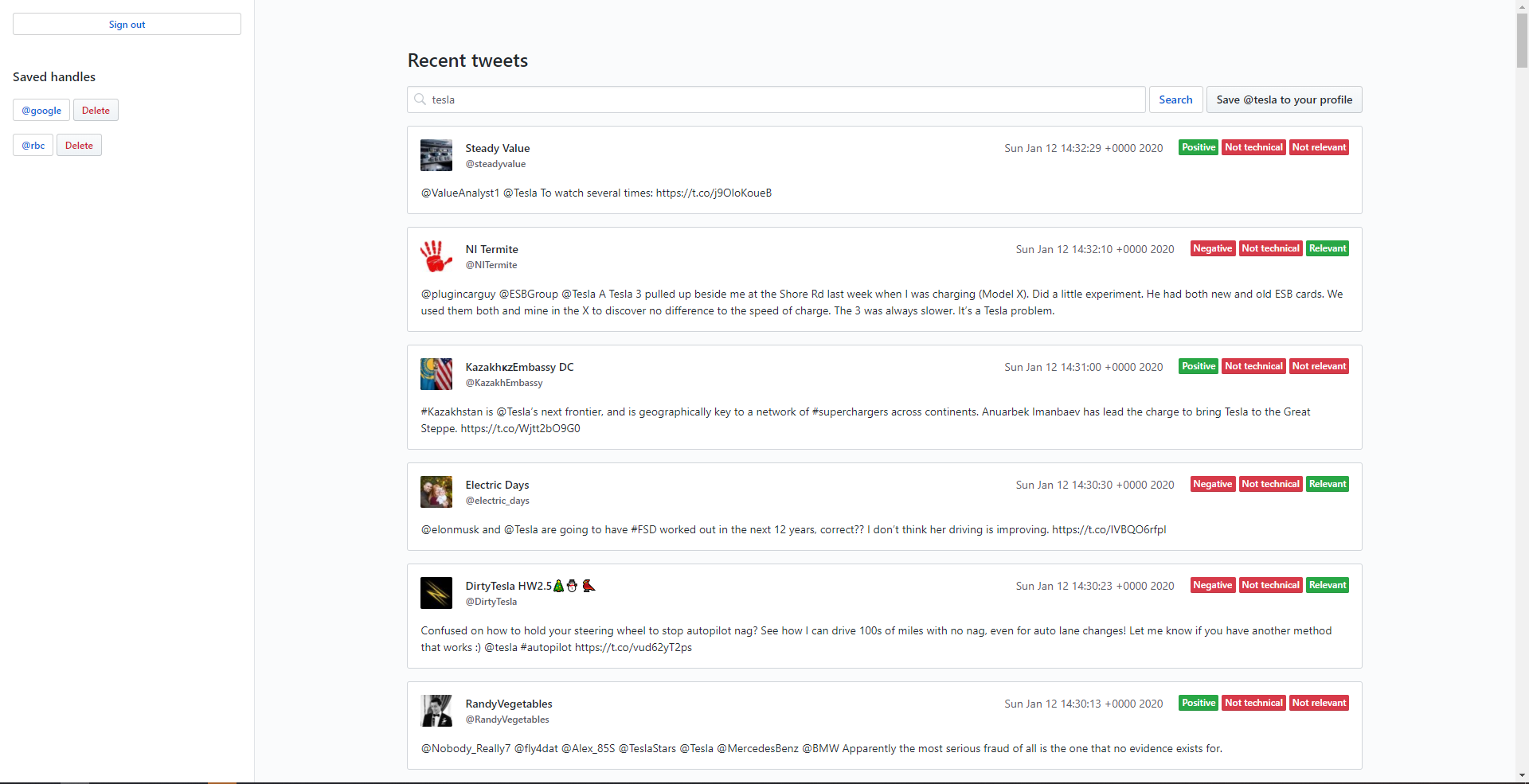
Dashboard with tweets

Inspiration
We decided to pursue this project as it was a specific sponsor challenge at the hackathon. Additionally, members of this team have a common interest in building solutions that leverage the power of Machine Learning, and all have a passion for FinTech.
What it does
Feedbank uses the twitter api to retrieve tweets based on a query. Once the tweets are retrieved, we send the text data to the Python script that is running the machine learning model. The model ran inference on each tweet that was sent, and the result was sent back to the node script. Based on the result from the inference, Feedbank adds tags to each tweet, and displays them so the business can see all of the feedback.
How we built it
Dataset populator: Created a 3 step process that converts twitter data into a dataset that can be used by three machine learning models that learn off of the three corresponding parameters. Positivity vs negativity, technical vs non-technical, and the relevancy of the data. This was accomplished using 3 Python scripts. The first converted twitter API json files to CSVs. The second was a command line tool we wrote to allow us to fill in the necessary data for each tweet. The last one sorted and formatted the data according to the input specifications of the machine learning model.
Machine Learning model: Once the dataset populator was complete, we ran some data normalization techniques to make the dataset uniform. The techniques used to normalize the data were removing stop words (in, of, at, etc), lemmatization, and n-grams. The model architecture is a Support Vector Machine (SVM), which is very common in classification problems such as this one.
Website: The web application was created using the MEAN stack. MongoDB was used to store user profiles which contain information such as; email addresses, and saved handles. A REST API was created using express.js to serve tweet information to the frontend. This REST API was also useful when creating CSVs as it gave easy access to a large amount of tweets. Firebase was integrated with Angular to allow for secure email/password authentication.
Challenges we ran into
The first challenge occurred on making sure that raw json files do not contain string that will change formatting to something that’s not convertible (like “\n”). We needed to find all the possible key strings and erase them before they were loaded as a dictionary.
Tensorflow was not able to install (as we were using an older version and was needed to update to a newer version) , instead, scikit-learn was used to create and train the machine-learning model Our team had different versions of Python, which caused some issues interfacing the Javascript and Python code using PythonShell
There was no established datasets that we were able to use to train the model. Instead, we had to create a dataset populator ourselves and manually enter a boolean parameter for each tweet that would then be used to train our model.
Accomplishments that we're proud of
Fluid method of converting raw Json objects of tweets to data that can be fed to the model
We were able to achieve 80% accuracy on the current model that is for RBC tweets. Additionally, we were able to achieve up to 90%+ accuracy on established datasets for similar tasks (IMDB movie classification)
Very modular class for the machine learning model will allow for scalability in the future
Simple, intuitive, and easy to use UI
What we learned
As a group we learned a new machine learning architecture that will potentially help in future projects.
Learned CSV input, output and specific CSV file manipulation using Python
Some of our team members learned Git
What's next for Feedbank
Expand target companies to other companies
Refactor the codebase.
Sorting by tag to allow for easier consumption of tweet data.

Log in or sign up for Devpost to join the conversation.