-
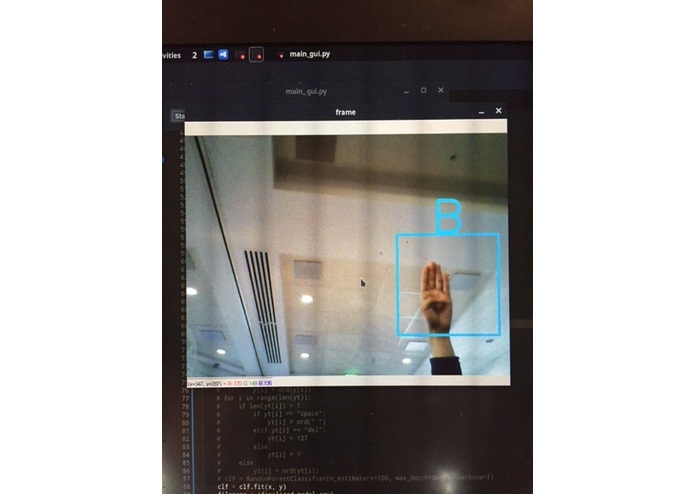
'B' sign made in GUI
-

'K' sign recognized
-

'V' sign recognized
-

'Z' sign recognized
-

Main GUI
-

GUI with webcam
-

Friends
-

Saved Text File







Inspiration
Language is the bond that brings communities together. Having had experience with speech impediments within our group, we understand the many ways being left without a language can isolate an individual. In our project we hope to bridge the language gap between the mute and the general population. With CU Sign one who can only speak through ASL will be able to easily communicate with those who have never signed before.
What it does
CU Sign uses real-time image processing through OpenCV as well as decision forests created with TensorFlow in order to classify ASL letters made by the user. Users open the application and sign to their computer's webcam. When they are done with their message, CU Sign archives their message in the form of a word document, and plays it through their computer's speakers. This allows the user to communicate with people around them who can't understand sign language, both verbally and through text.
How we built it
We built the application in three parallel stages: 1) Word and Image Processing: We used OpenCV and Pillow to both stream and capture images from the computer's webcam. In this system we print precursory results and define the functions space on the computer’s video stream. At the same time we preprocess the stream: cropping, recoloring and formatting the images so they can be fed directly to our decision forest. We also used system dependant voice to text libraries — e-speak for Linux and Mac, and win32 for Windows — to speak the final message back to the user regardless of their prefered os.
2) GUI: Used PyQt5 to build a user interface that allows the user to start and stop recording their messages, and save/play their message transcript. The packages used to generate this simple GUI were QtCore, QtGui, QtWidgets, and OpenCV.
3) Decision Forest: We trained then used a series of decision trees to match the signs shown in the webcam to a repository of over 8000 images showing the alphabet in American Sign Language. A decision tree navigates a range of outputs for the given input (image) by creating pathways for the given values. The forest is a weighted average of decision trees based on accuracy of the trees to help overcome the challenge of overfitting. This entire forest system was designed using TensorFlow.
Challenges we ran into
Neural Network v. Decision Tree: our initial approach to recognizing ASL was to implement a neural net. As we learned, these systems are designed for continuous functions, not the discrete system defined by ASL. Because of this, our neural net was unable to properly identify any of the signs, so we chose to transition to the use of a Decision Forest to define our network.
Overfitting: CU Sign needs to be built around an accurate ASL interpreter. We quickly created a Decision Tree which would work perfectly for our 8700 image data set. Unfortunately, this was an overfit system, when we tried matching to data that was external to the data set, such as our webcam videos, we would have issues getting the correct data. We have changed to a Random Forest Classifier system with randomized initial conditions in an attempt to resolve this issue.
Text to Speech: many of the text to speech functions native to python were never fully converted to Python 3 from 2. This means while there were plenty of libraries online, almost all of them had obsolete function calls, or improper syntax. This created additional difficulty when we attempted to generalize the project, as the solutions we found in Linux, are not available in Windows, adding another level of complexity to the system.
Computational Power: Machine Learning in the natural language domain such as ASL requires large amounts of computational power and powerful GPUs. The original plan was to use AWS to aid the training of the language models, but as the AWS account was not accessible to first time users, we had to resort to training our model on our meager ultrabooks. The restriction on the training greatly reduced our accuracy.
Accomplishments that we're proud of
At the beginning of this Hackathon, most of our group had very little experience with computer programming, especially when it comes to Python as three quarters of the group had never used it extensively before. We quickly ramped up from barely being able to create functions to implementing an in-depth project. We are proud of the general growth of the group. Beyond that, we are proud of the solution itself. We have created a solution to communication barriers that are prevalent in our community, could have a real impact if developed further.
What we learned
We learned how to create this project from the very beginning, from basic function calls, to the installation of Python and its many libraries on both Linux and Windows systems we have made real progress in learning the language.
Beyond general Python, we have learned how to use OpenCV to create and manipulate images, and have gained experience with some of the core foundational concepts of machine learning, and how to create complex systems using TensorFlow. From graphical interfaces, to research on the fundamentals of curve fitting, we have experienced a real range of programming growth in this project.
What's next for CU Sign
CU Sign can be improved by expanding its language library. There are many things that one might want to communicate which simply cannot be transferred by the alphabet alone, adding common words and punctuation marks to the system would allow it to have a larger impact.
The system could also be more generalized with regard to the work setting. A majority of the photos used in the dataset have a plain white background, which causes issues when our webcam is in a different environment. Further training in this regard would allow users to interact with our system more freely.
There is still more that needs to be done when it comes to the machine learning process itself. We still see the effects of overfitting in our system, and we also need to further generalize to allow for symbols that require the use of motion.
Built With
- opencv
- python
- scikit-learn
- tensorflow











Log in or sign up for Devpost to join the conversation.