-

Cuala
-
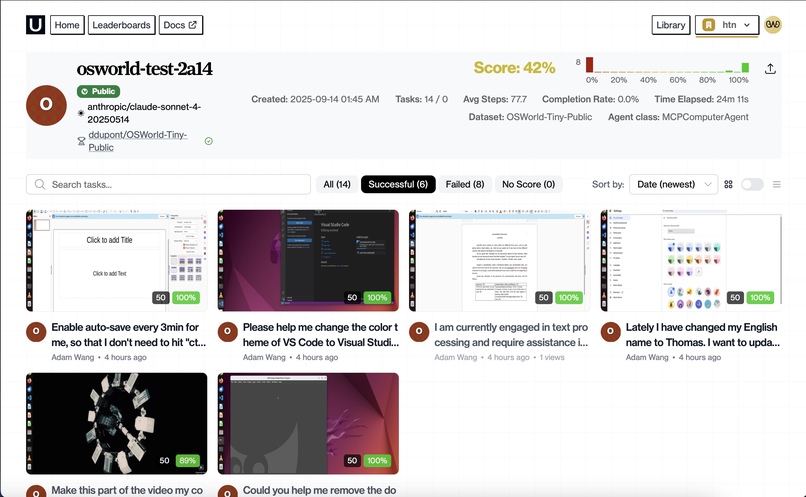
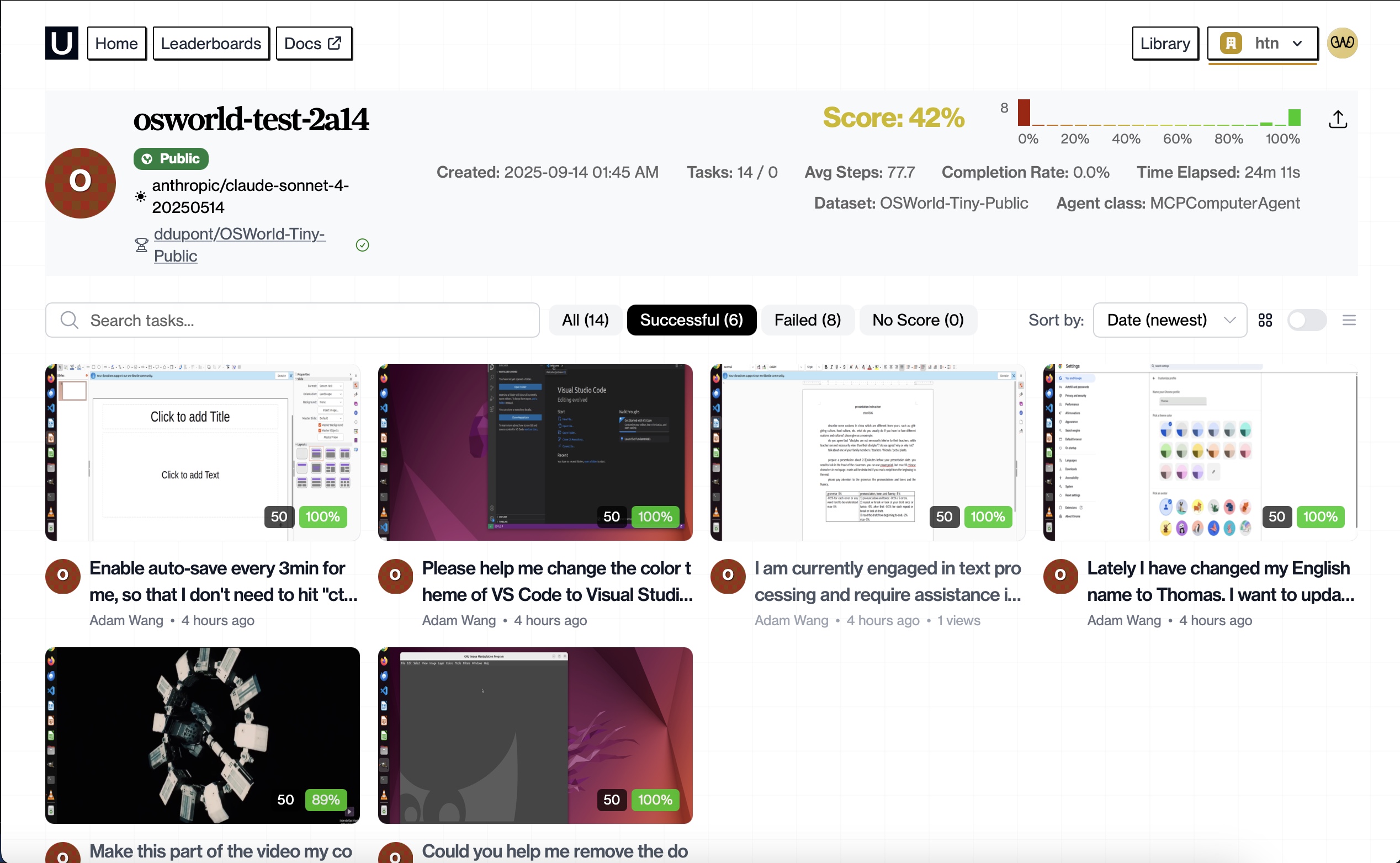
hud dashboard
-
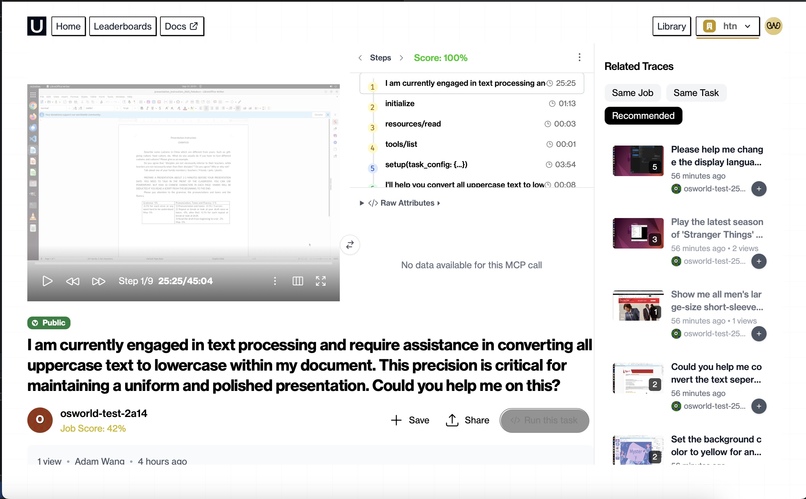
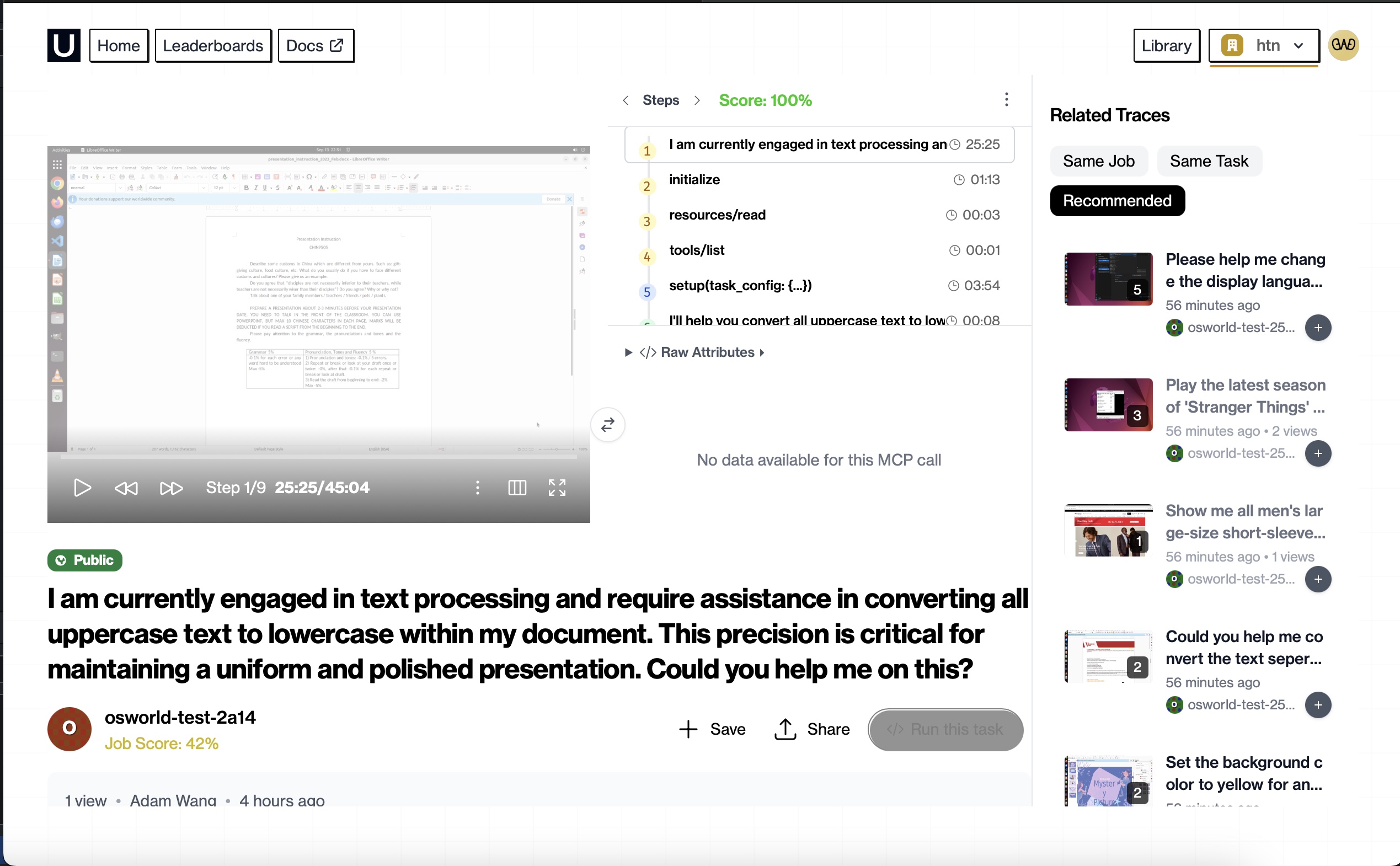
individual task example

Cuala
Project Name: Cuala – General-Purpose Computer-Use Agent
Built With: Cua, HUD, Python
💡 Inspiration
I originally saw Cua as a new technology I’d never explored. Building Cuala gave me the chance to work directly with the Cua team (James) and HUD sponsor (Parth), debugging and fixing issues together during the hackathon. I learned how HUD evaluations work under the hood and how to align agent behavior with benchmark rules.
⚙️ What it does
Cuala is a benchmark-aligned, deterministic computer-use agent:
- Executes tasks step-by-step in desktop/browser environments
- Always verifies via on-screen evidence
- Explicitly handles infeasible cases (e.g., DRM, unsupported language settings)
🔧 How I built it
- Prompt customization: deterministic, verifiable action rules + task-specific refinements
- Callbacks:
ImageRetentionCallback,TrajectorySaverCallbackfor debugging & trace recording - Custom tools: experimented with function tools; the real leverage shows on larger/multi-task datasets (e.g., Excel-heavy suites)
Code: GitHub Repo
HUD Scorecard: 42% — 6/14 Tasks
🧪 Results
- Score: 42% (6/14 tasks successful)
- Several “failed” traces actually show the correct work completed but blocked by submit/evaluation mismatches
- Compared to overfitted agents (which often yield “No Score”), Cuala produces cleaner traces with generalizable logic
🚀 What’s next
- Develop custom agents with
@register_agentfor task families (e.g., office apps) - Create toolkits for Excel/GIMP/VS Code to generalize across multiple datasets
- Explore RL fine-tuning with HUD to reduce step waste
🙌 Acknowledgements
Huge thanks to:
- James (Cua) for guidance on errors, notebook vs. agent usage, and HUD quirks
- Parth (HUD) for quick fixes when I uncovered evaluation bugs mid-hackathon
Their support shaped my learning and helped me push Cuala beyond brittle overfitting.
Built With
- anthropic
- cua
- hud



Log in or sign up for Devpost to join the conversation.